解码声音的交响乐:音乐工程的音频信号处理
Decoding Sound Audio Signal Processing in Music Engineering
使用Python进行时间和频率域音频特征提取的终极指南

目录
- 介绍
- 时间域特征提取2.1 音频信号处理基础:帧大小和跳跃长度2.2 特征1:幅度包络2.3 特征2:均方根能量2.4 特征3:峰值因数2.5 特征4:过零率
- 频率域特征提取3.1 特征5:频带能量比3.2 特征6:谱心3.3 特征7:频谱带宽3.4 特征8:频谱平坦度
- 结论
- 参考文献
介绍
在信息时代,处理和分析不同类型的数据以获得实际见解是最重要的技能之一。数据无处不在:从我们阅读的书籍到我们观看的电影,从我们喜欢的Instagram帖子到我们听的音乐。在本文中,我们将尝试理解音频信号处理的基础知识:
- 计算机如何读取音频信号
- 时间域和频率域特征是什么?
- 这些特征是如何提取的?
- 为什么需要提取这些特征?
特别是,我们将详细介绍以下特征:
- 时间域特征:幅度包络、均方根能量、峰值因数(和峰均功率比)、过零率。
- 频率域特征:频带能量比、谱心、频谱带宽(扩散度)、频谱平坦度。
我们将描述理论并从头开始编写Python代码,以提取这些特征用于来自三种不同乐器(原声吉他、铜管乐器和鼓组)的音频信号。使用的示例音频数据文件可以在此处下载:https://github.com/namanlab/Audio-Signal-Processing-Feature-Extraction
整个代码文件也可以在上述存储库中找到,或通过此链接访问:https://github.com/namanlab/Audio-Signal-Processing-Feature-Extraction/blob/main/Audio_Signal_Extraction.ipynb
时间域特征提取
让我们首先回顾一下声音是什么以及我们如何感知声音。正如你们中的一些人可能还记得高中课程中所讲的,声音是通过VoAGI传播的振动。声音的产生使得周围的空气分子振动,这表现为交替的压缩区域(高压)和稀疏区域(低压)。这些压缩和稀疏通过VoAGI传播并达到我们的耳朵,使我们能够感知声音的方式。因此,声音的传播涉及随时间传输这些压力变化。声音的时间域表示涉及在不同时间间隔内捕获和分析这些压力变化,通过在离散的时间点上对声波进行采样(通常使用数字音频记录技术)。每个样本表示特定时刻的声压水平。通过绘制这些样本,我们可以得到一个波形图,显示声压水平随时间的变化。水平轴表示时间,垂直轴表示声音的幅度或强度,通常缩放到-1到1之间,其中正值表示压缩,负值表示稀疏。这有助于我们对声波的特性进行可视化表示,例如其幅度、频率和持续时间。
![声音传播基础[图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*73LlzPPzLmX6DsLrFVheeA.jpeg)
为了使用Python提取给定音频的波形,我们首先加载所需的包:
import numpy as npimport matplotlib.pyplot as pltimport librosaimport librosa.displayimport IPython.display as ipdimport scipy as sppNumPy是一个流行的Python包,用于处理和操作数组和矩阵。它包含了从线性代数到简化许多任务的各种工具!
librosa是Python的音频处理和分析包,包含了多种函数和工具,使得利用不同种类的音频特征变得非常容易。如前所述,我们将分析三种不同的乐器的波形:木吉他、铜管和鼓套。您可以从之前分享的链接下载音频文件并将其上传到本地代码库。为了听取音频文件,我们使用IPython.display。代码如下:
# 听取音频文件
# 确保正确的相对/绝对路径到音频文件。
acoustic_guitar_path = "acoustic_guitar.wav"
ipd.Audio(acoustic_guitar_path)
brass_path = "brass.wav"
ipd.Audio(brass_path)
# 音量保持较低!
drum_set_path = "drum_set.wav"
ipd.Audio(drum_set_path)接下来,我们使用librosa中的librosa.load()函数加载音乐文件。该函数允许我们解析音频文件并返回两个对象:
- y(NumPy数组):包含不同时间间隔的振幅值。尝试打印该数组以查看结果!
- sr(大于0的数字):采样率
采样率指的是在将模拟信号转换为数字表示时,每单位时间采集的样本数。如上所述,VoAGI上的压力变化构成了模拟信号,这种信号的波形在时间上不断变化。理论上,存储连续数据将需要无限的空间。因此,为了处理和存储这些模拟信号的数字表示,需要将它们转换为离散表示。这就是采样的作用,它在离散(均匀间隔)的时间间隔内捕获声波的截图。这些间隔之间的间距由采样率的倒数来表示。
采样率确定从模拟信号中多频采样,并且因此以每秒样本数或赫兹(Hz)来衡量。较高的采样率意味着每秒采集更多的样本,从而更准确地表示原始模拟信号,但需要更多的内存资源。相反,较低的采样率意味着每秒采集更少的样本,从而对原始模拟信号的表示不太准确,但需要更少的内存资源。
通常默认的采样率是22050。然而,根据应用程序/内存,用户可以选择更低或更高的采样率,可以通过librosa.load()函数的sr参数来指定。在选择用于模拟到数字转换的适当采样率时,了解奈奎斯特-香农采样定理可能很重要。该定理指出,为了准确地捕获和重构模拟信号,采样率必须至少是音频信号中存在的最高频率成分的两倍(称为奈奎斯特速率/频率)。

