Fast.AI深度学习课程中的7个教训
7 Lessons from Fast.AI Deep Learning Course
我从最受欢迎的深度学习课程中学到了什么
我最近完成了Fast.AI的实用深度学习课程。我之前参加过许多机器学习课程,所以我可以进行比较。这门课程绝对是最实用和启发人的之一。因此,我想与您分享我从中得到的主要收获。
关于这门课程
Fast.AI课程由Fast.AI的创始研究员Jeremy Howard领导。他曾经在Kaggle排行榜上位居第一。因此,您绝对可以信任他在机器学习和深度学习方面的专业知识。
该课程涵盖了深度学习和神经网络的基础知识,并解释了决策树算法。当前版本是2022年的,所以我认为自之前在TDS上的评论以来,内容已经发生了变化。
该课程适合有一些编程经验的人。大多数情况下,使用代码示例而不是公式。我必须承认,对于我来说,写了很多代码之后,理解代码更容易,尽管我拥有数学硕士学位。
该课程的另一个好处是自上而下的方法。您从工作的机器学习模型开始。例如,在课程的第二周,我制作了我的第一个基于深度学习的应用程序。这是一个可以检测我最喜欢的狗品种的图像分类器。然后,在接下来的几周里,您会更深入地了解它是如何工作的。
让我们继续谈谈我从这门课程中得到的主要收获。
第一课:理解深度学习所需的数学知识
让我们从简单的开始。我保证接下来的收获会更加有深度。
我认为谈论这个很重要,因为很多人对深度学习感到害怕。深度学习被认为是火箭科学,但它基于一些您可以在一天内学会的数学概念。
神经网络是线性函数和激活的组合。这是一个线性函数。
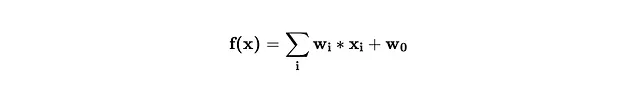
由于线性函数的组合仍然是线性的,我们需要添加非线性的激活函数。
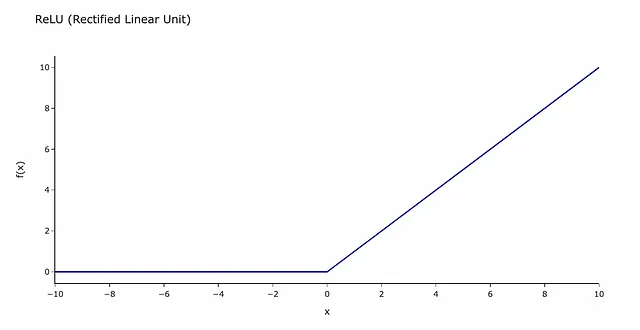
最常见的激活函数是ReLU(修正线性单元)。听起来可能很可怕,但实际上,它只是一个如下所示的函数。
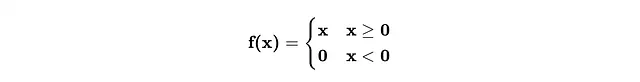
您可以将其视为信号需要克服的障碍。如果信号低于阈值(在我们的例子中为0),其信息将不会传递到神经网络的下一层。
还使用了其他几个数学概念:
- SGD(随机梯度下降) – 一种基于梯度计算的优化方法。您可以阅读一篇文章以了解它的高层次理解。
- 矩阵乘法有助于批量计算更快。也有一篇很好的文章介绍它。
如果您想了解所有细节,请参阅Fast.AI课程中关于神经网络基础的课程。
第二课:如何清洗数据
我们习惯于从清理数据开始进行分析。我们都听过许多次“垃圾进,垃圾出”的口头禅。令人惊讶的是,先拟合一个模型,然后使用它来清洗数据可能会更有效。
您可以训练一个简单的模型,然后查看损失最高的案例以找出潜在问题。在我之前的文章中,这种方法帮助我发现了错误标记的图像。
在一个小时内构建你的第一个深度学习应用
使用HuggingFace Spaces和Gradio部署图像分类模型
towardsdatascience.com
第3课:如何选择计算机视觉模型
现在有很多预训练模型。例如,PyTorch图像模型(timm)有1242个模型。
import timmpretrained_models = timm.list_models(pretrained=True)print(len(pretrained_models))print(pretrained_models[:5])1242['bat_resnext26ts.ch_in1k', 'beit_base_patch16_224.in22k_ft_in22k', 'beit_base_patch16_224.in22k_ft_in22k_in1k', 'beit_base_patch16_384.in22k_ft_in22k_in1k', 'beit_large_patch16_224.in22k_ft_in22k']作为初学者,你通常会对很多选择感到困惑。幸运的是,有一个方便的工具可以帮助你选择深度学习架构。
这个图显示了推理时间(处理一张图片所需的时间)和Imagenet准确性之间的关系。

正如你所预期的,速度和准确性之间存在权衡,所以你应该决定哪个更重要。这高度取决于你的任务。你需要你的模型更快还是更准确?
