了解分类指标:评估模型准确性的指南
探索分类指标:评估模型准确性的终极指南

动机
评估指标就像我们用来了解机器学习模型工作情况的测量工具。它们帮助我们比较不同的模型,并找出哪个模型最适用于特定任务。在分类问题领域,有一些常用的指标可以衡量模型的好坏,了解每个指标的细节对于确定适合特定任务的指标变得更容易。
- 这篇来自NVIDIA的AI论文探讨了检索增强与语言模型中的长文本之力:哪个是至高无上的?它们能共存吗?
- (Our new ways of helping to reduce transportation and energy emissions)
- 利用人工智能预防无家可归的住房危机 洛杉矶的一场颠覆性变革
本文中,我们将探讨在分类任务中使用的基本评估指标,并分析哪些情况下某个指标可能比其他指标更相关。
基本术语
在深入了解评估指标之前,了解与分类问题相关的基本术语非常重要。
真实标签:这些是与数据集中的每个示例对应的实际标签。所有评估和预测都与这些数值进行比较。
预测标签:这些是使用机器学习模型对数据集中每个示例预测的类标签。我们使用各种评估指标将这些预测与真实标签进行比较,以判断模型是否能够学习数据中的特征。
现在,让我们只考虑一个二分类问题,以便更容易理解。在数据集中只有两个不同的类时,将真实标签与预测标签进行比较可能会得到以下四种结果,如图所示。
真正:当真实情况也为正时,模型预测为正类标签。这是所需的行为,因为模型可以成功预测为正的标签。
假正:当真实标签为负时,模型预测为正类标签。模型错误地将一个数据样本标记为正类。
假负:对于一个正例,模型预测为负类标签。模型错误地将一个数据样本标记为负类。
真负:同样也是所需的行为。模型正确地识别出一个负样本,对于一个真实标签为0的数据样本进行预测为0。
现在,我们可以在这些术语的基础上理解常见评估指标的工作原理。
准确率
这是评估分类问题模型性能最简单但也最直观的方法。准确率衡量了模型正确预测的标签占总标签数的比例。
因此,准确率可以计算如下:
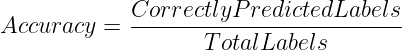
或者
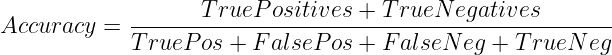
何时使用
- 初始模型评估
由于它的简单性,准确率是广泛使用的指标。在使用特定于问题领域的指标之前,它为我们验证模型是否能够良好学习提供了一个良好的起点。
- 平衡的数据集
准确率仅适用于各个类别标签在数据集中占据相似比例的平衡数据集。如果情况不是如此,并且某个类别标签明显多于其他类别标签,模型可能通过始终预测优势类别来实现高准确率。准确率指标对每个类别的错误预测进行相同的惩罚,因此不适用于不平衡的数据集。
- 当误分类代价相等时
准确率适用于假正或假负出现的情况相对均等的情形。例如,对于情感分析问题,如果我们将一个负面文本分类为正面或将一个正面文本分类为负面,都是同样不好的结果。对于这种情况,准确率是一个很好的指标。
精度
精度关注的是确保我们将所有的正预测都正确预测。 它衡量了实际上是正的预测中有多少是正的。
数学上,它表示为
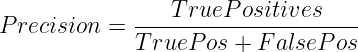
何时使用
- 错误正例的高成本
考虑这样一种情况,我们正在训练一个用于检测癌症的模型。对于我们来说,不要将没有癌症的患者误分类为癌症患者更重要,即误报。当我们做出正面预测时,我们希望有信心,因为错误地将一个人分类为癌症阳性可能会导致不必要的压力和费用。因此,我们非常重视只在实际标签为正的情况下预测出一个正标签。
- 质量优先
再考虑另一种情况,我们正在构建一个将用户查询与数据集匹配的搜索引擎。在这种情况下,我们希望搜索结果与用户查询密切匹配。我们不想返回与用户不相关的任何文档,即误报。因此,我们只对与用户查询密切匹配的文档进行正面预测。我们重视的是质量而不是数量,因为我们更喜欢少量密切相关的结果,而不是可能与用户相关或不相关的大量结果。对于这类情况,我们需要高精度。
召回率
召回率,也称为灵敏度,衡量模型在数据集中能够正确记住正标签的能力。 它衡量了我们的数据集中模型预测为正的正标签的比例。
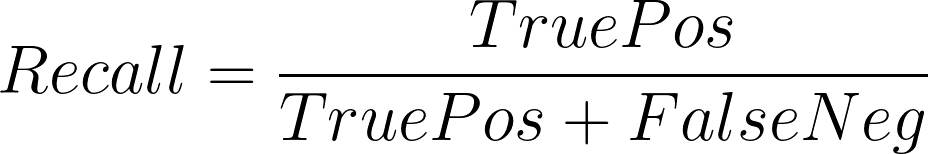
较高的召回率意味着模型在记住具有正标签的数据样本方面表现更好。
何时使用
- 漏报的高成本
当漏报一个正标签可能会产生严重后果时,我们使用召回率。考虑这样一种情况,我们使用机器学习模型来检测信用卡欺诈。在这种情况下,及早发现问题是至关重要的。我们不希望错过一个欺诈交易,因为它可能增加损失。因此,我们将召回率视为精度之上的关键指标,因为将交易误分类为欺诈交易很容易验证,我们可以容忍一些误报,而不能容忍误典。
F1-Score
它是精度和召回率的调和平均值。它惩罚具有精度或召回率之间显著不平衡的模型。
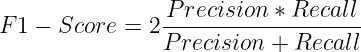
在需要兼顾精度和召回率并在两者之间取得平衡的场景中广泛使用。
何时使用
- 不平衡的数据集
与准确率不同,F1-Score适用于评估不平衡的数据集,因为我们是基于模型回忆少数类别的能力以及总体上保持高精度来评估性能。
- 精度-召回率的权衡
两个指标彼此相反。经验证明,改善一个指标通常会导致另一个指标的降低。F1-Score有助于平衡这两个指标,在既重视召回率又重视精度的情况下非常有用。将这两个指标都考虑在内计算F1-Score,这是用于评估分类模型的常用指标。
要点
我们了解到不同的评估指标有各自的用途。了解这些指标有助于我们选择适合我们任务的正确指标。在现实生活中,重要的不仅仅是拥有优秀的模型,更重要的是拥有与我们业务需求完美匹配的模型。因此,选择正确的指标就像选择正确的工具,确保我们的模型在最重要的地方表现出色。
依然对使用哪个指标感到困惑吗?从准确性开始是一个很好的起步步骤。它提供了对模型性能的基本理解。从那里开始,你可以根据你的具体要求来调整评估指标。或者,考虑使用F1分数,它作为一种多功能指标,可以在精确度和召回率之间取得平衡,使其适用于各种场景。它可以成为你全面分类评估的首选工具。 Muhammad Arham是一位计算机视觉和自然语言处理领域的深度学习工程师。他曾参与部署和优化多个生成型AI应用,这些应用在Vyro.AI全球排行榜上名列前茅。他对构建和优化智能系统的机器学习模型充满兴趣,并坚信不断改进。
[Muhammad Arham](https://www.linkedin.com/in/muhammad-arham-a5b1b1237/)是一位计算机视觉和自然语言处理领域的深度学习工程师。他曾参与部署和优化多个生成型AI应用,这些应用在Vyro.AI全球排行榜上名列前茅。他对构建和优化智能系统的机器学习模型充满兴趣,并坚信不断改进。