通过以高于奈奎斯特频率的频率进行采样,我们可以避免一种称为混叠的现象,该现象可能会扭曲原始信号。对于本文的目的,混叠的讨论并不特别相关。如果您对此感兴趣,可以阅读更多关于它的内容,请参阅以下优秀资源:https://thewolfsound.com/what-is-aliasing-what-causes-it-how-to-avoid-it/
以下是读取音频信号的代码:
# 在librosa中加载音乐
sr = 22050
acoustic_guitar, sr = librosa.load(acoustic_guitar_path, sr=sr)
brass, sr = librosa.load(brass_path, sr=sr)
drum_set, sr = librosa.load(drum_set_path, sr=sr)在上面的示例中,采样率被设置为22050(也是默认采样率)。执行上述代码将返回3个数组,每个数组存储离散时间间隔内的振幅值(由采样率指定)。接下来,我们使用librosa.display.waveshow()可视化每个音频样本的波形。为了更清晰地可视化振幅在时间上的密度,我们添加了一些透明度(通过设置alpha=0.5)。
def show_waveform(signal, name=""):
# 创建一个具有特定大小的新图形
plt.figure(figsize=(15, 7))
# 使用librosa显示信号的波形
librosa.display.waveshow(signal, alpha=0.5)
# 设置图形的标题
plt.title("Waveform for " + name)
# 显示图形
plt.show()
show_waveform(acoustic_guitar, "Acoustic Guitar")
show_waveform(brass, "Brass")
show_waveform(drum_set, "Drum Set")![声学吉他的波形 [图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*Kf0MmP8_mqIZUyBRxgjHAA.png)
![铜管的波形 [图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*AY_urpb3jkZyrs7DwIEwRg.png)
![鼓组的波形 [图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*1VDVlwQ_W_FKFgr1HPMoCA.png)
请花些时间来审查上述绘图。思考你所看到的模式。在声学吉他的波形中,我们可以识别出一个周期性模式,其特点是振幅的定期振荡,这反映了吉他声音的丰富和谐性。这些振荡对应于弹拨弦产生的振动,生成了一个由多个谐波组成的复杂波形,为吉他的特征音调和音色做出了贡献。
同样,铜管的波形也表现出周期性模式,导致音高和音色一致。铜管乐器通过将音乐家的嘴唇嘴对口罩产生声音。这种嘴唇振动产生了具有明显谐波和振幅变化规律的波形。
相比之下,鼓组的波形没有显示出明显的周期性模式,因为鼓是通过鼓槌或手对鼓面或其他打击面的冲击产生声音,从而产生复杂且不规则的波形,振幅和持续时间各异。无法识别出明显的周期性模式反映了鼓声的打击和非音调特性。
音频信号处理基础:帧大小和跳跃长度
在讨论重要的时域音频特征之前,有必要讨论两个重要的特征提取参数:帧大小和跳跃长度。通常,一旦信号被数字处理,它就会被分成帧(一组离散的时间间隔,可以重叠也可以不重叠)。帧长度描述了这些帧的大小,而跳跃长度则包含了帧之间的重叠程度的信息。但是,为什么分帧很重要呢?
分帧的目的是捕捉信号不同特征的时间变化。通常的特征提取方法会给出输入信号的一个数值摘要(例如均值、最小值或最大值)。直接使用这些特征提取方法的问题在于完全消除了与时间相关的任何信息。例如,如果你想计算信号的均值振幅,你得到一个单一的数值摘要,比如 x。然而,自然地,均值较小的时间间隔和均值较大的时间间隔是存在的。取一个单一的数值摘要会消除关于均值的时间变化的任何信息。解决方案是将信号分成帧,例如 [0 ms,10 ms),[10 ms,20 ms),…然后在每个时间帧的信号部分计算均值,这些收集到的特征集合给出了最终提取的特征向量,这是一个时间相关的特征摘要,是不是很酷!
现在,让我们详细讨论这两个参数:
- 帧大小:描述每个帧的大小。例如,如果帧大小是1024,你在每个帧中包含1024个样本,并计算这些1024个样本的所需特征。通常建议将帧大小设置为2的幂。这个原因对本文来说并不重要。但是如果你感兴趣,这是因为快速傅里叶变换(一种将信号从时域变换到频域的非常高效的算法)需要帧的大小是2的幂次方。我们将在后续章节中更多地讨论傅里叶变换。
- 跳跃长度:指帧在数据序列中每一步向前推进的样本数,即在生成新帧之前向右移动的样本数。可以将帧视为在信号中移动的滑动窗口,步长由跳跃长度定义。在每个步骤中,窗口被应用于信号或序列的一个新部分,并在该段上执行特征提取。因此,跳跃长度决定了连续音频帧之间的重叠。跳跃长度等于帧大小意味着没有重叠,因为每个帧都恰好从前一个帧结束的地方开始。然而,为了减轻一种叫做频谱泄漏的现象的影响(在将信号从其时域转换为频域时发生),会应用窗函数,结果是在每个帧的边缘丢失数据(技术解释超出本文的目的,但如果你感兴趣,可以查看这个链接:https://dspillustrations.com/pages/posts/misc/spectral-leakage-zero-padding-and-frequency-resolution.html)。因此,通常选择中间的跳跃长度以保留边缘样本,从而导致帧之间有不同程度的重叠。
一般来说,较小的跳跃长度提供了更高的时间分辨率,使我们能够捕捉到信号中更多的细节和快速变化。然而,它也增加了内存需求。相反,较大的跳跃长度降低了时间分辨率,但也有助于减少空间复杂度。
![Frame Size and Hop Length [Image by Author]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*6jeBOA2R3sXcNADsXfEjuQ.png)
注意:为了更清楚地显示,上图中的帧大小显示得很大。实际上,所选择的帧大小要小得多(可能是几千个样本,大约20-40毫秒)。
在继续进行时域不同特征提取方法之前,让我们澄清一些数学符号。本文将在整个文章中使用以下符号:
- xᵢ: 第i个样本的振幅
- K: 帧大小
- H: 跳跃长度
特征1:振幅包络
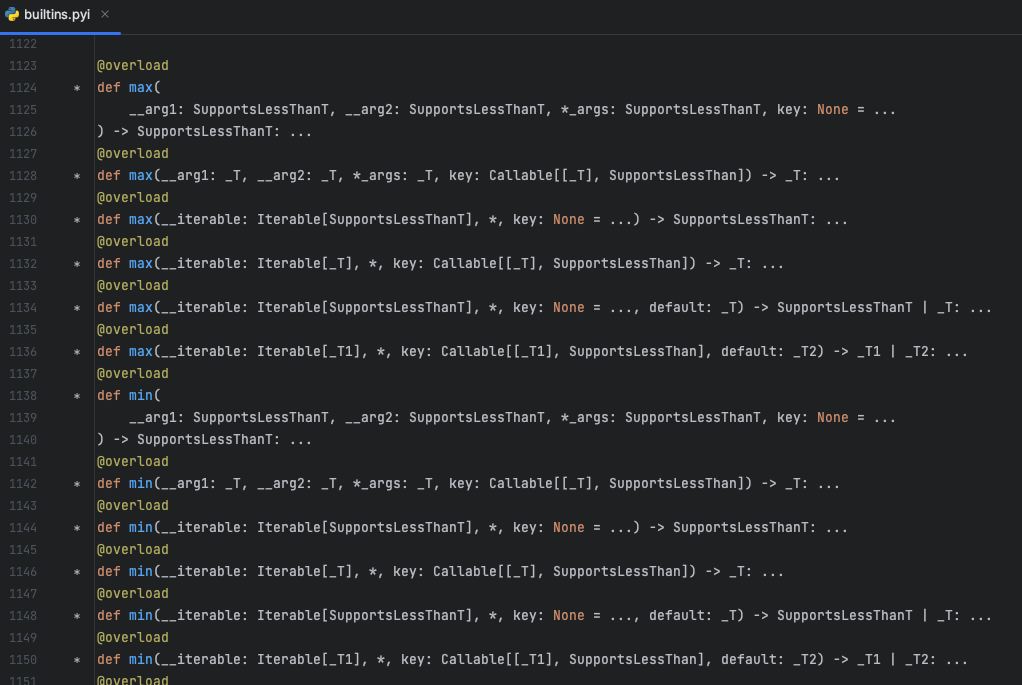
首先,让我们谈谈振幅包络。这是时域分析中最容易计算(但非常有用)的特征之一。音频信号的一个帧的振幅包络简单地是该帧中振幅的最大值。数学上,(对于非重叠的帧)第k个帧的振幅包络由以下公式给出:

