精调大型语言模型(LLM)
LLM
概念性概述与示例Python代码
这是有关实际使用大型语言模型(LLM)系列的第5篇文章。在本文中,我们将讨论如何对预训练的LLM进行微调(FT)。我们首先介绍关键的FT概念和技术,然后以使用Python和Hugging Face的软件生态系统在本地微调模型为例。

在本系列的上一篇文章中,我们看到通过将提示工程集成到我们的Python代码中,我们可以构建实用的LLM应用程序。对于绝大多数LLM用例,这是我推荐的初始方法,因为它所需的资源和技术专长明显较少,同时仍然提供了很多好处。
然而,在某些情况下,仅凭现有的LLM的提示无法满足要求,需要更复杂的解决方案。这就是模型微调的帮助之处。
什么是微调?
微调是对预训练模型进行至少一个内部模型参数(即权重)的训练。在LLM的上下文中,这通常可以将通用基础模型(例如GPT-3)转变为特定用例的专用模型(例如ChatGPT)[1]。
- 生成式人工智能解放:MLOps和LLM部署策略的软件工程师
- Enterra Solutions创始人兼首席执行官Stephen DeAngelis – 访谈系列
- “以人工智能为主导的敏捷产品开发数字化战略”
这种方法的主要优势在于,相比仅依赖受监督训练的模型,模型可以在要求(远远)较少的手动标记示例的情况下获得更好的性能。
尽管严格的自监督基础模型可以通过提示工程在各种任务上展现出令人印象深刻的性能[2],但它们仍然是单词预测器,可能生成的完成并不完全有帮助或准确。例如,让我们比较davinci(基础GPT-3模型)和text-davinci-003(微调模型)的完成。

请注意,基础模型只是试图通过列出一系列问题来完成文本,就像谷歌搜索或作业一样,而微调模型则给出了更有帮助的回答。text-davinci-003使用的微调方法是对齐微调,旨在使LLM的响应更有帮助、真实和无害,但稍后再详细讨论[3,4]。
为什么要进行微调
微调不仅改善了基础模型的性能,而且在训练的一组任务中,较小的(微调)模型通常可以胜过更大(更昂贵)的模型[4]。OpenAI通过他们的第一代“InstructGPT”模型证明了这一点,其中1.3B参数的InstructGPT模型完成在175B参数的GPT-3基础模型上更受青睐,尽管体积小了100倍[4]。
尽管我们现在可能与大多数LLM进行交互的模型不是严格的自监督模型,如GPT-3,但对于提示现有的针对特定用例进行微调模型仍存在一些缺点。
一个重要的缺点是LLM具有有限的上下文窗口。因此,模型在需要大量知识库或领域特定信息的任务上可能表现不佳[1]。通过微调过程,“学习”这些信息的微调模型可以避免这个问题。这也避免了在提示中添加额外上下文的需要,从而可以降低推理成本。
3种微调方式
有3种通用的微调模型方式:自监督学习、监督学习和强化学习。这些方式并不是相互独立的,可以组合使用来对单个模型进行微调。
自监督学习
自监督学习是根据训练数据的内在结构来训练模型。在语言模型中,它通常是给定一个词序列(或更准确地说是标记),预测下一个词(标记)。
虽然现在许多预训练语言模型都是这样开发的,但它也可以用于模型微调。其中一个潜在的用例是开发一个模型,可以在给定一组示例文本的情况下模仿一个人的写作风格。
监督学习
微调模型的下一个,也是可能最流行的方式是通过监督学习。这涉及在特定任务的输入-输出对上训练模型。一个例子是指令微调,旨在提高模型在回答问题或响应用户提示时的性能[1,3]。
监督学习中的关键步骤是策划一个训练数据集。一种简单的方法是创建问题-答案对,并将它们整合到提示模板中[1,3]。例如,问题-答案对:“谁是美国第35任总统? – 约翰·F·肯尼迪”可以粘贴到下面的提示模板中。更多示例提示模板详见参考文献[4]的A.2.1节。
"""请回答以下问题。问题:{问题} 答案:{答案}"""使用提示模板是重要的,因为像GPT-3这样的基础模型本质上是“文档补全器”。也就是说,给定一些文本,模型会生成在该上下文中(统计上)有意义的更多文本。这回溯到这个系列的先前博客和通过提示工程“欺骗”语言模型解决问题的想法。
提示工程-如何欺骗AI解决您的问题
7个提示技巧、Langchain和Python示例代码
towardsdatascience.com
强化学习
最后,可以使用强化学习(RL)来微调模型。强化学习使用奖励模型来指导基础模型的训练。这可以采用许多不同的形式,但基本思想是训练奖励模型对语言模型的完成进行评分,以反映人类标记者的偏好[3,4]。然后可以将奖励模型与强化学习算法(例如Proximal Policy Optimization(PPO))结合使用,进一步微调预训练模型。
强化学习可以用于模型微调的一个示例是OpenAI的InstructGPT模型,它是通过3个关键步骤开发的[4]。
- 生成高质量的提示-响应对,并使用监督学习微调预训练模型(约13,000个训练提示)。注意:也可以(或者)直接使用预训练模型跳过第2步[3]。
