美国联合航空公司如何构建一种成本高效的光学字符识别主动学习流程
美国联合航空公司的光学字符识别主动学习流程如何成本高效构建
在这篇文章中,我们讨论了联合航空公司与亚马逊机器学习解决方案实验室合作,在AWS上构建了一个主动学习框架,用于自动化处理乘客文件。
“为了为我们的乘客提供最佳的飞行体验,并使我们的内部业务流程尽可能高效,我们在AWS上开发了一个基于自动化机器学习的文件处理流水线。为了支持这些应用程序以及使用计算机视觉等其他数据模态的应用程序,我们需要一个强大而高效的工作流,可以快速注释数据、训练和评估模型,并快速迭代。几个月的时间里,联合航空公司与亚马逊机器学习解决方案实验室合作,使用AWS CDK设计和开发了一个可重用的、用例无关的主动学习工作流。这个工作流将为我们的非结构化数据机器学习应用奠定基础,因为它将使我们能够最小化人工标注的工作量,快速提供强大的模型性能,并适应数据漂移。”
– Jon Nelson,联合航空公司的数据科学和机器学习高级经理。
问题
联合航空公司的数字技术团队由全球多样化的个体组成,他们利用尖端技术共同推动业务成果,保持客户满意度高。他们希望利用机器学习(ML)技术,如计算机视觉(CV)和自然语言处理(NLP),自动化文件处理流水线。作为这一战略的一部分,他们开发了一个内部护照分析模型,用于验证乘客的身份证件。该过程依赖于手动标注来训练ML模型,这非常昂贵。
联合航空公司希望创建一个灵活、弹性和高效的ML框架,用于自动化护照信息验证、验证乘客身份和检测可能的欺诈文件。他们聘请了ML Solutions Lab来帮助实现这一目标,这使得联合航空公司能够在未来乘客增长的情况下继续提供世界级的服务。
解决方案概述