一般地,对于包含样本xⱼ₁,xⱼ₂,· · ·,xⱼₖ的任何帧k,振幅包络为:
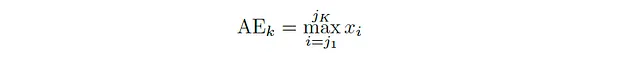
计算给定信号的振幅包络的Python代码如下:
FRAME_SIZE = 1024HOP_LENGTH = 512def amplitude_envelope(signal, frame_size=1024, hop_length=512): """ 使用滑动窗口计算信号的振幅包络。 参数: signal(数组):输入信号。 frame_size(int):每帧的大小(样本数)。 hop_length(int):连续帧之间的样本数。 返回: np.array:振幅包络值的数组。 """ res = [] for i in range(0, len(signal), hop_length): # 获取信号的一部分 cur_portion = signal[i:i + frame_size] # 计算部分中的最大值 ae_val = max(cur_portion) # 存储振幅包络值 res.append(ae_val) # 将结果转换为NumPy数组 return np.array(res)def plot_amplitude_envelope(signal, name, frame_size=1024, hop_length=512): """ 绘制带有振幅包络值的信号波形。 参数: signal(数组):输入信号。 name(str):绘图标题的信号名称。 frame_size(int):每帧的大小(样本数)。 hop_length(int):连续帧之间的样本数。 """ # 计算振幅包络 ae = amplitude_envelope(signal, frame_size, hop_length) # 生成帧索引 frames = range(0, len(ae)) # 将帧转换为时间 time = librosa.frames_to_time(frames, hop_length=hop_length) # 创建一个具有特定大小的新图形 plt.figure(figsize=(15, 7)) # 显示信号的波形 librosa.display.waveshow(signal, alpha=0.5) # 绘制随时间变化的振幅包络 plt.plot(time, ae, color="r") # 设置绘图标题 plt.title("Waveform for " + name + " (Amplitude Envelope)") # 显示绘图 plt.show() plot_amplitude_envelope(acoustic_guitar, "Acoustic Guitar")plot_amplitude_envelope(brass, "Brass")plot_amplitude_envelope(drum_set, "Drum Set")在上面的代码中,我们定义了一个名为amplitude_envelope的函数,该函数接受输入信号数组(使用librosa.load()生成),帧大小(K)和跳跃长度(H),并返回一个大小与帧数相等的数组。数组中的第k个值对应于第k个帧的幅度包络值。计算是使用一个简单的for循环完成的,该循环通过整个信号进行迭代,步长由跳跃长度确定。定义了一个列表(res)来存储这些值,并在返回之前最终转换为NumPy数组。另外定义了一个名为plot_amplitude envelope的函数,该函数接受相同的输入集合(以及一个name参数),并将幅度包络的绘图覆盖在原始帧上。为了绘制波形,使用了传统的librosa.display.waveform(),如前一节所述。
为了绘制幅度包络,我们需要时间和相应的幅度包络值。时间值是使用非常有用的函数librosa.frames_to_times()获得的,该函数接受两个输入:与帧数对应的可迭代对象(使用range函数定义),和跳跃长度),以生成每个帧的平均时间。随后使用matplotlib.pyplot来叠加红色的绘图。上述描述的过程将始终用于所有时域特征提取方法。
以下图示显示了每个乐器的计算幅度包络。它们作为红线添加到原始波形上,并且倾向于逼近波形的上限。幅度包络不仅保留了周期模式,而且还反映了铜管乐器相对于木吉他和鼓组的较低强度中的音频振幅的一般差异。
![Acoustic Guitar的幅度包络[图像由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*-ruXOgSVNITu35WV0yuAtw.png)
![Brass的幅度包络[图像由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*NhwUexulu7bWENkWEbr5XQ.png)
![Drum Set的幅度包络[图像由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*yi2fVD67-CZ_b2kL6VfLmg.png)
特征2:均方根能量
接下来,让我们谈谈均方根能量(RMSE),这是时域分析中的另一个重要特征。音频信号的一个帧的均方根能量是通过对帧中所有幅度值的平方求平均值,然后取平方根得到的。在数学上,第k个帧的均方根能量(对于非重叠帧)如下所示:
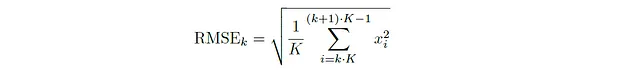
通常情况下,对于包含样本xⱼ₁,xⱼ₂,···,xⱼₖ的任何帧k,RMSE是:

均方根能量通过考虑波形的正向和负向波动来提供声音信号整体强度或强度的表示,与其他测量值(如峰值幅度)相比,提供了更准确的信号功率测量。计算给定信号的RMSE的Python代码如下所示。代码的结构与生成幅度包络的结构相同。唯一的变化是用于提取特征的函数。计算RMSE值时,不是使用最大值,而是通过计算信号当前部分的平方值的平均值,然后再取平方根。
def RMS_energy(signal, frame_size=1024, hop_length=512): """ 使用滑动窗口计算信号的RMS(均方根)能量。 Args: signal(array):输入信号。 frame_size(int):每个帧的大小(以样本为单位)。 hop_length(int):连续帧之间的样本数。 Returns: np.array:RMS能量值的数组。 """ res = [] for i in range(0, len(signal), hop_length): # 提取信号的一部分 cur_portion = signal[i:i + frame_size] # 计算该部分的RMS能量 rmse_val = np.sqrt(1 / len(cur_portion) * sum(i**2 for i in cur_portion)) res.append(rmse_val) # 将结果转换为NumPy数组 return np.array(res)def plot_RMS_energy(signal, name, frame_size=1024, hop_length=512): """ 绘制带有RMS能量值覆盖的信号波形。 Args: signal(array):输入信号。 name(str):绘图标题的信号名称。 frame_size(int):每个帧的大小(以样本为单位)。 hop_length(int):连续帧之间的样本数。 """ # 计算RMS能量 rmse = RMS_energy(signal, frame_size, hop_length) # 生成帧索引 frames = range(0, len(rmse)) # 将帧转换为时间 time = librosa.frames_to_time(frames, hop_length=hop_length) # 创建一个具有特定大小的新图形 plt.figure(figsize=(15, 7)) # 将波形显示为类似于频谱图的绘图 librosa.display.waveshow(signal, alpha=0.5) # 绘制RMS能量值 plt.plot(time, rmse, color="r") # 设置绘图的标题 plt.title("Waveform for " + name + " (RMS Energy)") plt.show()plot_RMS_energy(acoustic_guitar, "Acoustic Guitar")plot_RMS_energy(brass, "Brass")plot_RMS_energy(drum_set, "Drum Set")以下图片显示了每个乐器的计算均方根能量。它们被添加为红色线条覆盖在原始波形上,并且趋向于近似波形的质心。与之前一样,这个测量不仅保留了周期模式,还近似了声波的整体强度水平。
![RMSE for Acoustic Guitar [Image by Author]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*mKwBIq_5NMQ-QW-xd6T72Q.png)
![RMSE for Brass [Image by Author]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*eZWBylUC8FxqTS3jQnI9tw.png)
![RMSE for Drum Set [Image by Author]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*WRDjgDkjMjTGC9ha87fWZw.png)
特征 3: 峰值系数
现在,让我们谈谈峰值系数,它是波形中峰值的极端程度的度量。音频信号帧的峰值系数通过将峰值幅度(振幅的最大绝对值)除以均方根能量来获得。数学上,第 k 个帧的峰值系数(对于非重叠帧)如下所示:

