理解Flash-Attention和Flash-Attention-2:扩展语言模型的上下文长度的路径
Understanding Flash-Attention and Flash-Attention-2 Extending the Context Length of Language Models
这两种方法在LLMs中处理更长文本序列方面提供了重大改进。

我最近开始了一个以人工智能为重点的教育通讯,已经有超过160,000个订阅者。TheSequence是一份无装逼的(意思是没有炒作、没有新闻等)面向机器学习的通讯,只需5分钟阅读。目标是让您及时了解机器学习项目、研究论文和概念。请订阅以下以试一试:
TheSequence | Jesus Rodriguez | Substack
机器学习、人工智能和数据发展的最佳信息源…
thesequence.substack.com
扩展大型语言模型(LLMs)的上下文仍然是扩展用例范围的最大挑战之一。最近几个月,我们看到像Anthropic或OpenAI这样的供应商将其模型的上下文长度推至新的高度。这一趋势可能会继续下去,但可能需要一些研究突破。斯坦福大学最近发表的一项最有趣的研究成果是在这一领域。这个名为FlashAttention的新技术迅速被采用为增加LLMs上下文的主要机制之一。FlashAttention的第二个版本FlashAttention-2最近发表。在本文中,我想回顾一下两个版本的基本原理。
FashAttention v1
在尖端算法领域,FlashAttention成为一个改变游戏规则的算法。这个算法不仅重新排序了注意力计算,还利用了如平铺和重计算等经典技术,以实现速度显著提升和内存使用量大幅减少的效果。这种转变是具有变革性的,与序列长度相关的内存占用从二次降到了线性。对于大多数情况来说,FlashAttention表现得相当不错,但是需要注意的是,它并没有针对长度异常长的序列进行优化,其中并行性不足。
在训练大型Transformer处理扩展序列的挑战时,使用现代并行技术,如数据并行、流水线并行和张量并行是关键。这些方法将数据和模型分配到多个GPU上,可能会导致极小的批量大小(使用流水线并行时批量大小为1)和适度数量的头部,通常在8到12之间(使用张量并行时)。正是这种情况,FlashAttention试图进行优化。
对于每个注意力头,FlashAttention采用了经典的平铺技术来最小化内存读写。它将查询、键和值的块从GPU的高速缓存(快速缓存)传输到HBM(主存储器)。在对这个块进行注意力计算后,它将输出写回到HBM。这种内存读写减少可以显著提速,在大多数用例中,速度通常是原始速度的2到4倍。
FlashAttention的初始版本尝试了批量大小和头部数量上的并行化。熟悉CUDA编程的人会欣赏到每个注意力头都部署了一个线程块来处理,总共有batch_size * num_heads个线程块。每个线程块都经过精心调度,以在流多处理器(SM)上运行,A100 GPU拥有108个这样的SM。当batch_size * num_heads达到相当大的值时,比如大于或等于80时,这种调度能够有效利用几乎所有GPU的计算资源。
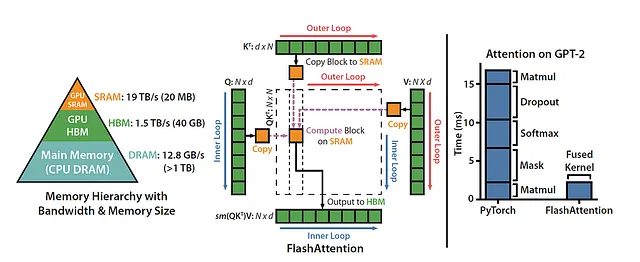
然而,当处理长度较长的序列时,通常会关联到较小的批量大小或有限数量的头部,FlashAttention采取了一种不同的方法。它现在在序列长度维度上引入了并行化,从而实现了针对这个特定领域的显著速度增强。
谈到反向传播,FlashAttention选择了稍微改变的并行化策略。每个工作器负责注意力矩阵中的一块列。这些工作器协作和通信,通过原子操作聚合与查询相关的梯度。有趣的是,FlashAttention发现在这种情况下,按列进行并行化优于按行进行并行化。工作器之间减少的通信被证明是关键,因为按列并行化需要聚合查询的梯度,而按行并行化需要聚合键和值的梯度。