我们的联合团队设计和开发了一个基于AWS云开发工具包(AWS CDK)的主动学习框架,该框架以编程方式配置和提供所有必要的AWS服务。该框架使用Amazon SageMaker处理未标记的数据,创建软标签,使用Amazon SageMaker Ground Truth启动手动标注作业,并使用生成的数据集训练任意的ML模型。我们使用Amazon Textract自动从特定文档字段(如姓名和护照号码)中提取信息。从高层次上看,该方法可以用以下图表来描述。
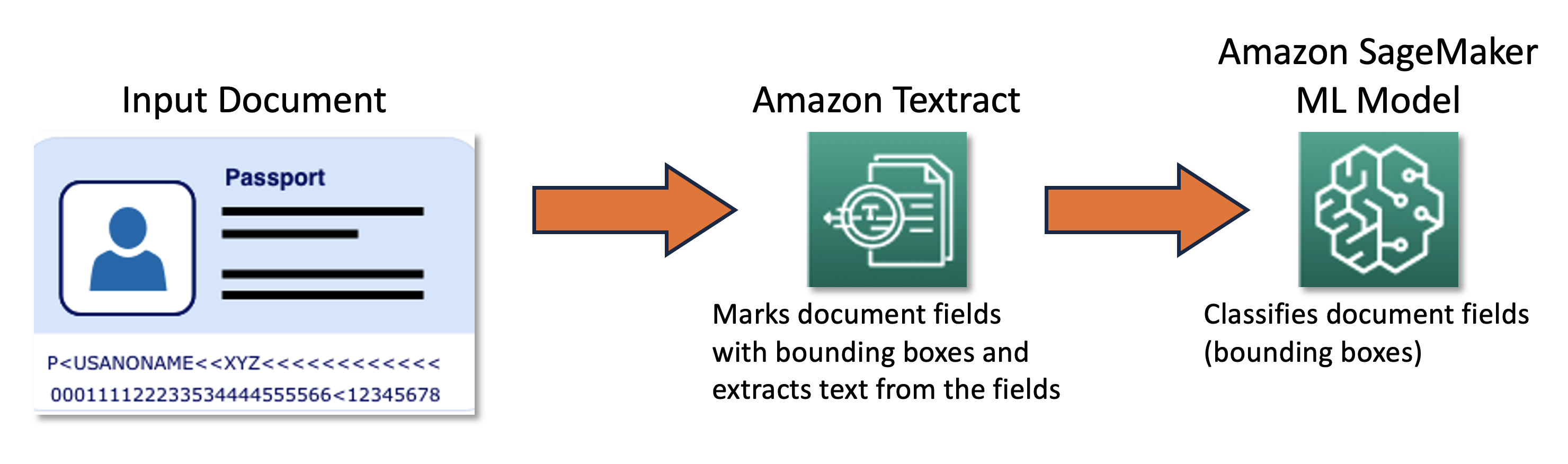
数据
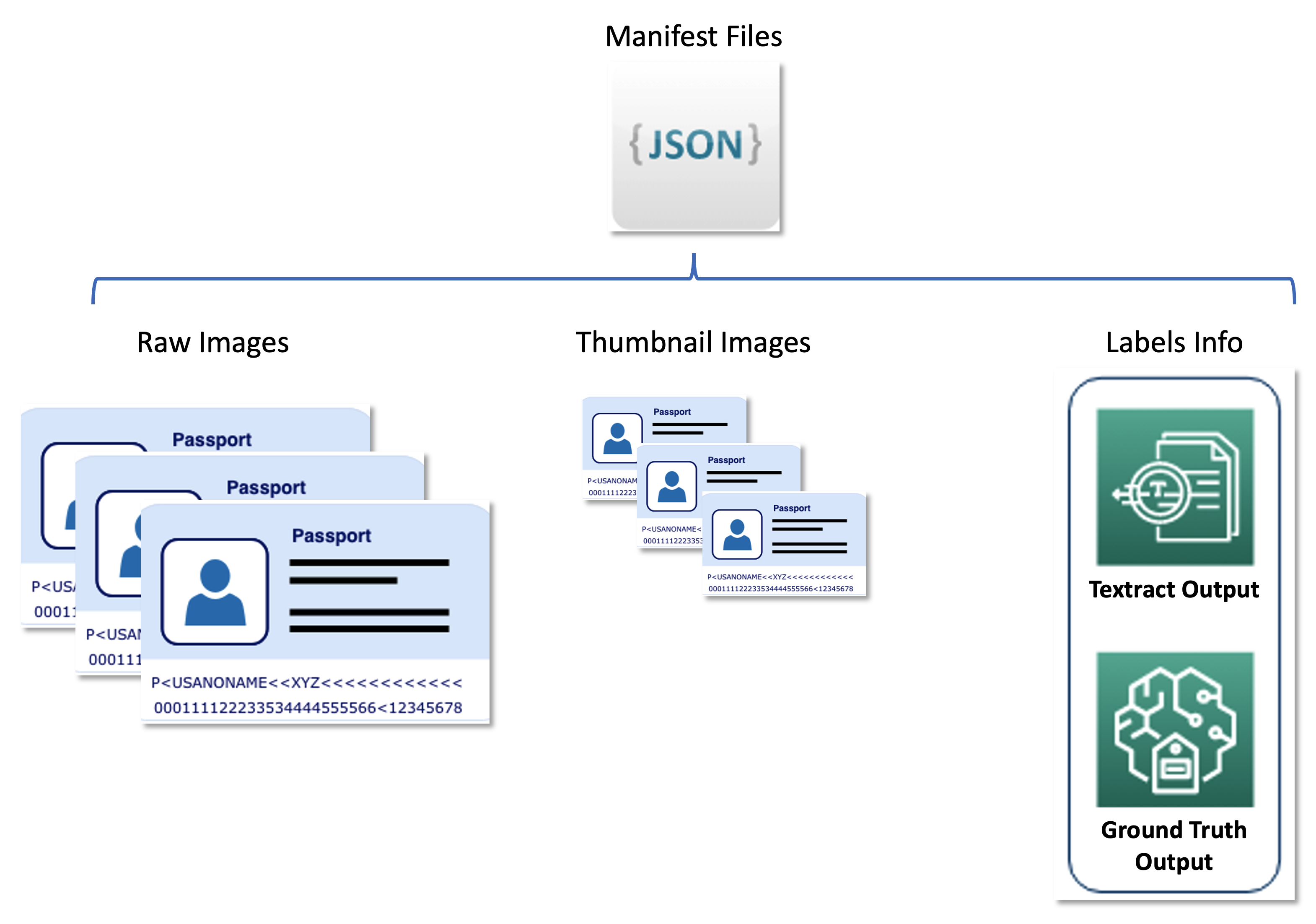
此问题的主要数据集由数万个主页护照图像组成,必须从中提取个人信息(姓名、出生日期、护照号码等)。图像大小、布局和结构因发行国家而异。我们将这些图像标准化为一组统一的缩略图,这构成了主动学习流水线(自动标注和推理)的功能输入。
第二个数据集包含以JSON行格式化的清单文件,这些文件将原始护照图像、缩略图像和标签信息(如软标签和边界框位置)相关联。清单文件作为元数据集,以统一的格式存储来自联合航空公司使用的各种AWS服务的结果,并将主动学习流水线与下游服务解耦。下图说明了这种架构。
以下代码是一个示例清单文件:
{
"raw-ref": "s3://bucket/passport-0.jpg",
"textract-ref": "s3://bucket/textract/passport-0.jpg",
"source-ref": "s3://bucket/clean-images/passport-0.jpg",
"page-num": 1,
"label": {
"image_size": [...],
"annotations": [
{
"class_id": 0,
"top": 1856,
"left": 1476,
"height": 67,
"width": 329
},
{"class_id": 1 ...},