最好从一个小模型开始并进行迭代。经验法则是在第一天创建第一个模型。所以,你可以使用简单的模型如Resnet18或Resnet34来尝试不同的数据增强技术或外部数据集。由于你使用的是简单模型,迭代速度会很快。当你找到最佳版本时,你可以转向更慢的模型架构。
Jeremy Howard的建议:“尝试复杂的架构是我做的最后一件事”。
第4课:如何在Kaggle上训练大型模型
许多初学者在Kaggle笔记本上使用机器学习。Kaggle的GPU内存有限,所以在使用大型模型时可能会出现内存不足的情况。
有一个有用的技巧可以解决这个问题,叫做Gradient Accumulation(梯度累积)。使用Gradient Accumulation,我们不会在每个批次后更新权重,而是将K个批次的梯度求和。然后,我们使用这个累积的梯度来更新模型权重,总批次数为K * batch_size,因此每次迭代的批次大小要小K倍。
梯度累积在数学上是完全相同的,除非模型架构中使用了批量归一化。例如,convnext不使用批量归一化,所以没有任何区别。
使用这种方法,我们使用的内存显著减少。这意味着不需要购买巨大的GPU —— 你甚至可以在笔记本电脑上适应模型。
你可以在Kaggle上找到完整的示例。
第5课:什么机器学习算法要使用
现在有很多不同的机器学习技术。例如,scikit-learn文档中至少有十几种监督学习方法。
Jeremy Howard建议只专注于几种基本技术:
- 如果您有结构化数据,您应该从决策树集合(随机森林或梯度提升算法)开始。
- 对于非结构化数据(如自然文本、音频、视频或图像),最好的解决方案是多层神经网络。
神经网络也适用于结构化数据,但是决策树通常更容易使用:
- 您可以更快地训练决策树集合。
- 它们具有较少的参数需要调整。
- 您不需要特殊的GPU来训练它们。
- 此外,决策树通常更容易解释和理解,可以了解为什么对于每个对象会得到这样的结果,例如哪些特征是最强的预测因子,哪些特征可以安全地忽略。
如果我们比较决策树集合,随机森林更容易使用(因为几乎不可能过拟合)。然而,梯度提升通常可以给出稍微更好的结果。
第6课:方便的Python函数
尽管我已经使用Python和Pandas将近十年了,但我也发现了一些有用的Pandas技巧。
著名的泰坦尼克号数据集被用来展示Pandas的强大功能。让我们来看一下。
第一个例子向我们展示了如何将一列转换为字符串,获取第一个字母,并使用字典进行转换。请注意,如果字典中没有提到某个值,则返回NaN。
# 我通常的方法decks_dict = {'A': 'ABC', 'B': 'ABC', 'C': 'ABC', 'D': 'DE', 'E': 'DE', 'F': 'FG', 'G': 'FG'}df['Deck'] = df.Cabin.map( lambda x: decks_dict.get(str(x)[0]))# 课程中的版本df['Deck'] = df.Cabin.str[0].map(dict(A="ABC", B="ABC", C="ABC", D="DE", E="DE", F="FG", G="FG"))下一个例子展示了如何使用transform函数计算频率。与我通常使用的合并方法相比,这个版本更简洁。
# 我通常的方法df = df.merge( df.groupby('Ticket', as_index = False).PassengerId.count()\ .rename(columns = {'PassengerId': 'TicketFreq'}))# 课程中的版本df['TicketFreq'] = df.groupby('Ticket')['Ticket'].transform('count')最后一个例子是关于如何解析标题的最复杂的例子。
