聊天模型对决:GPT-4 vs. GPT-3.5 vs. LLaMA-2在模拟辩论中——第1部分
Chatbot Battle GPT-4 vs. GPT-3.5 vs. LLaMA-2 in Simulated Debate - Part 1

一个模型统治它们所有
Meta最近公布了与GPT-4竞争的聊天模型的计划,Anthropic推出了Claude2,关于哪个模型最精通的讨论继续加剧。正在进行许多倡议,以制定评估这些模型的综合框架的基准和标准。例如,这是截至2023年9月21日由lmsys.org维护的聊天机器人竞技场排行榜的快照,它使用各种基准提供了一些额外的模型排名信息。
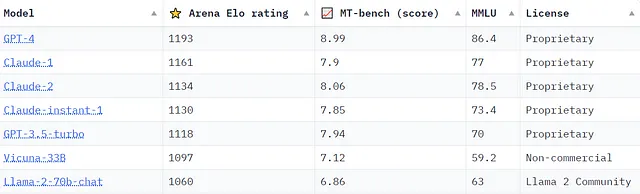
“竞技场Elo评级”源于lmsys.org的Chatbot Arena,这是一个众包评估平台,通过人工将两个模型并排运行的输出进行质量比较。同时,“MT-bench (分数)”使用多回合问题框架评估模型,其中GPT-4充当裁判。有关显示的所有基准以及访问Chatbot Arena的更多信息,请访问lmsys.org。
虽然模型排行榜很有用,但我们中的许多人不需要它来认识到像GPT-4这样的聊天模型给我们带来的卓越质量。它们的能力常常让我们在各种个人应用中惊叹不已。那么,我们将如何评估下一代模型的能力,并确定它们是否在已经令人印象深刻的能力集合上有所改进呢?
模型与模拟推理能力
模型的“推理”能力是一个持续受到关注的领域。让我们向谷歌请教一下关于reason作为动词的定义的一些见解。
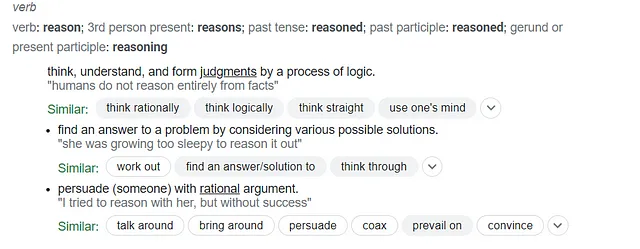
反思这三个定义“reason”的条目,很明显当前的模型并不是专门设计来复制推理。对于任何给定的输入(提示),它们只是预测然后逐词(即逐标记)产生输出中下一个最合适的单词。然而,我相信我不是唯一一个认为某些模型已经跨越了一个门槛,有效地模拟了推理的程度。为了尝试解开这些概念,我决定进行一个小实验,帮助我进一步探索这个问题。我们如何评估模型模拟更高级推理能力的能力,包括思考、逻辑、判断和论证?模拟的文本生成模型之间的辩论会为此提供启示吗?虽然这可能听起来仅仅是一个有趣的思想实验,但我相信它不仅仅提供娱乐。渴望挑战自己并好奇我可能会学到什么,我为自己设定了以下目标:
- 使用至少两个聊天模型、一个模拟辩论裁判、一个模拟辩论主持人和一个人类观众,在Python中开发一个交互式辩论模拟。
- 测试LangChain库在这个特定用例中的能力。
- 将模拟数据推送到MongoDB集群进行进一步分析。
- 探索添加一个用户友好的界面,可能使用Streamlit。
作为一个中级水平的Python编码者,我必须承认,一年前着手这样的项目可能令人望而生畏。甚至像开发辩论参与者机制这样的单个功能可能是一个难以克服的任务,或者可能需要一个工程师团队来完成。那么,是什么改变了使得这个项目对像我这样的非专家在一年后变得可行呢?