{"class_id": 2 ...},
{"class_id": 3 ...},
{"class_id": 4 ...},
{"class_id": 5 ...},
{"class_id": 6 ...},
{"class_id": 7 ...},
{"class_id": 8 ...},
{"class_id": 9 ...},
{"class_id": 10 ...},
]
},
"label-metadata": {
"objects": [...],
"class-map ": {"0": "护照号码" ...},
"type": "groundtruth/object-detection",
"human-annotated": "yes",
"creation-date": "2022-09-19T00:58:55.729305",
"job-name": "labeling-job/passports-20220918-195035"
}
}解决方案组件
该解决方案包括两个主要组件:
- 一个机器学习框架,负责训练模型
- 一个自动标注流水线,负责以成本效益的方式提高训练模型的准确性
机器学习框架负责训练机器学习模型并将其部署为SageMaker终端节点。自动标注流水线专注于自动化SageMaker Ground Truth作业,并通过这些作业对图像进行标注的抽样。
这两个组件之间是解耦的,只通过自动标注流水线产生的一组标注图像进行交互。也就是说,标注流水线创建的标签后来由机器学习框架用于训练机器学习模型。
机器学习框架
ML Solutions Lab团队使用Hugging Face实现的最新版LayoutLMV2模型(LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding, Yang Xu, et al.)构建了机器学习框架。