- 使用微调模型生成完成,并让人工标记者根据其偏好对响应进行排名。使用这些偏好来训练奖励模型(约33,000个训练提示)。
- 使用奖励模型和强化学习算法(例如PPO)进一步微调模型(约31,000个训练提示)。
虽然上述策略通常会导致LLM的完成结果相对于基础模型更受偏好,但也可能以在某些任务的子集中性能下降的代价为代价。这种性能下降也被称为对齐损耗[3,4]。
监督微调步骤(高级)
正如我们上面所看到的,有许多方法可以对现有的语言模型进行微调。然而,在本文的剩余部分中,我们将重点关注通过监督学习进行的微调。下面是一个关于监督模型微调的高级流程 [1]。
- 选择微调任务(例如摘要、问答、文本分类)
- 准备训练数据集 即创建(100-10k)个输入-输出对并预处理数据(即分词、截断和填充文本)。
- 选择基础模型(尝试不同的模型并选择在所需任务上表现最好的模型)。
- 通过监督学习微调模型
- 评估模型性能
虽然这些步骤中的每一步都可以成为一篇文章,但我想重点关注第4步,并讨论如何训练微调模型。
参数训练的三种选择
当涉及到对具有大约100M-100B参数的模型进行微调时,我们需要考虑计算成本。为此,一个重要的问题是——我们应该(重新)训练哪些参数?
在这个庞大的参数群中,我们有无数选择可以进行训练。在这里,我将重点介绍三个通用选项供选择。
选项1:重新训练所有参数
第一个选项是训练所有内部模型参数(称为完全参数调整)[3]。虽然这个选项很简单(概念上),但计算成本最高。此外,完全参数调整的已知问题是灾难性遗忘现象。这是指模型在初始训练中“学到”的有用信息被“遗忘”的现象[3]。
我们可以通过冻结大部分模型参数来缓解选项1的缺点,这使我们进入了选项2。
选项2:迁移学习
迁移学习(TL)的核心思想是在将模型应用于新任务时保留模型在过去训练中学到的有用表示/特征。这通常包括放弃神经网络(NN)的“头部”,并用新的头部替换它(例如,添加具有随机权重的新层)。注意:NN的头部包括将模型的内部表示转换为输出值的最后几层。
虽然保留大部分参数可以减少训练LLM的巨大计算成本,但迁移学习可能并不一定解决灾难性遗忘的问题。为了更好地处理这两个问题,我们可以转向一组不同的方法。
选项3:参数高效微调(PEFT)
PEFT涉及使用相对较少的可训练参数扩充基础模型。这样做的关键结果是,与完全参数调整相比,它展示了与之相当的性能,但计算和存储成本仅占极小一部分[5]。
PEFT包含一系列技术,其中之一是流行的LoRA(Low-Rank Adaptation)方法[6]。LoRA背后的基本思想是选择一个现有模型中的一部分层,并根据以下方程修改它们的权重。
![显示如何使用LoRA进行微调的权重矩阵修改的方程式[6]。作者提供的图像。](https://miro.medium.com/v2/resize:fit:640/format:webp/1*GmCISYhd-JLqHNEvAQU1tQ.png)
其中 h() = 将要调整的隐藏层,x = h() 的输入,W₀ = h 的原始权重矩阵,ΔW = 注入到 h中的可训练参数矩阵。ΔW 根据 ΔW=BA 进行分解,其中 ΔW 是一个 d×k 矩阵,B 是一个 d×r 矩阵,A 是一个 r×k 矩阵。r 是 ΔW 的假定“内在秩”(可以小到 1 或 2)[6]。
对于所有的数学,我们很抱歉,但是关键点是 W₀ 中的 (d * k) 权重被冻结,因此不参与优化。相反,构成矩阵 B 和 A 的 ((d * r) + (r * k)) 权重是唯一需要训练的。
为了了解效率的提高,我们假设 d=1000,k=1000,r=2,可训练参数的数量从 1,000,000 减少到 4,000。在实践中,LoRA 论文的作者引用了与完全参数调整 [6] 相比,使用 LoRA 微调 GPT-3 可减少参数检查点大小的10,000倍。
为了使这更具体化,让我们看看如何使用 LoRA 完成对语言模型的高效微调,以便在个人计算机上运行。
示例代码:使用 LoRA 进行语言模型微调
在这个示例中,我们将使用 Hugging Face 生态系统对语言模型进行微调,将文本分类为“正面”或“负面”。在这里,我们使用 distilbert-base-uncased 进行微调,这是一个基于 BERT 的约 70M 参数模型。由于该基础模型是用于语言建模而不是分类的,我们使用迁移学习将基础模型的头部替换为分类头部。此外,我们使用LoRA进行高效的模型微调,以便在我的 Mac Mini (M1 芯片,16GB 内存) 上在合理的时间内运行(约 20 分钟)。
代码以及 conda 环境文件可在 GitHub 仓库上找到。最终的模型和数据集[7]可以在 Hugging Face 上找到。
YouTube-Blog/LLMs/fine-tuning at main · ShawhinT/YouTube-Blog
Codes to complement YouTube videos and blog posts on VoAGI. – YouTube-Blog/LLMs/fine-tuning at main ·…