FlashAttention-2
在FlashAttention-2中,斯坦福团队对初始版本进行了精心改进,重点是在算法中最小化非矩阵乘法FLOPs。这个调整在现代GPU时代具有深远的意义,现代GPU配备了像Nvidia的张量核心这样的专门计算单元,大大加速了矩阵乘法(matmul)。
FlashAttention-2还重新审视了其所依赖的在线softmax技术。目标是在保持输出完整性的同时,简化重新缩放操作、边界检查和因果遮罩。
在初始版本中,FlashAttention在批量大小和头数上都实现了并行性。在这里,每个注意力头由一个专用的线程块处理,总共有(批量大小*头数)个线程块。这些线程块被有效地调度到流处理多处理器(SMs)上,具有108个这样的SMs的A100 GPU是一个很好的例子。当线程块的总数很大时,这种调度策略最有效,通常超过80个,因为它允许最佳利用GPU的计算资源。
为了改进涉及长度较长的序列的情况,这些情况通常伴随着较小的批量大小或有限的头数,FlashAttention-2引入了另一个维度的并行性——对序列长度的并行化。这种策略的调整在特定的情境中显著提高了速度。
即使在每个线程块内部,FlashAttention-2也必须在不同的warp之间合理分配工作负载,warp代表以协同方式操作的32个线程的组。通常,每个线程块使用4个或8个warp,并且分区方案如下所述。在FlashAttention-2中,这种分区方法得到了改进,旨在减少不同warp之间的同步和通信,从而减少共享内存的读写。
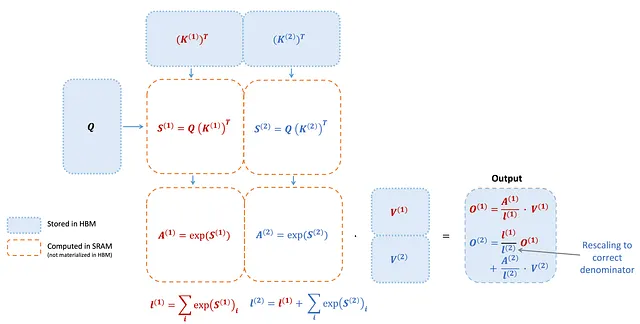
在之前的配置中,FlashAttention将K和V划分为4个warp,同时保持Q对所有warp的可访问性,称为“切片-K”方案。然而,这种方法存在效率低下的问题,因为所有warp都需要将其中间结果写入共享内存,进行同步,然后聚合这些结果。这些共享内存操作对FlashAttention的前向传递产生了性能瓶颈。
在FlashAttention-2中,策略采取了不同的路径。它现在将Q分配给4个warp,同时确保K和V对所有warp都是可访问的。每个warp进行矩阵乘法以获取Q K^T的一个切片,然后简单地将其与共享切片的V相乘,得到各自的输出切片。这种安排消除了跨warp的通信的需要。共享内存读写的减少转化为显著的加速。
早期版本的FlashAttention支持最多128个头的维度,对于大多数模型来说足够了,但也有一些模型无法使用。FlashAttention-2将其支持扩展到最多256个头的维度,适应像GPT-J、CodeGen、CodeGen2和StableDiffusion 1.x这样的模型。这些模型现在可以利用FlashAttention-2来提高速度和内存效率。
此外,FlashAttention-2还引入了对多查询注意力(MQA)和分组查询注意力(GQA)的支持。这些是特殊注意力变体,其中多个查询头同时关注相同的键和值头。这种策略旨在减少推理过程中的KV缓存大小,从而最终实现显著提高的推理吞吐量。
改进
斯坦福团队对FlashAttention-2在不同基准测试中进行了评估,相比初始版本和其他替代方案,取得了显著的改进。测试包括注意力架构的不同变体,结果非常显著。
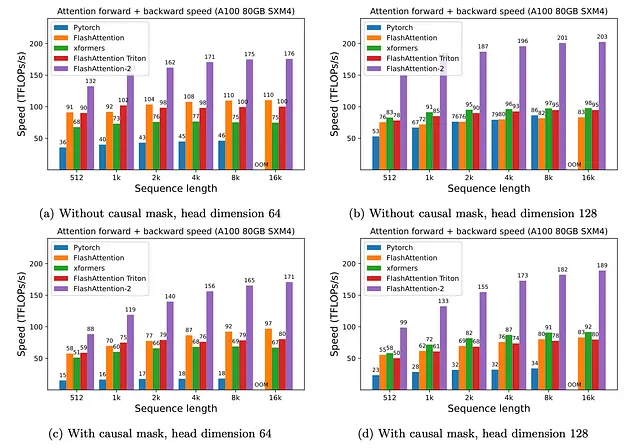
FlashAttention和FlashAttention-2是扩展LLMs背景的两种基础技术。这项研究代表了该领域最重大的研究突破之一,并影响了能够增加LLMs容量的新方法。