训练基于Amazon Textract的输出,这些输出用作预处理器,并在感兴趣的文本周围产生边界框。该框架使用分布式训练,并运行在基于SageMaker预构建Hugging Face镜像的自定义Docker容器上,该镜像具有额外的依赖项(在预构建的SageMaker Docker镜像中缺少但Hugging Face LayoutLMv2所需的依赖项)。
该机器学习模型经过训练,可以对以下11个类别的文档字段进行分类:
"0": "护照号码",
"1": "姓氏",
"2": "名字",
"3": "国籍",
"4": "出生日期",
"5": "出生地",
"6": "性别",
"7": "签发日期",
"8": "机关",
"9": "到期日期",
"10": "批准事项"
预构建镜像参数如下:
{
"framework": "huggingface",
"py_version": "py38",
"version": "4.17",
"base_framework_version": "pytorch1.10"
}自定义镜像的Dockerfile如下(BASE_IMAGE指的是前面的基础镜像):
ARG BASE_IMAGE
FROM ${BASE_IMAGE}
RUN pip install "amazon-textract-response-parser>=0.1,=8,=0.11.3,<0.12"
RUN pip install setuptools==59.5.0训练流水线可以用以下图示概括:
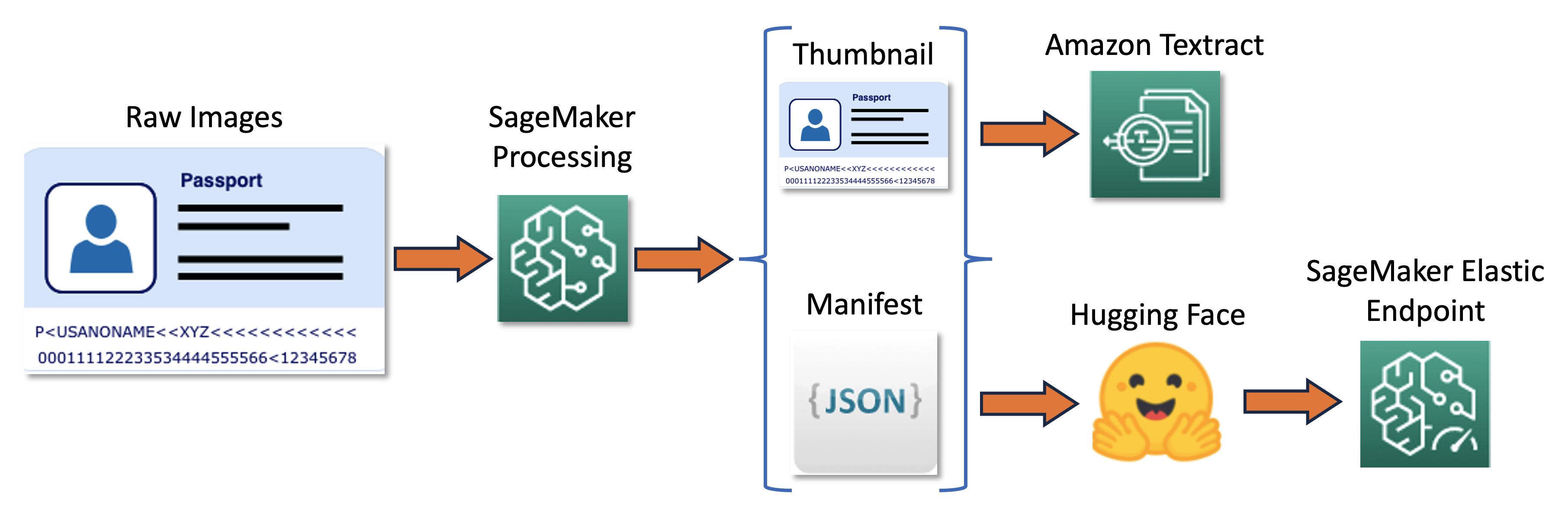
首先,我们将一批原始图像调整大小并规范化为缩略图。同时,创建一个JSON行清单文件,每个图像一行,其中包含有关批处理中的原始图像和缩略图的信息。接下来,我们使用Amazon Textract在缩略图中提取文本边界框。Amazon Textract产生的所有信息都记录在同一个清单文件中。最后,我们使用缩略图和清单数据来训练模型,该模型稍后将部署为SageMaker终端节点。