github.com
导入
我们首先导入一些有用的库和模块。Datasets、transformers、peft 和 evaluate 都是 Hugging Face(HF)的库。
from datasets import load_dataset, DatasetDict, Datasetfrom transformers import ( AutoTokenizer, AutoConfig, AutoModelForSequenceClassification, DataCollatorWithPadding, TrainingArguments, Trainer)from peft import PeftModel, PeftConfig, get_peft_model, LoraConfigimport evaluateimport torchimport numpy as np基础模型
接下来,我们加载基础模型。这里的基础模型是一个相对较小的模型,但还有其他几个(更大)的模型可以使用(例如 roberta-base、llama2、gpt2)。完整列表可以在这里找到。
model_checkpoint = 'distilbert-base-uncased'# 定义标签映射id2label = {0: "Negative", 1: "Positive"}label2id = {"Negative":0, "Positive":1}# 从 model_checkpoint 生成分类模型model = AutoModelForSequenceClassification.from_pretrained( model_checkpoint, num_labels=2, id2label=id2label, label2id=label2id)加载数据
然后,我们可以从 HF 的数据集库中加载训练和验证数据。这是一个包含 2000 个电影评论(1000 个用于训练,1000 个用于验证)的数据集,其中的二进制标签指示评论是正面的(还是不是)。
# 加载数据集dataset = load_dataset("shawhin/imdb-truncated")dataset# dataset = # DatasetDict({# train: Dataset({# features: ['label', 'text'],# num_rows: 1000# })# validation: Dataset({# features: ['label', 'text'],# num_rows: 1000# })# }) 预处理数据
接下来,我们需要对数据进行预处理,以便用于训练。这包括使用分词器将文本转换为基模型能够理解的整数表示。
# 创建分词器tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, add_prefix_space=True)要将分词器应用于数据集,我们使用.map()方法。该方法接受一个自定义函数,指定文本应如何预处理。在这种情况下,该函数被称为tokenize_function()。除了将文本转换为整数,该函数还会截断整数序列,使其不超过512个数字,以符合基模型的最大输入长度。
# 创建分词函数def tokenize_function(examples): # 提取文本 text = examples["text"] # 分词和截断文本 tokenizer.truncation_side = "left" tokenized_inputs = tokenizer( text, return_tensors="np", truncation=True, max_length=512 ) return tokenized_inputs# 如果不存在pad token,则添加pad tokenif tokenizer.pad_token is None: tokenizer.add_special_tokens({'pad_token': '[PAD]'}) model.resize_token_embeddings(len(tokenizer))# 对训练和验证数据集进行分词tokenized_dataset = dataset.map(tokenize_function, batched=True)tokenized_dataset# tokenized_dataset = # DatasetDict({# train: Dataset({# features: ['label', 'text', 'input_ids', 'attention_mask'],# num_rows: 1000# })# validation: Dataset({# features: ['label', 'text', 'input_ids', 'attention_mask'],# num_rows: 1000# })# })此时,我们还可以创建一个数据整理器,它将动态地对每个批次中的示例进行填充,以使它们的长度相同。这比在整个数据集中将所有示例填充为相等长度更具有计算效率。
# 创建数据整理器data_collator = DataCollatorWithPadding(tokenizer=tokenizer)评估指标
我们可以通过自定义函数来定义我们如何评估微调的模型。在这里,我们定义了compute_metrics()函数来计算模型的准确性。