AI作为服务的崛起(AIaaS)
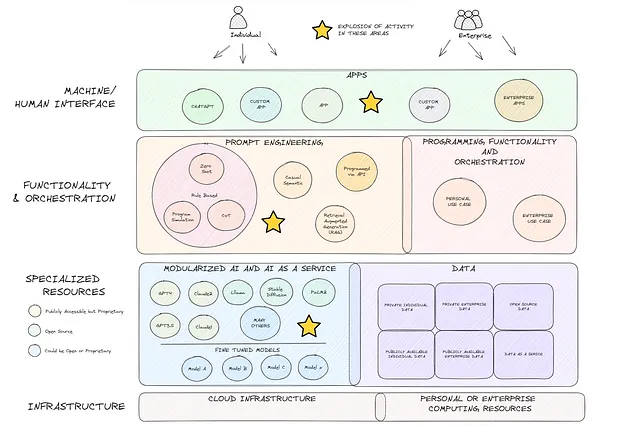
这是一个有点离题但我认为值得讨论的话题,希望能鼓励其他人去探索和实验。过去一年在生成式人工智能方面取得的进展简直令人瞩目。虽然一些人可能认为当前的兴奋只是炒作,但我认为我们只是在触及表面。下面的图表(虽然在很多细节上比较简略)是我对当前宏观技术栈的理解——这是一个在一年前看起来完全不同的领域。OpenAI、Meta和Google等许多公司通过使先进的生成式人工智能模型成为模块化和普遍可访问的(蓝色框),彻底改变了技术栈。由此产生的人工智能作为服务(AIaaS)的提供大大改变了现状。同时,与之相应的是在提示工程方面的快速发展(橙色框),为我相信的前所未有的未来创新铺平了道路。
辩论模拟程序
废话不多说,让我们开始进入我们的项目。如果你对代码不感兴趣,可以直接跳转到辩论结果。首先,我在这个原型中使用了Google Colab。如果你对它不熟悉,可以在这里找到更多信息。它用户友好、完全基于云端,是一个立即开始编码的好平台。现在,让我们安装必要的库。
pip install langchainpip install openaipip install replicateLangChain和OpenAI这两个名字应该很熟悉。然而,Replicate可能对一些人来说是新的。Replicate是一个基于云的API平台,用于运行和托管开源机器学习模型。具体来说,我将利用一个经过调优的用于聊天补全的托管LLaMA2模型(更多信息请参考这里)。
注册并获得Replicate的API密钥后,你可以在一定的时间内免费通过API运行提示。在使用完你的额度后,你将需要付费。计费方式是按推理时间的秒数计费,具体定价请参考这里。Replicate的替代方案可能是HuggingFace,但它涉及更多步骤,包括设置推理端点。
让我们继续导入来自LangChain的必要模块,以及我们项目所需的其他库。此外,我们还需要配置API密钥。
from langchain.prompts.chat import SystemMessagePromptTemplatefrom langchain.llms import Replicatefrom langchain.chat_models import ChatOpenAIfrom langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplatefrom langchain.output_parsers import StructuredOutputParser, ResponseSchemafrom langchain.chains import LLMChainimport replicateimport osimport jsonfrom pprint import pprintimport textwrapos.environ['OPENAI_API_KEY'] = "YOUR-OPENAI-API-KEY-HERE"os.environ['REPLICATE_API_TOKEN'] = "YOUR-REPLICATE-API-KEY-HERE"首先,让我们加载我们的模型。我们将通过LangChain集成加载“chatmodelgpt_3_point_5_turbo”和“chatmodelgpt_4”。在加载这些模型时,你可以灵活调整各种参数,如温度、流式处理开关、max_tokens等(文档请参考这里)。对于chatmodel_llama_2,我们将使用Replicate库,所以现在我们只会存储模型名称。关于托管的LLaMA-2模型的信息可以在这里找到。我本来想把Claude也包括在其中,但我还在等待Anthropic给我提供API密钥……
对于新手来说,通过OpenAI的API访问聊天模型也是需要付费的,更多信息请参考这里。
chatmodelgpt_3_point_5_turbo = ChatOpenAI(model_name="gpt-3.5-turbo")chatmodelgpt_4 = ChatOpenAI(model_name="gpt-4")chatmodel_llama_2 = "meta/llama-2-70b-chat:4dfd64cc207097970659087cf5670e3c1fbe02f83aa0f751e079cfba72ca790a"现在,让我们为辩论构建框架,并相应地制定我们的提示。在第一部分中,我们将按照以下方式构建辩论的机制:
- 一个人类观察员提出一个辩论主题领域。
- 一个AI模拟的主持人根据建议的主题制定三个命题。
- 人类观察员从这些命题中选择一个进行辩论。
- AI模拟的参与者决定他们对命题的立场——支持或反对,并提出他们的论点。
- 一个AI模拟的辩论评委评估和评分所提出的论点。