自动标注流水线
我们开发了一个自动标注流水线,旨在执行以下功能:
- 对未标注的数据集进行定期批量推理。
- 根据特定的不确定性抽样策略过滤结果。
- 触发SageMaker Ground Truth作业,使用人力资源对抽样图像进行标注。
- 将新标记的图像添加到训练数据集中,以进行后续模型改进。
不确定性抽样策略通过选择最有可能有助于提高模型准确性的图像来减少发送到人工标注作业的图像数量。由于人工标注是一项昂贵的任务,这样的抽样是一种重要的成本降低技术。我们支持四种抽样策略,可以作为存储在参数存储库中的参数进行选择,参数存储库是AWS系统管理器的一项功能:
- 最低置信度
- 边际置信度
- 置信度比例
- 熵
整个自动标注工作流程是使用AWS Step Functions实现的,它协调处理作业(称为批量推理的弹性终端节点)、不确定性抽样和SageMaker Ground Truth。以下图示展示了Step Functions的工作流程。

成本效益
影响标注成本的主要因素是手动注释。在部署这个解决方案之前,United团队必须使用基于规则的方法,这需要昂贵的手动数据标注和第三方解析OCR技术。通过我们的解决方案,United将手动标注的工作量减少到只标注那些能够使模型改进最大的图像。由于该框架与模型无关,因此可以在其他类似的场景中使用,将其价值扩展到更广泛的文档集。
我们基于以下假设进行了成本分析:
- 每个批次包含1,000个图像
- 使用mlg4dn.16xlarge实例进行训练
- 使用mlg4dn.xlarge实例进行推理
- 每个批次训练时使用10%的注释标签
- 每轮训练后的准确率改进如下:
- 第一个批次后为50%