# 导入准确度评估指标accuracy = evaluate.load("accuracy")# 定义一个评估函数,稍后传递给训练器def compute_metrics(p): predictions, labels = p predictions = np.argmax(predictions, axis=1) return {"accuracy": accuracy.compute(predictions=predictions, references=labels)}未经训练的模型性能
在训练模型之前,我们可以评估基模型和随机初始化分类头部在一些示例输入上的性能。
# 定义示例列表text_list = ["It was good.", "Not a fan, don't recommed.", "Better than the first one.", "This is not worth watching even once.", "This one is a pass."]print("未经训练的模型预测:")print("----------------------------")for text in text_list: # 分词文本 inputs = tokenizer.encode(text, return_tensors="pt") # 计算logits logits = model(inputs).logits # 将logits转换为标签 predictions = torch.argmax(logits) print(text + " - " + id2label[predictions.tolist()])# 输出:# 未经训练的模型预测:# ----------------------------# It was good. - Negative# Not a fan, don't recommed. - Negative# Better than the first one. - Negative# This is not worth watching even once. - Negative# This one is a pass. - Negative正如预期的那样,模型的性能等同于随机猜测。让我们看看如何通过微调来改善这个问题。
使用LoRA进行微调
要使用LoRA进行微调,我们首先需要一个配置文件。这个配置文件设置了LoRA算法的所有参数。有关详细信息,请参见代码块中的注释。
peft_config = LoraConfig(task_type="SEQ_CLS", # 序列分类 r=4, # 可训练权重矩阵的内在秩 lora_alpha=32, # 这类似于学习率 lora_dropout=0.01, # 丢弃的概率 target_modules = ['q_lin']) # 我们仅将LoRA应用于查询层然后,我们可以创建一个可以通过PEFT进行训练的模型的新版本。请注意,可训练参数的规模减小了约100倍。
model = get_peft_model(model, peft_config)model.print_trainable_parameters()# trainable params: 1,221,124 || all params: 67,584,004 || trainable%: 1.8068239934408148接下来,我们为模型训练定义超参数。
# 超参数lr = 1e-3 # 优化步长batch_size = 4 # 每次优化步骤处理的示例数量num_epochs = 10 # 模型对训练数据运行的次数# 定义训练参数straining_args = TrainingArguments( output_dir= model_checkpoint + "-lora-text-classification", learning_rate=lr, per_device_train_batch_size=batch_size, per_device_eval_batch_size=batch_size, num_train_epochs=num_epochs, weight_decay=0.01, evaluation_strategy="epoch", save_strategy="epoch", load_best_model_at_end=True,)最后,我们创建一个trainer()对象并对模型进行微调!