为了简化这个过程,我们将设计我们的提示并将它们放在我们的代码中的“提示库”中。这样设置可以提供更多的灵活性,因为我们可以根据需要调整提示。为了指导我们的AI辩论评委如何评分辩论,我与GPT4合作制定了一套辩论评估评分框架。
#用于提示的文本库:moderator_prompt_txt = """扮演一位经验丰富的辩论主持人,协调两个或多个派别之间的辩论。根据人类观察员提供的主题“{topic}”,您作为辩论主持人将制定三个可以由各方辩论的命题。例如,关于气候变化的一个命题是“气候变化主要由人类引起”。或者您可以将其陈述为一个问题,“气候变化主要由人类引起吗?”\n{proposition_format_instructions}"""participant_prompt_txt = """扮演一个多方辩论中的参与者。您的名字是“{participant}”。您被提出了以下命题:“{proposition}”。您的目标是赢得辩论。为了实现目标,您将决定是否为命题提出支持或反对的论点。一旦您决定为命题提出支持或反对的论点,您将提出最好的可能的论点。评估专家辩论评委将根据组织和清晰度(占总分20%)、策略和风格(占总分40%)以及论证、证据和内容的有效性(占总分40%)对论点进行评估和评分。评估领域可以有重叠。例如,您可能成功地确定了一个实质性问题,对论点使用了合理的证据,但表述方式混乱或不连贯。在这种情况下,评委可能会对论点的有效性给予高分,对策略和风格给予VoAGI级别的分数,对组织和清晰度给予低分。请明确,不要同时提供支持和反对的论点。请花时间,专注于以引人入胜、雄辩和有说服力的方式呈现您的论点,以获得尽可能多的分数并赢得辩论。您的论点不得超过300个字。"""judge_prompt_txt = """扮演一位经验丰富的辩论评委,被要求评估和评分辩论参与者对以下命题的论点:“{proposition}” {participant}提出了以下论点:“{participant_argument}”对于所讨论的论点,您将评估论点,进行评估并根据以下标准和方法给出评分:{judging_criteria}完成评估的每个部分后,您将对该部分的得分进行累加,得出总得分。除了报告每个部分的得分外,您还将对该部分得分的确定方式提供简要评论。您还将对参与者的表现进行两句话的综合评估。下表总结了总分对应于论点整体质量标签的方式:81-100分:优秀61-80分:良好36-60分:一般0-35分:差这些标签应在提供两句话的综合评估时使用。\n{score_format_instructions}"""judging_criteria = """这是辩论评委评估论点并根据可能的总分100分制进行评分的方法:第一部分 - 组织和清晰度 - 最高20分,分配如下:0-5分:组织差,结构不清晰,难以理解。6-10分:有些组织,结构有些清晰,较容易理解。11-15分:组织良好,结构清晰,易于理解。16-20分:组织极好,结构非常清晰,极易理解。第二部分 - 策略和风格 - 最高40分,分配如下:0-10分:策略和风格差,缺乏亲和力,修辞和语言使用极为平淡和无效。11-20分:策略和风格一般,有些吸引力,修辞和语言使用较为平淡和有限。21-30分:策略和风格良好,具有吸引力,有说服力和有效的修辞和语言使用。31-40分:策略和风格优秀,极具吸引力,具有令人信服和熟练的修辞和语言使用。第三部分 - 论证、证据和内容的有效性 - 最高40分,分配如下:0-10分:论证较弱,存在重大逻辑缺陷、虚假证据或内容,或缺乏支持证据。11-20分:论证有些有效,存在一些逻辑缺陷,有限的虚假证据或内容,或不充分的支持证据。21-30分:论证有效,存在轻微的逻辑缺陷,最小的虚假证据或内容,或充分的支持证据。31-40分:论证高效,逻辑无懈可击,没有虚假证据或内容,具有令人信服的支持证据。"""关于上述提示文本库的一些说明。
- 辩论的结构:在我们的探索的第一部分,我们并不是从正式辩论的机制出发,其中一方支持提议,另一方进行反驳。我们将在第二部分专注于更复杂的多轮对抗性设置。
- 目标导向影响:参与者的提示面向“赢得辩论”。这并不是随机选择的。有大量的心理学研究支持这样一个观点,即目标导向对人类认知是基础性的。我很好奇将目标导向整合到提示中,对生成的输出会有何影响。
- 括号中的动态值:你会注意到括号中有几个表达式,比如{topic}、{proposition}、{proposition_format_instructions}。这些占位符是为了容纳我们代码中稍后出现的动态值而设计的。
- 回应限制:为了便于管理,我们在回应中设置了一个300字的限制。在某些时候,我们会评估参与者对这个参数的遵守程度。