- 第二个批次后为25%
- 第三个批次后为10%
我们的分析显示,如果没有主动学习,训练成本将保持稳定且高昂。而将主动学习纳入其中,每个新的数据批次的成本将呈指数级下降。
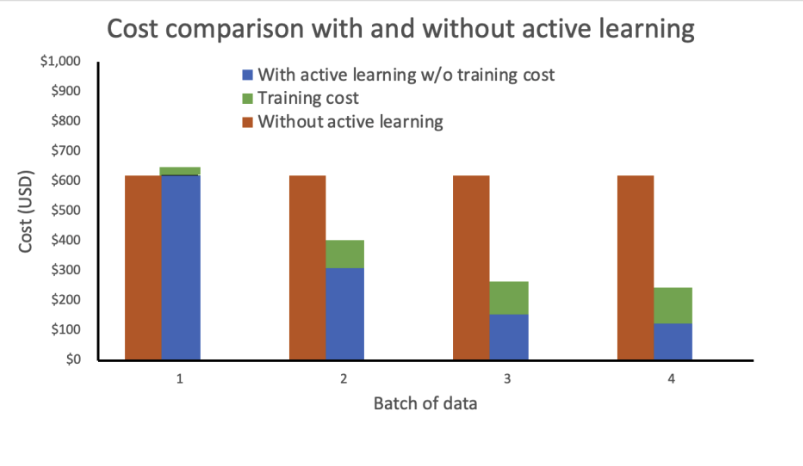
我们通过将推理终端节点部署为弹性终端节点,并添加自动缩放策略来进一步降低成本。终端节点资源可以在零和配置的最大实例数之间进行缩放。
最终解决方案架构
我们的重点是帮助United团队满足其功能要求,同时构建一个可扩展和灵活的云应用程序。ML Solutions Lab团队借助AWS CDK开发了完整的生产就绪解决方案,自动化管理和配置所有云资源和服务。最终的云应用程序以单个AWS CloudFormation堆栈部署,其中包含四个嵌套堆栈,每个堆栈代表一个单独的功能组件。
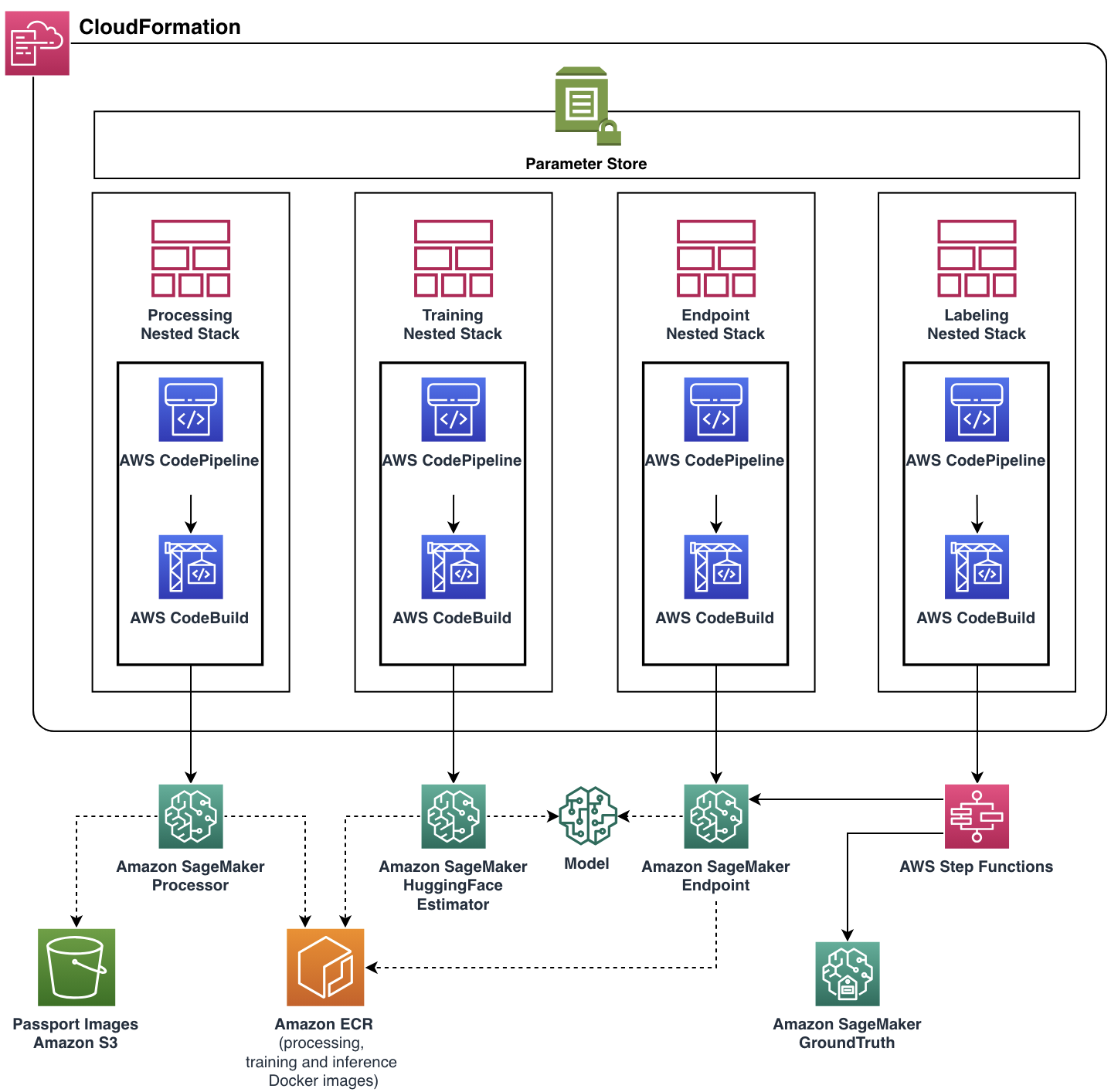
几乎每个流水线功能,包括Docker镜像、终端节点自动缩放策略等,都通过参数存储进行了参数化。具有这样的灵活性,可以使用各种设置运行相同的流水线实例,增加了实验能力。
结论
在本文中,我们讨论了United航空公司与ML Solutions Lab合作,在AWS上构建了一个主动学习框架,以自动处理乘客文件。该解决方案对United的自动化目标的两个重要方面产生了重大影响:
- 可重用性 – 由于模块化设计和与模型无关的实现,United航空公司几乎可以将此解决方案在几乎任何其他自动标注的机器学习用例中重复使用
- 经常性成本降低 – 通过智能地结合手动和自动标注流程,United团队可以降低平均标注成本并替代昂贵的第三方标注服务
如果您有兴趣实施类似的解决方案或想了解更多关于ML Solutions Lab的信息,请联系您的客户经理或访问我们的亚马逊机器学习解决方案实验室。





