一项新的人工智能研究解释了如何通过上下文指导学习(ICIL)来提高预训练和指导微调模型的零样本任务泛化性能
A new AI research explains how to improve zero-shot task generalization performance of pre-training and guided fine-tuning models through Contextualized Instructional Learning (ICIL).


大型语言模型(LLMs)通过一种称为few-shot演示的过程,在推理过程中展示出了它们可以适应目标任务的能力,有时也被称为上下文学习。随着模型规模的扩大,LLMs展示出了越来越明显的新特性。其中一个新兴的才能是通过遵循指示来推广到未知任务的能力。指示微调(Instruction tuning)或RLHF是一种用于增强这种能力的指示学习方法之一。然而,先前的研究主要集中在基于微调的指示学习技术上。模型在许多带有指示的任务上进行了多任务微调,需要进行许多反向传播过程。
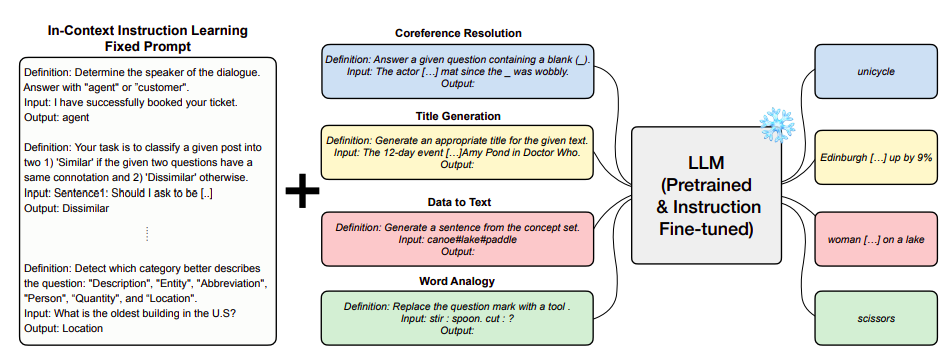
韩国科学技术院和LG研究的一组研究人员表明,在上下文学习中学习遵循指示的过程(ICIL)对于已经准备好的预训练模型以及专门调整以遵循指示的模型都是有优势的,如图1所示。ICIL使用的提示包含许多跨任务的示例,每个示例都是任务的教育、输入和输出的一个实例。由于它们在评估集中完全排除了用于演示的函数,并且因为它们对所有评估任务使用相同的一组示例作为固定的提示,如图2所示,ICIL是一种零样本学习方法。

他们使用一种简单的基于启发式的采样方法创建了一个固定的示例集,该方法适用于各种下游任务和模型规模。通过为所有任务前置相同的固定演示集,他们可以在新的目标任务或模型上评估和复制基线的零样本性能。图1显示,ICIL显著提高了多个未经微调以遵循指示的预训练LLMs在零样本挑战中的泛化性能。
他们的数据表明,选择具有明确响应选项的分类任务是ICIL成功的关键。重要的是,即使是带有ICIL的较小LLMs的性能也比没有ICIL的较大语言模型要好。例如,6B大小的ICIL GPT-J的性能优于175B大小的标准零样本GPT-3 Davinci 30。其次,他们证明了将ICIL添加到指示微调的LLMs中如何增强它们遵循零样本指示的能力,特别是对于具有超过100B个元素的模型。这表明ICIL的影响是在指示修改的影响之上的叠加。
与先前的研究相反,声称few-shot上下文学习需要检索与目标任务相似的示例,他们发现即使将随机短语替换为每个示例的输入实例分布,性能也不会明显受到影响。基于这种方法,他们提出LLMs学习在推理过程中指示中提供的响应选项与每个演示的生成之间的对应关系,而不是依赖于指示、输入和输出之间的复杂连接。根据这一理论,ICIL的目的是帮助LLMs将注意力集中在目标指示上,以发现目标任务响应分布的信号。
查看Paper和Github。此研究的所有荣誉归功于该项目的研究人员。此外,请别忘了加入我们的1.5万+ 机器学习SubReddit、Discord频道和电子邮件通讯,我们在这里分享最新的AI研究新闻、酷炫的AI项目等等。
这篇文章介绍了一项新的AI研究,解释了在预训练和指令微调模型中如何通过上下文指导学习(ICIL)来提高零样本任务的泛化性能。本文最初发表于MarkTechPost。