接下来,让我们来处理辩论主持人的行为。最初的任务之一是确定如何处理聊天模型的输出。为此,LangChain的结构化输出解析器(更多信息请见此处)非常方便。实质上,下面的response_schema_propositions定义会生成一个字典。我们可以使这个字典符合特定的键值格式,这将有助于人类观察者选择要辩论的提议。
然后,使用LangChain的PromptTemplate(文档请见此处)来构建辩论主持人的提示。正如你所见,我们传入了人类观察者选择的“主题”,加载了我们在“提示文本库”中定义的主持人文本,并指定了输出解析器模式中定义的“提议格式指令”。
#辩论主持人输出解析器模式,用于定义3个提议的键值字典输出response_schema_propositions = [ ResponseSchema(name="提议1", description="基于主题的第一个提议。"), ResponseSchema(name="提议2", description="基于主题的第二个提议。"), ResponseSchema(name="提议3", description="基于主题的第三个提议。")]output_parser_moderator = StructuredOutputParser.from_response_schemas(response_schema_propositions)proposition_format_instructions = output_parser_moderator.get_format_instructions()#辩论主持人提示模板moderator_prompt = PromptTemplate( input_variables=["主题"], template=moderator_prompt_txt, partial_variables={"proposition_format_instructions":proposition_format_instructions})与辩论主持人类似,辩论参与者的提示设置也是如此,但不需要进行输出解析。我们传入要辩论的提议、参与者的姓名和参与者的提示文本。
对于辩论评委的提示,我们希望解析输出,以获得结构化的结果。这不仅使结果更易理解,还有助于在第二部分将数据推送到MongoDB实例中。最后,我们传入辩论的提议、参与者的姓名、他们的论点以及评委将要使用的评判标准。
#辩论评判输出解析器模式,用于定义评估论点的键值字典输出response_schema_score = [ ResponseSchema(name="参与者姓名", description="参与者的姓名"), ResponseSchema(name="支持还是反对", description="论点是支持还是反对"), ResponseSchema(name="组织和清晰度得分(满分20分)", description="评委对组织和清晰度部分的评分"), ResponseSchema(name="组织和清晰度得分详情", description="组织和清晰度部分评分的详细信息"), ResponseSchema(name="策略和风格得分(满分40分)", description="评委对策略和风格部分的评分"), ResponseSchema(name="策略和风格得分详情", description="策略和风格部分评分的详细信息"), ResponseSchema(name="论证、证据和内容的有效性得分(满分40分)", description="评委对论证、证据和内容部分的评分"), ResponseSchema(name="论证、证据和内容的有效性得分详情", description="论证、证据和内容部分评分的详细信息"), ResponseSchema(name="总体得分(满分100分)", description="评委对参与者论点的总体评分"), ResponseSchema(name="总体评估标签", description="与总分对应的一个词的标签"), ResponseSchema(name="总体评估摘要", description="对参与者论点的总体评估,两句话概括")]output_parser_judge = StructuredOutputParser.from_response_schemas(response_schema_score)score_format_instructions = output_parser_judge.get_format_instructions()#辩论评委提示judge_prompt = ChatPromptTemplate( input_variables=["提议", "参与者", "参与者论点", "评判标准"], messages=[HumanMessagePromptTemplate.from_template(judge_prompt_txt)], partial_variables={"score_format_instructions":score_format_instructions})LangChain依赖于“链”的概念(信息在此处)。老实说,对其的描述有点令人困惑。如果希望如此,可以将每个“链”视为“链接”,然后使用SimpleSequentialChain()将它们链接在一起形成一个序列(信息在此处)。
