‘一个LLM如何生成文本?’
LLM生成文本的方法
本文不讨论变压器或如何训练大型语言模型。相反,我们将专注于使用预训练模型。
所有代码都在Github和Colab上提供
让我们来看一下文本生成的概述。

- 输入文本传递给一个分词器,该分词器生成token_id输出,其中每个token_id被分配为唯一的数值表示。
- 分词化的输入文本传递给预训练模型的编码器部分。编码器处理输入并生成表示输入含义和上下文的特征表示。编码器是在大量数据上进行训练的,我们从中受益。
- 解码器接收编码器的特征表示,并根据上下文逐个生成新文本的token。它使用先前生成的token来创建新的token。
今天,我们将专注于第三步——解码和生成文本。如果您对前两步感兴趣,请在下方评论。我也会考虑涵盖这些主题。
解码输出
现在让我们深入一些。假设我们想要生成短语“巴黎是城市的……”的延续部分。编码器(我们将使用Bloom-560m模型(代码链接在评论中))发送我们拥有的所有token的logits(如果您不知道logits是什么,请将它们视为分数),可以使用softmax函数将其转换为选择生成的token的概率。

如果您查看前5个输出token,它们都是合理的。我们可以生成以下听起来合理的短语:
- 巴黎是城市的爱情之都。
- 巴黎是城市从不入睡。
- 巴黎是城市艺术和文化蓬勃发展的地方。
- 巴黎是城市拥有标志性的地标。
- 巴黎是城市历史具有独特的魅力。
现在的挑战是选择合适的token。有几种策略可供选择。
贪婪采样
简单来说,在贪婪策略中,模型总是选择它认为在每个步骤中最有可能的token,它不考虑其他可能性或探索不同选项。模型选择具有最高概率的token,并根据所选选择继续生成文本。

使用贪婪策略在计算上是高效且直接的,但付出的代价是偶尔会产生重复或过于确定性的输出。由于模型仅在每个步骤考虑最有可能的token,它可能无法捕捉上下文和语言的完整多样性,也不能产生最具创造力的回应。模型的目光短浅只关注每个步骤中最有可能的token,而忽视了对整个序列的整体影响。
生成的输出:巴黎是未来的城市。
束搜索
束搜索是文本生成中使用的另一种策略。在束搜索中,模型假设一组“k”个最有可能的token,而不仅仅考虑每个步骤中最可能的token。这组k个token称为一个“束”。

模型为每个token生成可能的序列,并通过扩展每个束的可能行来跟踪文本生成的每个步骤的概率。
这个过程会继续,直到达到所生成文本的所需长度或遇到每个束的“结束”token。模型从所有束中选择具有最高总体概率的序列作为最终输出。
从算法的角度来看,创建束是扩展一个k元树。创建束后,您选择具有最高总概率的分支。
生成的输出:巴黎是历史和文化之城。
正态随机抽样或直接使用概率

这个想法很简单——您通过选择一个随机值并将其映射到获得的标记来选择下一个单词。将其想象成旋转轮盘,其中每个标记的区域由其概率定义。概率越高,标记被选择的机会就越大。这是一个相对便宜的计算解决方案,由于相对较高的随机性,句子(或标记序列)每次可能都会有所不同。

带温度的随机抽样
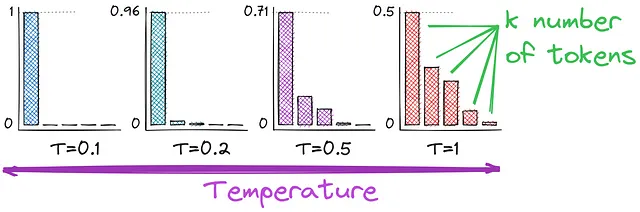
也许你还记得,我们一直在使用softmax函数将对数转换为概率。在这里,我们引入了温度——这是一个影响文本生成随机性的超参数。让我们比较一下激活函数,以更好地理解温度如何影响我们的概率计算。

你可能会注意到,区别在于分母的部分——我们除以T。温度值越高(例如,1.0),输出越多样化,而较低的值(例如,0.1)使其更加集中和确定性。T = 1将导致最初我们最初使用的softmax函数。
Top-k抽样
现在我们可以通过温度调整概率。另一个增强是使用前k个标记而不是全部标记。这将增加文本生成的稳定性,同时不会太大地降低创造力。现在它是仅针对前k个标记的带有温度的随机抽样。唯一可能的问题可能是选择数字k,以下是我们如何改进它。
核心抽样或top-p抽样
令牌概率的分布可能会非常不同,这可能会在文本生成过程中带来意外的结果。

核心抽样旨在解决不同抽样技术的一些限制。它不是指定要考虑的固定数量的“k”个标记,而是使用概率阈值“p”。此阈值表示要包括在抽样中的累积概率。模型计算每个步骤中所有可能标记的概率,然后按降序对其进行排序。

模型继续将标记添加到生成的文本中,直到它们的概率之和超过指定的阈值。核心抽样的优点在于它允许更具动态性和适应性的基于上下文的标记选择。每个步骤选择的标记数量可以根据该上下文中的标记概率而变化,这可能会产生更多样化和更高质量的输出。
结论
解码策略在文本生成中至关重要,尤其是在预训练语言模型中。如果你仔细思考一下,我们有多种方法来定义概率,多种方法来使用这些概率,以及至少两种确定要考虑的标记数量的方法。我在下面留下了一个总结表格,以总结这些知识。
温度控制解码过程中标记选择的随机性。较高的温度增加了创造力,而较低的温度则关注连贯性和结构。在追求创造力的同时,通过稳定性来调节它可以确保生成文本的优雅性。
如果您喜欢这些插图和文章内容,我将非常感谢您的支持。下次见!

原文发布在我的 LinkedIn 页面上。