一般来说,对于包含样本 xⱼ₁ , xⱼ₂ , · · · , xⱼₖ 的任意帧 k,峰值系数为:

峰值系数表示波形的最高峰值水平和平均强度水平之间的比率。计算给定信号的峰值系数的 Python 代码如下所示。其结构与上述类似,涉及计算均方根能量(分母)和最高峰值(分子),然后用于获得所需的分数(峰值系数!)。
def crest_factor(signal, frame_size=1024, hop_length=512): """ 使用滑动窗口计算信号的峰值系数。 参数: signal (array): 输入信号。 frame_size (int): 每个帧的样本大小。 hop_length (int): 连续帧之间的样本数。 返回: np.array: 峰值系数值的数组。 """ res = [] for i in range(0, len(signal), hop_length): # 获取信号的一部分 cur_portion = signal[i:i + frame_size] # 计算该部分的均方根能量 rmse_val = np.sqrt(1 / len(cur_portion) * sum(i ** 2 for i in cur_portion)) # 计算峰值系数 crest_val = max(np.abs(cur_portion)) / rmse_val # 存储峰值系数值 res.append(crest_val) # 将结果转换为 NumPy 数组 return np.array(res) def plot_crest_factor(signal, name, frame_size=1024, hop_length=512): """ 绘制信号的峰值系数随时间的变化。 参数: signal (array): 输入信号。 name (str): 图表标题的信号名称。 frame_size (int): 每个帧的样本大小。 hop_length (int): 连续帧之间的样本数。 """ # 计算峰值系数 crest = crest_factor(signal, frame_size, hop_length) # 生成帧索引 frames = range(0, len(crest)) # 将帧转换为时间 time = librosa.frames_to_time(frames, hop_length=hop_length) # 创建一个指定大小的新图表 plt.figure(figsize=(15, 7)) # 绘制峰值系数随时间的变化 plt.plot(time, crest, color="r") # 设置图表的标题 plt.title(name + " (峰值系数)") # 显示图表 plt.show() plot_crest_factor(acoustic_guitar, "声学吉他")plot_crest_factor(brass, "铜管")plot_crest_factor(drum_set, "鼓套")以下的图显示了每个乐器的计算峰值因子:
![声学吉他的峰值因子 [图像由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*OXJqmGmFU2pq1yaYrG3mHQ.png)
![铜管的峰值因子 [图像由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*ic8zGIUhRa-nz3pOssyUFA.png)
![铜管套装的峰值因子 [图像由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*uo2ACou50jdvkmETLVS7Iw.png)
如声学吉他和铜管所示,更高的峰值因子表示峰值水平和平均水平之间的差异较大,表明振幅存在更大的动态变化或尖锐信号。较低的峰值因子,如鼓套装所示,表示振幅变化较小,信号更加均匀或压缩。峰值因子在必须考虑系统可用动态范围或剩余空间的情况下特别重要。例如,在音乐录制中,高峰值因子可能需要仔细考虑,以防止在具有有限剩余空间的设备上播放时出现失真或剪切。
实际上,还有一个与峰值因子密切相关的特征称为峰均功率比(PAPR)。PAPR只是峰值因子的平方值,通常转换为分贝功率比。一般来说,对于包含样本xⱼ₁,xⱼ₂,···,xⱼₖ的任何帧k,峰均功率比为:

作为一个有趣的挑战,尝试修改上述代码以生成每个乐器的PAPR图并分析您的发现。
特征4:过零率
最后,我们将讨论过零率(ZCR)。音频信号的一个帧的过零率简单地是信号穿过零点(x/时间轴)的次数。数学上,第k帧(对于非重叠帧)的ZCR由以下公式给出:

如果连续的值具有相同的符号,则绝对值内的表达式将抵消,得到0。如果它们具有相反的符号(表示信号已经穿过时间轴),则值相加得到2(取绝对值后)。由于每个过零点给出一个值为2,我们将结果乘以一半的因子以获得所需的计数。一般来说,对于包含样本xⱼ₁,xⱼ₂,···,xⱼₖ的任何帧k,ZCR为:

请注意,上述表达式中,通过简单地累加信号穿越轴的次数来计算过零率。然而,根据应用程序的不同,也可以对值进行归一化(通过除以帧的长度)。计算给定信号的峰值因子的Python代码如下所示。结构遵循上述内容,其中还定义了一个名为num sign changes的函数,用于确定给定信号中的符号变化次数。
def ZCR(signal, frame_size=1024, hop_length=512): """ 使用滑动窗口计算信号的过零率(ZCR)。 参数: signal (数组): 输入信号。 frame_size (整数): 每个帧的样本数。 hop_length (整数): 连续帧之间的样本数。 返回值: np.array: 过零率值的数组。 """ res = [] for i in range(0, len(signal), hop_length): # 获取信号的一部分 cur_portion = signal[i:i + frame_size] # 计算该部分中的符号变化次数 zcr_val = num_sign_changes(cur_portion) # 存储过零率值 res.append(zcr_val) # 将结果转换为NumPy数组 return np.array(res) def num_sign_changes(signal): """ 计算信号中的符号变化次数。 参数: signal (数组): 输入信号。 返回值: 整数: 符号变化次数。 """ res = 0 for i in range(0, len(signal) - 1): # 检查连续样本之间是否存在符号变化 if (signal[i] * signal[i + 1] < 0): res += 1 return resdef plot_ZCR(signal, name, frame_size=1024, hop_length=512): """ 绘制信号的过零率(ZCR)随时间的变化。 参数: signal (数组): 输入信号。 name (字符串): 绘图标题的信号名称。 frame_size (整数): 每个帧的样本数。 hop_length (整数): 连续帧之间的样本数。 """ # 计算过零率 zcr = ZCR(signal, frame_size, hop_length) # 生成帧索引 frames = range(0, len(zcr)) # 转换帧为时间 time = librosa.frames_to_time(frames, hop_length=hop_length) # 创建具有特定大小的新图形 plt.figure(figsize=(15, 7)) # 绘制过零率随时间的变化 plt.plot(time, zcr, color="r") # 设置图形的标题 plt.title(name + " (过零率)") # 显示图形 plt.show() plot_ZCR(acoustic_guitar, "声学吉他")plot_ZCR(brass, "铜管")plot_ZCR(drum_set, "鼓套装")以下是每个乐器的计算过零率的图表。
![木吉他的过零率 [图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*jIW9ZcSzwnANrDp9tWL7bw.png)
![铜管乐器的过零率 [图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*8rUxSjDDA95_GSZ_oQRL9Q.png)
较高的过零率表明信号频繁改变方向,表明存在较高频率成分或更动态的波形。相反,较低的过零率表示相对平滑或恒定的波形。
过零率在语音和音乐分析的应用中特别有用,因为它能够提供关于音色和节奏模式等特性的洞察力。例如,在语音分析中,过零率有助于区分有声和无声音,因为由于声带的振动,有声音倾向于具有更高的过零率。必须注意的是,虽然过零率是一个简单且计算效率高的特征,但它可能无法捕捉信号复杂性的所有方面(正如您在上述图表中可以看到的,周期性完全丢失)。因此,它通常与其他特征结合使用,以对音频信号进行更全面的分析。
频域特征提取
频域提供了音频波的另一种表示方式。与时域不同,在时域中,信号是作为时间的函数表示,在频域中,信号被分解为其组成频率,显示了与每个频率相关的幅度和相位信息,即信号被作为频率的函数表示。我们不再关注信号在不同时间点的幅度,而是检查构成信号的不同频率分量的幅度。每个频率分量表示具有特定频率的正弦波,通过组合这些分量,我们可以在时域中重建原始信号。
将信号从时域转换为频域的(最常见的)数学工具是傅里叶变换。傅里叶变换将信号作为输入,并将其分解为具有不同频率的正弦和余弦波的总和,这些波具有自己的幅度和相位。得到的表示就是频谱。在数学上,连续信号在其时域g(t)中的傅里叶变换定义如下:

其中i = √−1是虚数。是的,傅里叶变换产生一个复数输出,其中相位和幅度对应于构成正弦波的相位和幅度!然而,对于大多数应用程序,我们只关心变换的幅度,并简单地忽略相关的相位。由于数字处理的声音是离散的,我们可以定义类似的离散傅里叶变换(DFT):

其中T是一个样本的持续时间。从采样率的角度来看:

由于频率表示也是连续的,我们在离散化的频率区间上评估傅里叶变换,以获得音频波的离散频域表示。这称为短时傅里叶变换。在数学上,

不要着急!让我们仔细复习一下。帽子函数 h(k) 是一个将整数 k ∈ {0, 1, · · · , N − 1} 映射到频率 k · Sᵣ/N 的幅度的函数。请注意,我们只考虑离散频率的整数倍的频率箱,其中 N 是信号中的样本数。如果您对此如何工作仍然不确定,这里有一个关于傅立叶变换的优秀解释:https://www.youtube.com/watch?v=spUNpyF58BY&t=393s
傅立叶变换是最美的数学创新之一,所以了解它是值得的,尽管讨论与本文的目的并不特别相关。在Python中,您可以使用librosa.stft()轻松获得短时傅立叶变换。
注意:对于大型音频数据,有一种更高效的计算傅立叶变换的方法,称为快速傅立叶变换(FFT),如果您感兴趣,可以自行查看!
与之前一样,我们不仅对哪些频率更为主导感兴趣:我们还想展示这些频率何时主导。因此,我们寻求一种同时显示哪些频率在什么时间点主导的频率-时间表示。这就是分帧的作用:我们将信号分成时间帧,并在每个帧中获取结果傅立叶变换的幅度。这给我们提供了一个值矩阵,其中行数由频率箱的数量(Φ,通常等于 K/2 + 1,其中 K 是帧大小)确定,列数由帧数确定。由于傅立叶变换的输出是复值,所以生成的矩阵是复值的。在Python中,帧大小和跳跃长度参数可以很容易地作为参数指定,并且可以使用librosa.stft(signal, n fft=frame size, hop length=hop length)简单地计算出结果矩阵。由于我们只关心幅度,我们可以使用numpy.abs()将复值矩阵转换为实值矩阵。将获得的矩阵绘制出来非常方便,这样可以以视觉上引人入胜的方式呈现给定声音的频率内容和时间特征。这种所谓的表示称为谱图。
谱图是通过将时间帧绘制在x轴上,将频率箱绘制在y轴上获得的。然后使用颜色来指示给定时间帧的频率的强度或幅度。通常,将频率轴转换为对数刻度(因为人类已知在对数变换下更好地感知它们),并以分贝表示幅度。
生成谱图的Python代码如下:
FRAME_SIZE = 1024HOP_LENGTH = 512def plot_spectrogram(signal, sample_rate, frame_size=1024, hop_length=512): """ 绘制音频信号的谱图。 参数: signal(类似数组):输入音频信号。 sample_rate(int):音频信号的采样率。 frame_size(int):每个帧的大小(以样本为单位)。 hop_length(int):连续帧之间的样本数。 """ # 计算STFT spectrogram = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length) # 将STFT转换为dB刻度 spectrogram_db = librosa.amplitude_to_db(np.abs(spectrogram)) # 创建一个具有特定大小的新图形 plt.figure(figsize=(15, 7)) # 显示谱图 librosa.display.specshow(spectrogram_db, sr=sample_rate, hop_length=hop_length, x_axis='time', y_axis='log') # 添加一个色标以显示幅度刻度 plt.colorbar(format='%+2.0f dB') # 设置图形的标题 plt.title('谱图') # 设置x轴的标签 plt.xlabel('时间') # 设置y轴的标签 plt.ylabel('频率(Hz)') # 调整图形的布局 plt.tight_layout() # 显示图形 plt.show() plot_spectrogram(acoustic_guitar, sr)plot_spectrogram(brass, sr)plot_spectrogram(drum_set, sr)在上面的代码中,我们定义了一个名为plot_spectrogram的函数,它接受4个参数:输入信号数组、采样率、帧大小和跳跃长度。首先,使用librosa.stft()获取谱图矩阵。随后,使用np.abs()提取幅度,然后使用函数librosa.amplitude_to_db()将振幅值转换为分贝。最后,使用函数librosa.display.specshow()绘制谱图。该函数接受转换后的谱图矩阵、采样率、跳跃长度以及x轴和y轴的规格。可以使用y轴=’log’参数指定对数变换的y轴。可以使用plt.colorbar()添加一个可选的色标。下面显示了三种乐器的谱图结果:
![声学吉他的频谱图[图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*cs5iAD0d6SIAjt4TxYrTfA.png)
![铜管的频谱图[图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*GUnA6RZXx8RA1T2dlnKhVw.png)
![鼓套的频谱图[图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*JjFO1kDacts055p-u241GQ.png)
频谱图提供了一种独特的视觉化时间-频率权衡的方式。时间域为我们提供了一个精确的表示信号随时间演变的方式,而频率域则允许我们看到能量在不同频率上的分布。这使我们不仅能够识别特定频率的存在,还能帮助我们理解它们的持续时间和时间变化。频谱图是表示声音的最有用的方式之一,并且经常用于音频信号的机器学习应用中(例如,将声波的频谱图输入到深度卷积神经网络中进行预测)。
在继续介绍不同的频域特征提取方法之前,让我们明确一些数学符号。我们将使用以下符号来表示后续的部分:
- mₖ(i):第k帧中第i个频率的振幅。
- K:帧大小
- H:跳跃长度
- Φ:频率间隔的数量(= K/2 + 1)
特征5:带能量比
首先,让我们讨论一下带能量比。带能量比是用来量化给定时间帧中低频能量与高频能量之间比值的度量。数学上,对于任何帧k,带能量比为:
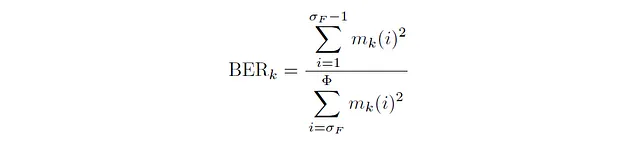
其中σբ表示分裂频率:用于区分低频与高频的参数。在计算带能量比时,所有低于σբ(称为分裂频率)对应频率的值都被视为低频。这些频率的平方能量之和确定了分子。类似地,所有高于分裂频率的值被视为高频,这些频率的平方能量之和确定了分母。计算信号的带能量比的Python代码如下所示:
def find_split_freq_bin(spec, split_freq, sample_rate, frame_size=1024, hop_length=512): """ 计算给定分裂频率对应的频率间隔的索引。 参数: spec(数组):频谱图。 split_freq(浮点数):分裂频率(以赫兹为单位)。 sample_rate(整数):音频的采样率。 frame_size(整数,可选):每个帧的大小(以样本为单位)。默认为1024。 hop_length(整数,可选):连续帧之间的样本数。默认为512。 返回: 整数:对应于分裂频率的频率间隔的索引。 """ # 计算频率的范围 range_of_freq = sample_rate / 2 # 计算每个频率间隔的频率变化 change_per_bin = range_of_freq / spec.shape[0] # 计算对应于分裂频率的频率间隔的索引 split_freq_bin = split_freq / change_per_bin return int(np.floor(split_freq_bin))def band_energy_ratio(signal, split_freq, sample_rate, frame_size=1024, hop_length=512): """ 计算信号的带能量比(BER)。 参数: signal(数组):输入信号。 split_freq(浮点数):分裂频率(以赫兹为单位)。 sample_rate(整数):音频的采样率。 frame_size(整数,可选):每个帧的大小(以样本为单位)。默认为1024。 hop_length(整数,可选):连续帧之间的样本数。默认为512。 返回: ndarray:信号每个帧的带能量比。 """ # 计算信号的频谱图 spec = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length) # 找到对应于分裂频率的频率间隔的索引 split_freq_bin = find_split_freq_bin(spec, split_freq, sample_rate, frame_size, hop_length) # 提取幅度并转置 modified_spec = np.abs(spec).T res = [] for sub_arr in modified_spec: # 计算低频范围内的能量 low_freq_density = sum(i ** 2 for i in sub_arr[:split_freq_bin]) # 计算高频范围内的能量 high_freq_density = sum(i ** 2 for i in sub_arr[split_freq_bin:]) # 计算带能量比 ber_val = low_freq_density / high_freq_density res.append(ber_val) return np.array(res)def plot_band_energy_ratio(signal, split_freq, sample_rate, name, frame_size=1024, hop_length=512): """ 绘制信号随时间的带能量比(BER)。 参数: signal(ndarray):输入信号。 split_freq(浮点数):分裂频率(以赫兹为单位)。 sample_rate(整数):音频的采样率。 name(字符串):绘图标题的信号名称。 frame_size(整数,可选):每个帧的大小(以样本为单位)。默认为1024。 hop_length(整数,可选):连续帧之间的样本数。默认为512。 """ # 计算带能量比(BER) ber = band_energy_ratio(signal, split_freq, sample_rate, frame_size, hop_length) # 生成帧索引 frames = range(0, len(ber)) # 将帧转换为时间 time = librosa.frames_to_time(frames, hop_length=hop_length) # 创建具有特定大小的新图像 plt.figure(figsize=(15, 7)) # 绘制随时间的带能量比(BER) plt.plot(time, ber) # 设置绘图标题 plt.title(name + "(带能量比)") # 显示绘图 plt.show() plot_band_energy_ratio(acoustic_guitar, 2048, sr, "声学吉他")plot_band_energy_ratio(brass, 2048, sr, "铜管")plot_band_energy_ratio(drum_set, 2048, sr, "鼓套")上述代码的结构与时域提取的相似。第一步是定义一个名为find_split_freq_bin()的函数,该函数接受声谱图、分割频率的值和采样率作为参数,确定与分割频率对应的分割频率bin (σբ)。这个过程非常简单。它涉及找到频率范围(即纳奎斯特频率,Sᵣ/2)。频率bin的数量由声谱图的行数给出,可以通过spec.shape[0]提取。将频率范围总数除以频率bin的数量,我们可以计算出每个bin的频率变化量,将其除以给定的分割频率,就可以确定分割频率bin。
接下来,我们使用这个函数来计算带能量比向量。函数band_energy_ratio()接受输入信号、分割频率、采样率、帧大小和跳跃长度作为参数。首先,它使用librosa.stft()提取声谱图,然后计算分割频率bin。接下来,使用np.abs()计算声谱图的幅度,然后进行转置以便在每个帧上进行迭代。在迭代过程中,使用定义好的公式和找到的分割频率bin计算每个帧的带能量比。这些值存储在一个列表res中,最后作为NumPy数组返回。最后,使用plot_band_energy_ratio()函数绘制这些值。
下面显示了三种乐器的带能量比图。对于这些图,分割频率选择为2048 Hz,即2048 Hz以下的频率被认为是低能量频率,而以上的频率被认为是高能量频率。
![Acoustic Guitar的带能量比 [作者提供的图片]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*Fk1Y0M9l7nYkX3wzHEbluA.png)
![Brass的带能量比 [作者提供的图片]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*dgHIkYXnmbp9fs02Kwr8JQ.png)
![Drum Set的带能量比 [作者提供的图片]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*IHpTCLmDdEPOKXlmpJ6GOw.png)
高带能量比(对于铜管乐器)表示较低频率分量相对于较高频率分量的存在更多。因此,我们观察到铜管乐器在较低频段产生了相当大量的能量,相对于较高频段而言。与铜管乐器相比,原声吉他的BER较低,表明相对于较高频段,较低频段的能量贡献较少。总的来说,原声吉他在频谱上有一个更平衡的能量分布,相对于其他乐器,较低频率的重视程度较低。最后,鼓组在这三种乐器中的BER最低,相对于其他乐器,在较低频段的能量贡献较低。
特征6:频谱质心
接下来,我们将讨论频谱质心,它是量化信号频谱在给定时间帧内的质心或平均频率的度量。从数学上讲,对于任意帧k,频谱质心可以表示为:

可以将其视为频率bin索引的加权求和,其中权重由给定时间帧中bin的能量贡献确定。还通过将加权和除以所有权重的和来进行归一化,以便在不同信号之间进行统一比较。下面是计算信号频谱质心的Python代码:
def spectral_centroid(signal, sample_rate, frame_size=1024, hop_length=512): """ 计算信号的频谱质心。 参数: signal (array):输入信号。 sample_rate (int):音频的采样率。 frame_size (int, optional):每个帧的大小(以样本为单位)。默认为1024。 hop_length (int, optional):连续帧之间的样本数。默认为512。 返回: ndarray:信号每个帧的频谱质心。 """ # 计算信号的声谱图 spec = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length) # 提取幅度并进行转置 modified_spec = np.abs(spec).T res = [] for sub_arr in modified_spec: # 计算频谱质心 sc_val = sc(sub_arr) # 存储当前帧的频谱质心值 res.append(sc_val) return np.array(res)def sc(arr): """ 计算信号的频谱质心。 参数: arr (array):当前帧的频域数组。 返回: float:当前帧的频谱质心值。 """ res = 0 for i in range(0, len(arr)): # 计算加权和 res += i*arr[i] return res/sum(arr)def bin_to_freq(spec, bin_val, sample_rate, frame_size=1024, hop_length=512): """ 计算与给定bin值对应的频率 参数: spec (array):声谱图。 bin_val ():bin值。 sample_rate (int):音频的采样率。 frame_size (int, optional):每个帧的大小(以样本为单位)。默认为1024。 hop_length (int, optional):连续帧之间的样本数。默认为512。 返回: int:与分割频率对应的bin索引。 """ # 计算频率范围 range_of_freq = sample_rate / 2 # 计算每个bin的频率变化量 change_per_bin = range_of_freq / spec.shape[0] # 计算与bin对应的频率 split_freq = bin_val*change_per_bin return split_freqdef plot_spectral_centroid(signal, sample_rate, name, frame_size=1024, hop_length=512, col = "black"): """ 绘制信号的频谱质心随时间的变化。 参数: signal (ndarray):输入信号。 sample_rate (int):音频的采样率。 name (str):绘图标题中的信号名称。 frame_size (int, optional):每个帧的大小(以样本为单位)。默认为1024。 hop_length (int, optional):连续帧之间的样本数。默认为512。 """ # 计算STFT spectrogram = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length) # 将STFT转换为dB比例 spectrogram_db = librosa.amplitude_to_db(np.abs(spectrogram)) # 计算频谱质心 sc_arr = spectral_centroid(signal, sample_rate, frame_size, hop_length) # 计算相应的频率: sc_freq_arr = bin_to_freq(spectrogram_db, sc_arr, sample_rate, frame_size, hop_length) # 生成帧索引 frames = range(0, len(sc_arr)) # 将帧转换为时间 time在上述代码中,定义了谱质心函数以产生所有时间帧的谱质心数组。随后,定义了sc()函数,通过简单的迭代过程计算一个帧的谱质心,该过程将索引值与幅度相乘,然后归一化以获得平均频率bin。在绘制由spectral_centroid()返回的谱质心值之前,还定义了一个名为bin to freq的附加函数,作为绘图的辅助函数。该函数将平均bin值转换为对应的频率值,这样可以在原始谱图上绘制,以便对谱质心随时间的变化有一个一致的理解。下面显示了输出的绘图(在谱图上叠加了谱质心的变化):
![吉他的谱质心[图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*CpQGq2geei3hJdl4sQvrKg.png)
![铜管的谱质心[图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*NOkciC8-vrK58ZY1W5-SsQ.png)
![鼓套的谱质心[图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*q4RWqeUuo9hPhNRpHiyZOA.png)
谱质心在时间域分析中与RMSE度量很相似,通常用作声音音色和亮度的描述符。具有较高谱质心的声音往往具有更亮或更高音导向的特质,而较低的谱质心值与更暗或更低音导向的特征相关。谱质心是音频机器学习中最重要的特征之一,常用于涉及音频/音乐流派分类的应用。
特征7:谱带宽
现在,我们将讨论谱带宽/扩展,这是一种衡量信号频谱在给定时间帧内组成频率的能量分布的指标。可以这样理解:如果谱质心是平均值,谱带宽是其围绕质心的扩散/方差的度量。数学上,对于任意帧k,谱带宽计算公式如下:

其中SCₖ表示第k帧的谱质心。与之前一样,通过将加权和除以所有权重的和来进行归一化,以便在不同信号之间进行统一比较。计算信号谱带宽的Python代码如下:
def spectral_bandwidth(signal, sample_rate, frame_size=1024, hop_length=512): """ 计算信号的谱带宽。 Args: signal (array): 输入信号。 sample_rate (int): 音频的采样率。 frame_size (int, optional): 每帧的大小(样本数)。默认为1024。 hop_length (int, optional): 连续帧之间的样本数。默认为512。 Returns: ndarray: 信号每帧的谱带宽。 """ # 计算信号的谱图 spec = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length) # 提取幅度并转置 modified_spec = np.abs(spec).T res = [] for sub_arr in modified_spec: # 计算谱带宽 sb_val = sb(sub_arr) # 存储当前帧的谱带宽值 res.append(sb_val) return np.array(res)def sb(arr): """ 计算信号的谱带宽。 Args: arr (array): 当前帧的频域数组。 Returns: float: 当前帧的谱带宽值。 """ res = 0 sc_val = sc(arr) for i in range(0, len(arr)): # 计算加权和 res += (abs(i - sc_val))*arr[i] return res/sum(arr)def plot_spectral_bandwidth(signal, sample_rate, name, frame_size=1024, hop_length=512): """ 绘制信号的谱带宽随时间的变化。 Args: signal (ndarray): 输入信号。 sample_rate (int): 音频的采样率。 name (str): 绘图标题中的信号名称。 frame_size (int, optional): 每帧的大小(样本数)。默认为1024。 hop_length (int, optional): 连续帧之间的样本数。默认为512。 """ # 计算谱带宽 sb_arr = spectral_bandwidth(signal, sample_rate, frame_size, hop_length) # 生成帧索引 frames = range(0, len(sb_arr)) # 将帧转换为时间 time = librosa.frames_to_time(frames, hop_length=hop_length) # 创建一个指定大小的新图像 plt.figure(figsize=(15, 7)) # 绘制谱带宽随时间的变化 plt.plot(time, sb_arr) # 设置绘图标题 plt.title(name + " (谱带宽)") # 显示绘图 plt.show() plot_spectral_bandwidth(acoustic_guitar, sr, "吉他")plot_spectral_bandwidth(brass, sr, "铜管")plot_spectral_bandwidth(drum_set, sr, "鼓套")
与之前相同,在上述代码中,定义了频谱带宽函数来使用sb辅助函数生成所有时间帧的频谱展宽数组,该函数迭代地计算一个帧的带宽。最后,使用绘制频谱带宽函数来绘制这些带宽值。输出的图像如下所示:
![Acoustic Guitar的频谱带宽[作者提供的图像]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*Td--j-QnYI7aBd3jWwXf6g.png)
![Brass的频谱带宽[作者提供的图像]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*nl_g33qWsFmwxErGksZB1g.png)
![Drum Set的频谱带宽[作者提供的图像]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*LWAAj53HTRpmBC-wOqfDDQ.png)
频谱带宽可以在各种音频分析/分类任务中使用,因为它能够提供有关信号中频率的传播或宽度的信息。较高的频谱带宽(如铜管乐器和鼓组所示)表示更广泛的频率范围,表明信号更加多样或复杂。另一方面,较低的带宽表示较窄的频率范围,表明信号更加集中或音调纯净。
特征8:频谱平坦度
最后,我们将讨论频谱平坦度(也称为Weiner熵),它是一种衡量音频信号功率谱平坦性或均匀性的指标。它帮助我们了解音频信号与纯音调(与噪声类似)的接近程度,因此也被称为音调系数。对于任何帧k,频谱平坦度是其几何平均和算术平均的比值。数学上表示为:

计算信号频谱平坦度的Python代码如下所示:
def spectral_flatness(signal, sample_rate, frame_size=1024, hop_length=512): """ 计算信号的频谱平坦度。 参数: signal(数组):输入信号。 sample_rate(int):音频的采样率。 frame_size(int,可选):每个帧的大小(样本数)。默认值为1024。 hop_length(int,可选):连续帧之间的样本数。默认值为512。 返回: ndarray:信号每个帧的频谱平坦度。 """ # 计算信号的频谱图 spec = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length) # 提取幅度并转置 modified_spec = np.abs(spec).T res = [] for sub_arr in modified_spec: # 计算几何平均数 geom_mean = np.exp(np.log(sub_arr).mean()) # 计算算术平均数 ar_mean = np.mean(sub_arr) # 计算频谱平坦度 sl_val = geom_mean/ar_mean # 存储当前帧的频谱平坦度值 res.append(sl_val) return np.array(res)def plot_spectral_flatness(signal, sample_rate, name, frame_size=1024, hop_length=512): """ 绘制信号的频谱平坦度随时间的变化。 参数: signal(ndarray):输入信号。 sample_rate(int):音频的采样率。 name(str):用于绘图标题的信号名称。 frame_size(int,可选):每个帧的大小(样本数)。默认值为1024。 hop_length(int,可选):连续帧之间的样本数。默认值为512。 """ # 计算频谱带宽 sl_arr = spectral_flatness(signal, sample_rate, frame_size, hop_length) # 生成帧索引 frames = range(0, len(sl_arr)) # 将帧转换为时间 time = librosa.frames_to_time(frames, hop_length=hop_length) # 创建一个具有特定大小的新图形 plt.figure(figsize=(15, 7)) # 绘制随时间变化的频谱平坦度 plt.plot(time, sl_arr) # 设置绘图标题 plt.title(name + "(频谱平坦度)") # 显示绘图 plt.show() plot_spectral_flatness(acoustic_guitar, sr, "Acoustic Guitar")plot_spectral_flatness(brass, sr, "Brass")plot_spectral_flatness(drum_set, sr, "Drum Set")
上述代码的结构与其他频域提取方法相同。唯一的区别在于for循环中的特征提取函数,它使用NumPy函数计算算术平均值和几何平均值,并计算它们的比值以生成每个时间帧的谱平坦度值。下图显示了输出的绘图:
![声学吉他的谱平坦度 [图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*6LvWubMfSszLjZBSairoAg.png)
![铜管的谱平坦度 [图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*OzhJvcyF8ZZ7tmovy1bxIA.png)
![鼓套的谱平坦度 [图片由作者提供]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*gnekroUcZKW_QFQuyEg3PQ.png)
较高的谱平坦度值(接近1)表示信号在不同频率上的能量分布更均匀或更平衡。这在鼓套中一直存在,表明声音更像是“噪声”或宽带信号,没有明显的峰值或特定频率的强调(正如之前从缺乏周期性中注意到的)。
另一方面,较低的谱平坦度值(尤其是对于声学吉他和在某种程度上是铜管)意味着功率谱更不均匀,能量集中在少数几个特定的频率上。这显示出声音中存在音调或谐波成分(正如它们在周期性时间域结构中反映出来的)。一般来说,具有明显音高/频率的音乐往往具有较低的谱平坦度值,而噪音(非音调)的声音则具有较高的谱平坦度值。
结论
在本文中,我们深入探讨了音乐工程中音频信号处理的特征提取的不同策略和技术。我们从学习声音产生和传播的基础知识开始,这可以有效地转化为随时间变化的压力变化,从而形成其时域表示。我们讨论了声音的数字表示及其重要参数,包括采样率、帧大小和跳跃长度。理论上讨论了时间域特征,如幅度包络、均方根能量、峰值因子、峰值功率比和过零率,并在三种乐器(声学吉他、铜管和鼓套)上进行了计算评估。随后,介绍并分析了声音的频域表示,通过对傅里叶变换和谱图的各种理论讨论。这为一系列频域特征铺平了道路,包括频带能量比、谱质心、带宽和音调系数,每个特征都可以有效地用于衡量输入音频的特定特征。信号处理应用还包括梅尔谱图、倒谱系数、噪声控制、音频合成等等。我希望这个解释能为进一步探索该领域的高级概念打下基础。
希望您喜欢阅读本文!如有任何疑问或建议,请在评论框中回复。
欢迎通过邮件与我联系。
如果您喜欢我的文章并想阅读更多,请关注我。
备注:除封面图片外,所有图片均由作者制作。
参考文献
峰值因子。 (2023)。维基百科。https://en.wikipedia.org/w/index.php?title=Crest_factor&oldid=1158501578
librosa — Librosa 0.10.1dev 文档。 (n.d.)。检索于2023年6月5日,https://librosa.org/doc/main/index.html
谱平坦度。 (2022)。维基百科。https://en.wikipedia.org/w/index.php?title=Spectral_flatness&oldid=1073105086
The Sound of AI. (2020, August 1). Valerio Velardo.https://valeriovelardo.com/the-sound-of-ai/