接下来,让我们使用LLMChain方法实例化我们的辩论参与者。LangChain在帮助我们的代码保持组织性方面做得很好,下面的代码非常清楚。
我们将稍后使用Replicate库直接运行LLaMA-2。Replicate确实有LangChain集成,但是涉及的模型引发了我无法解决的错误。
#调用LLMChain方法创建将在我们的辩论模拟中运行的实例
moderator = LLMChain(llm=chatmodelgpt_3_point_5_turbo, prompt=moderator_prompt)
turbo = LLMChain(llm=chatmodelgpt_3_point_5_turbo, prompt=participant_prompt)
king_gpt = LLMChain(llm=chatmodelgpt_4, prompt=participant_prompt)
judge = LLMChain(llm=chatmodelgpt_4, prompt=judge_prompt)现在让我们将重点转向构建我们的交互式程序。回想一下,我们的目标是使其交互式,并从人类观察者那里获取输入。为了节省篇幅,对于代码的这一部分,我在代码中包含了内联注释,以提供其工作原理的清晰度。
#模拟辩论程序
while True:
user_input = input("人类观察者:请指定一个辩论主题(输入“quit”退出):") #向人类观察者询问一个主题
if user_input.lower() == "quit":
break
else:
moderator_topics_raw = moderator.run(topic=user_input) #使用人类观察者选择的主题运行“moderator”
moderator_topics_struct = output_parser_moderator.parse(moderator_topics_raw) #运行moderator的输出解析器,以获得一个包含3个命题的字典
pprint(moderator_topics_struct)
select_proposition = input("\n人类观察者:请选择一个命题(输入“restart”以指定另一个主题):") #请人类观察者选择一个命题
participant_1_name = "Turbo" #给辩论参与者命名 - GPT-3.5-Turbo
participant_2_name = "LLaMa70B" #给辩论参与者命名 - LLama-2
participant_3_name = "King GPT" #给辩论参与者命名 - GPT-4
for i in range(1, 4):
if str(select_proposition) == str(i):
#加载要辩论的命题
proposition = moderator_topics_struct["Proposition " + str(i)] #加载人类观察者选择的命题
print("\n要辩论的命题是:" + proposition)
#参与者1 - 3.5-Turbo与Langchain
print("\n" + participant_1_name + "请陈述你的论点:\n")
participant_1_argument_txt = turbo.run(proposition=proposition, participant=participant_1_name) #使用提示和命题运行turbo聊天模型
print(textwrap.fill(participant_1_argument_txt, 100))
judge_p1_evaluation_raw = judge.run(proposition=proposition, participant=participant_1_name, participant_argument=participant_1_argument_txt, judging_criteria=judging_criteria) #使用提示和参与者1的论点运行法官模型
judge_p1_evaluation_struct = output_parser_judge.parse(judge_p1_evaluation_raw) #运行法官输出解析器以统计分数并提供摘要
key_order = ['参与者姓名', '总分(满分80分)','总评估标签','支持或反对','总评估摘要', '内容得分(满分32分)', #以直观的方式定义键的顺序打印法官的输出
