如何在Snowflake上搭建一个流式半结构化分析平台
构建一个用于半结构化数据或JSON的数据湖一直都是具有挑战性的想象一下,如果这些JSON文档是从医疗供应商那里以流式或持续不断的方式传输过来的,那么我们就需要一个能够处理如此大量数据的稳健的现代化架构与此同时,分析层也需要…

介绍
Snowflake是一种适用于处理大量数据分析的软件即服务(SaaS)平台。该平台非常易于使用,非常适合企业用户、分析团队等从不断增长的数据集中获取价值。本文将介绍在Snowflake上为医疗数据创建流式半结构化分析平台的组件,并讨论在此阶段的一些关键考虑因素。
背景
医疗行业支持许多不同的数据格式,但我们将考虑最新的半结构化格式之一,即FHIR(快速医疗互操作性资源),用于构建我们的分析平台。这种格式通常在一个JSON文档中嵌入了所有以患者为中心的信息。该格式包含大量信息,如所有医院就诊记录、实验室结果等。当分析团队提供一个可查询的数据湖时,可以提取有价值的信息,例如有多少患者被诊断为癌症等。假设所有这些JSON文件通过不同的AWS服务或端点API每15分钟推送到AWS S3(或任何其他公共云存储)。
架构设计
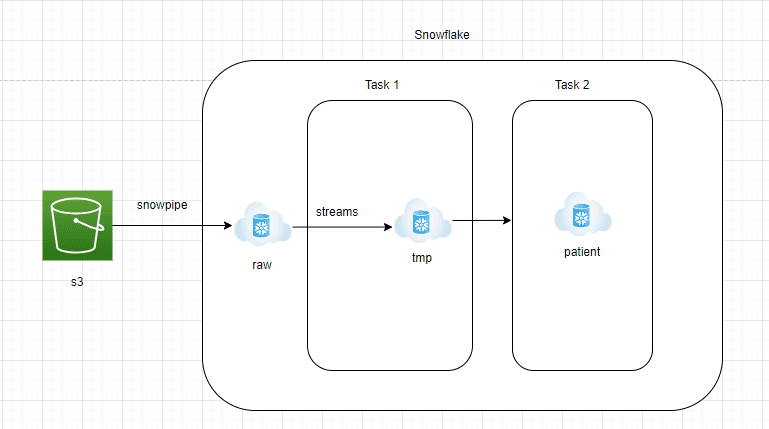
架构组件
AWS S3到Snowflake原始区:
- 需要持续将数据从AWS S3流式传输到Snowflake的原始区域。
- Snowflake提供了Snowpipe托管服务,可以以连续流式的方式从S3读取JSON文件。
- 在Snowflake的原始区域中创建一个具有variant列的表,以原生格式存储JSON数据。
Snowflake原始区到Streams:
- Streams是一项托管的变更数据捕获服务,可以捕获所有新进入的JSON文档并存储在Snowflake的原始区域。
- Streams将指向Snowflake原始区域的表,并将append设置为true。
- Streams就像任何表一样容易查询。
Snowflake任务1:
- Snowflake任务是类似于调度程序的对象。可以使用cron job的表示法来调度运行查询或存储过程。
- 在这个架构中,我们创建了任务1来从Streams中获取数据,并将其加载到一个分层表中。该层将被截断和重新加载。
- 这样做是为了确保每15分钟处理新的JSON文档。
Snowflake任务2:
- 该层将把原始的JSON文档转换为分析团队可以轻松查询的报表表格。
- 为了将JSON文档转换为结构化格式,可以使用Snowflake的lateral flatten功能。
- lateral flatten是一个易于使用的函数,可以展开嵌套的数组元素,并可以使用“:”符号轻松提取。
关键考虑因素
- 建议使用Snowpipe处理一些大文件。如果外部存储中的小文件没有合并在一起,成本可能会增加。
- 在生产环境中,确保创建自动化流程来监控流,因为一旦流变得过期,就无法从中恢复数据。
- 单个JSON文档允许的最大压缩大小为16MB,可以加载到Snowflake中。如果您有超过这些大小限制的大型JSON文档,请确保在将其加载到Snowflake之前对其进行拆分。
结论
由于嵌入在JSON文档中的元素的嵌套结构,管理半结构化数据始终具有挑战性。在设计最终的报表层之前,请考虑到传入数据量的逐渐和指数增加。本文旨在演示如何使用半结构化数据构建流式传输管道的简易性。
Milind Chaudhari是一位经验丰富的数据工程师/数据架构师,拥有使用各种传统和现代工具构建数据湖/数据湖仓库的十年工作经验。他对数据流架构非常热衷,并且还是Packt和O’Reilly的技术审稿人。