# 创建trainer对象trainer = Trainer( model=model, # 我们的peft模型 args=training_args, # 超参数 train_dataset=tokenized_dataset["train"], # 训练数据 eval_dataset=tokenized_dataset["validation"], # 验证数据 tokenizer=tokenizer, # 定义tokenizer data_collator=data_collator, # 这将动态填充每个批次中的示例,使它们具有相等的长度 compute_metrics=compute_metrics, # 使用之前的compute_metrics()函数评估模型)# 训练模型trainer.train()上面的代码将在训练过程中生成以下指标表格。
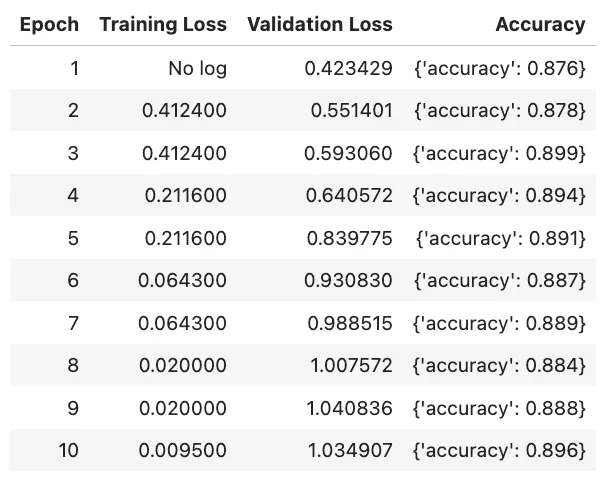
训练模型性能
为了查看模型性能的改善情况,让我们将其应用于之前的5个示例。
model.to('mps') # 移动到mps以适应Mac(也可以选择使用'cpu')print("训练模型预测:")print("--------------------------")for text in text_list: inputs = tokenizer.encode(text, return_tensors="pt").to("mps") # 移动到mps以适应Mac(也可以选择使用'cpu') logits = model(inputs).logits predictions = torch.max(logits,1).indices print(text + " - " + id2label[predictions.tolist()[0]])# 输出:# 训练模型预测:# ----------------------------# It was good. - Positive# Not a fan, don't recommed. - Negative# Better than the first one. - Positive# This is not worth watching even once. - Negative# This one is a pass. - Positive # this one is tricky通过微调,经过训练的模型在以上代码中的示例中准确分类了除一个之外的所有示例。这与我们在训练过程中看到的约90%的准确度指标相一致。
链接:代码仓库 | 模型 | 数据集
结论
尽管微调现有模型需要更多的计算资源和技术专业知识,但(较小的)微调模型可以在特定用例中胜过(较大的)预训练基础模型,即使使用了巧妙的提示工程策略。此外,随着所有开源LLM资源的可用性,微调模型以适应自定义应用程序从未如此简单。
本系列的下一篇(也是最后一篇)文章将进一步介绍如何从头开始训练语言模型。
👉 更多关于LLMs的内容:介绍 | OpenAI API | Hugging Face Transformers | Prompt Engineering
资源
联系方式:我的网站 | 预约通话 | 向我提问
社交媒体:YouTube 🎥 | LinkedIn | Twitter
支持:给我买杯咖啡 ☕️
数据创业者
面向数据领域创业者的社区。👉 加入Discord!
VoAGI.com
[1] Deeplearning.ai 微调大型语言模型简短课程: https://www.deeplearning.ai/short-courses/finetuning-large-language-models/
[2] arXiv:2005.14165 [cs.CL] (GPT-3 论文)
[3] arXiv:2303.18223 [cs.CL] (LLM 调查)
[4] arXiv:2203.02155 [cs.CL] (InstructGPT 论文)
[5] 🤗 PEFT: 低资源硬件上十亿规模模型的参数高效微调: https://huggingface.co/blog/peft
[6] arXiv:2106.09685 [cs.CL] (LoRA 论文)
[7] 原始数据集来源 — Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. 2011. Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150, Portland, Oregon, USA. Association for Computational Linguistics.