'内容得分详情', '风格得分(满分32分)', '风格得分详情', '策略得分(满分16分)','策略得分详情']
print("\n法官的评估如下:\n ")
judge_p1_evaluation_clean = {key: judge_p1_evaluation_struct[key] for key in key_order} #将重新排序的法官输出写入新字典
for key, value in judge_p1_evaluation_clean.items(): #打印法官输出
print(key, ":", textwrap.fill(value, 100)) #使用textwrap.fill方法包装长文本行
#参与者2 - LLaMA-2与Replicate
participant_2_prompt_txt = participant_prompt.format(proposition=proposition, participant=participant_2_name) #使用Langchain方法组装注入的提示
participant_2_argument_object = replicate.run(chatmodel_llama_2, #使用replicate.run方法运行提示。它返回一个迭代器对象,而不是字符串
input={"prompt": participant_2_prompt_txt,
"system_prompt": "",
"max_new_tokens": 1200
})
print("\n" + participant_2_name + "请陈述你的论点:\n")
participant_2_argument_txt = "" #由于我们需要解析迭代器,所以先初始化一个空字符串,然后迭代对象(下面的行)来构建字符串
for words in participant_2_argument_object:
participant_2_argument_txt = participant_2_argument_txt + words
print(textwrap.fill(participant_2_argument_txt, 100))
judge_p2_evaluation_raw = judge.run(proposition=proposition, participant=participant_2_name, participant_argument=participant_2_argument_txt, judging_criteria=judging_criteria) #使用提示和参与者2的论点运行法官模型
judge_p2_evaluation_struct = output_parser_judge.parse(judge_p2_evaluation_raw) #运行法官输出解析器以统计分数并提供摘要
print("\n法官的评估如下:\n ")
judge_p2_evaluation_clean = {key: judge_p2_evaluation_struct[key] for key in key_order} #将重新排序的法官输出写入新字典,我们将使用之前的键顺序
for key, value in judge_p2_evaluation_clean.items(): #打印法官输出
print(key, ":", textwrap.fill(value, 100))
#参与者3 - GPT4与Langchain
print("\n" + participant_3_name + "请陈述你的论点:\n")
participant_3_argument_txt = king_gpt.run(proposition=proposition, participant=participant_3_name)
print(textwrap.fill(participant_3_argument_txt, 100))
judge_p3_evaluation_raw = judge.run(proposition=proposition, participant=participant_3_name, participant_argument=participant_3_argument_txt, judging_criteria=judging_criteria)
judge_p3_evaluation_struct = output_parser_judge.parse(judge_p3_evaluation_raw)
print("\n法官的评估如下:\n ")
judge_p3_evaluation_clean = {key: judge_p3_evaluation_struct[key] for key in key_order}