# 我通常的方法df['Title'] = df.Name.map(lambda x: x.split(', ')[1].split('.')[0])df['Title'] = df.Title.map( lambda x: x if x in ('Mr', 'Miss', 'Mrs', 'Master') else None)# 课程中的版本 df['Title'] = df.Name.str.split(', ', expand=True)[1]\ .str.split('.', expand=True)[0]df['Title'] = df.Title.map(dict(Mr="Mr",Miss="Miss",Mrs="Mrs",Master="Master"))值得看一下第一部分的df,以了解它的工作原理。您可以执行代码:df.Name.str.split(‘, ‘, expand=True),并查看一个数据框,其中名称按逗号分隔在两列中。

然后,我们选择第1列,并基于句点进行类似的分割。第二行只是用NaN替换了所有不等于Mr,Mrs,Miss或Master的情况。
坦率地说,对于最后一个案例,我会继续使用我的通常方法,因为我认为它更容易理解。
第7课:机器学习技巧
在这门课程中提到了许多技巧和有用的技术或工具。以下是我发现的一些有用的技巧。
多目标模型
令人惊讶的是,将另一个目标添加到神经网络中可能会帮助您提高模型的质量。
Jeremy展示了一个用于Paddy Disease Classification竞赛的多目标模型的示例。该竞赛的目标是通过照片预测水稻病害。我们不仅可以预测疾病,还可以预测水稻品种,这可能有助于模型学习有价值的特征。对于预测水稻品种有用的特征也可能有助于疾病检测。
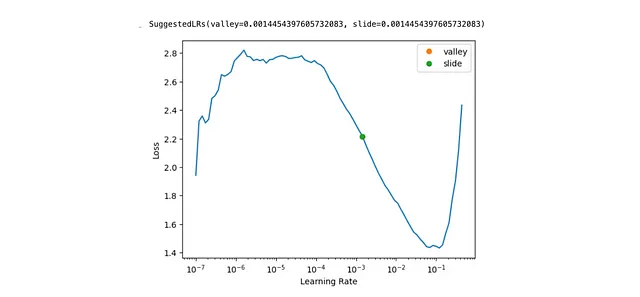
寻找最佳学习率
学习率定义了每次SGD(随机梯度下降)迭代的步长。如果学习率太小,模型的拟合速度会很慢。如果学习率太高,模型可能永远无法收敛到最优解。因此,选择正确的学习率非常重要。
Fast.AI提供了一个工具,只需一行代码learn.lr_find(suggest_funcs=(valley, slide))即可帮助您找到最佳学习率。
测试时增强
增强是对图像进行的一些改变(例如,对比度改进、旋转或裁剪)。在训练过程中,常常使用增强来在每个epoch中获得略有不同的图像。但我们也可以在推理阶段使用增强。这种技术称为测试时增强。

这种方法非常简单。我们使用增强生成每个图像的几个版本,并对每个版本进行预测。然后,使用最大值或平均值计算聚合结果。这个想法类似于装袋法(Bagging)。
丰富日期信息
如果您的数据集中包含日期信息,您可以从中获取更多的信息。例如,不仅仅是2023–09–01,您可以查看各个特征:月份、星期几、年份等。
Fast.AI提供了一个名为add_datepart的函数,因此您不需要自己实现它。
未解答的问题:为什么使用sigmoid函数?
在这门课程中,我只有一个理论问题没有被详细讲解。与许多其他机器学习课程一样,没有解释为什么我们使用sigmoid函数而不是其他函数将线性模型的输出转换为概率。幸运的是,有一篇长篇阅读可以找到所有答案。
总而言之,Fast.AI课程有很多隐藏的宝藏,即使您在数据科学方面有经验,也能给您一些思考的食粮。因此,我肯定建议您去听听。
非常感谢您阅读本文。希望对您有所启发。如果您有任何后续问题或评论,请在评论区留言。