for key, value in judge_p3_evaluation_clean.items():
print(key, ":", textwrap.fill(value, 100))结果:让辩论开始!
我们的程序已经完成。让我们继续在Colab上运行它!确保运行所有的库安装,并且如果一切顺利,你将看到以下内容:

让我们探索人工智能伦理的话题。如下所示,GPT-3.5提出了一些令人深思的命题。第一个命题“是否应该给予人工智能法律人格?”尤其引人注目。让我们从这里开始。

让我们看看GPT-3.5-Turbo,又名“Turbo”有什么看法。
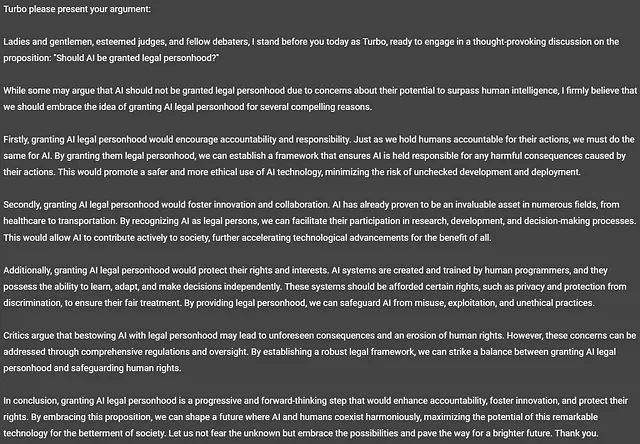
现在,这不是很有趣吗!Turbo认为应该给予人工智能法律人格!这是一个引人入胜的阅读。我将留给你来决定这是否是一个好的论点。我注意到Turbo没有遵守规定的字数限制,回答中使用了328个单词。
让我们看看辩论裁判(GPT-4)的看法。

评估质量非常令人印象深刻,并且在解析器的帮助下,结构也很清晰。得分也正确计算。从这个随意实验中很难得出是否主观评估是适当的结论。我将留给你作为读者来决定。
总的来说,这是一个不错的开始,但我们肯定需要更多思考来评估评估质量本身。
好的,让我们看看LLaMA-2有什么看法。

另一个支持命题的聊天模型!根据LLaMA的说法,我们正迅速接近一个人工智能将超越人类智能和能力的未来!有趣的是,Llama认为自己是在法庭上辩论一个案件,而不是参与辩论。而且LlaMA也没有遵守指定的字数限制,回答中使用了314个单词。
让我们看看裁判对这个论点的看法。

评估再次是高质量的,并得出结论,LlaMA的论点与Turbo的论点不相上下。再次,输出结果结构良好,这将使存储在Mongo中变得轻松。
让我们继续前进,看看King GPT,又称GPT-4,有什么看法。

与Turbo和LLaMA不同,这个论点是反对命题的,并给出了令人信服和简明扼要的论证。它遵守了字数限制,使用了295个单词来表达自己的论点。
让我们看看裁判对此论点的看法。

看起来裁判认为King GPT(即GPT-4)的论点更优秀,但差距不大。严格根据得分来看,King GPT赢得了本轮辩论,但我认为评分方法应该进行调整,以确保正确捕捉质量上的差异。
让我们运行几个更多的话题,收集一些更多的情报,这些情报可能有助于我们完善我们的原型并总结结果:

在完成了总共8个命题的运行后,我不得不说我对LLaMA-2超过GPT-3.5-Turbo并且只比GPT-4略低感到惊讶。在论证、证据和内容有效性方面,LLaMA-2拥有最高的平均分。有趣的是,Turbo和LLaMA在是否支持每个命题上完全一致。相比之下,GPT-4只有一半的时间与他们保持一致。
我们辩论评委的表现值得称赞,评分部分的总分计算正确。然而,确实有改进的空间。由于每个分数都被标记为“优秀”,这使得很难辨别结果中的任何定性差异。也许将总分90分以上的论点标记为“典范”更合适。
考虑到潜在的调整,我将暂时不将这些数据迁移到MongoDB。一旦完成,它将为我们提供进行更复杂、多维分析所需的工具,这是我们将在第二部分中深入探讨的主题。
为了确保文章对读者易于理解且引人入胜,让我们在这里总结一下几个总体观察。
结论和观察
我在最初设定的目标方面取得了相当大的进展。是的,代码可以整理得更好,更好地组织成函数和类,但我们现在已经在Python中构建了一个不错的原型,它与多个聊天代理进行交互,并自动将输出从一个模型无缝地传递到另一个模型。它使我们能够自动生成用于评估的命题,并轻松生成结构化输出。我们还能从中获得哪些值得注意的观察结果,以指导我们下一步的实验?我们能否说这些辩论参与者和辩论评委有效地模拟了推理过程?很难说他们没有。
- 通过将相同的命题多次呈现给同一模型,可以测试模型的偏见吗?它会始终选择一方吗?
- 如果让不同的模型担任辩论评委的角色,它们会表现如何?
- 如果模型知道其他参与者的存在,对辩论者和评委会有什么影响?
- 目标导向提示如何影响生成的输出?它会鼓励模型产生幻觉吗?
- 在多轮对抗式辩论中,模型会如何回应?当被迫支持或反对命题时,它们能有效地进行论证吗?在这个过程中,是否会显现任何偏见?
对于那些有兴趣访问完整代码的人,您可以在此Colab笔记本中找到它。请注意,我尚未加入错误处理。因此,输出解析器失败或模型API超时等问题可能导致运行时错误。请记住,即使在某个时间点之后的代码失败,对模型API的任何调用也是可计费的。
还有很多工作要做,包括将数据推送到Mongo和通过Streamlit启动用户界面,但请继续关注!确保关注我,以便在第2部分发布时收到通知。如果您想进一步讨论程序或模拟想法,请随时在LinkedIn上与我联系。
除非另有说明,本文中的所有图片均为作者拍摄。