使用检索增强生成和LangChain代理简化对内部信息的访问
利用检索增强生成和LangChain代理简化内部信息访问
本文将介绍客户在搜索内部文件时面临的最常见挑战,并为您提供有关如何使用AWS服务创建一个生成式AI对话机器人的具体指导,使内部信息更有用。
非结构化数据占据组织中所有数据的80%,包括手册,PDF,常见问题解答,电子邮件和其他日常增长的文件库。如今的企业依赖于不断增长的内部信息库,当非结构化数据量变得难以管理时,问题就会出现。通常,用户发现自己需要阅读和检查许多不同的内部资源来找到他们需要的答案。
内部问题和答案论坛可以帮助用户获得非常具体的答案,但也需要较长的等待时间。对于公司特定的内部常见问题解答,长时间等待会导致员工生产力下降。问题和答案论坛很难扩展,因为它们依赖于手动编写的答案。通过生成式AI,用户在搜索和查找信息方面正在发生范式转变。下一个合乎逻辑的步骤是使用生成式AI将大型文档压缩成更小的易于用户消化的信息。用户可以基于多个现有的内部信息库实时生成摘要,而不是花费很长时间阅读文本或等待答案。
解决方案概述
该解决方案允许客户通过使用转换模型来检索有关内部文档的问题的策划响应,从而生成对其未经过训练的数据的问题的答案,这种技术被称为零-shot提示。通过采用此解决方案,客户可以获得以下好处:
- 基于现有的内部文档源找到准确的问题答案
- 通过使用大型语言模型(LLM)提供对具有最新信息的文档的复杂查询的几乎即时答案,减少用户搜索答案所花费的时间
- 通过集中的仪表板搜索先前回答的问题
- 减少花费时间手动阅读信息以寻找答案所带来的压力
检索增强生成(RAG)
检索增强生成(RAG)通过从知识库中找到答案,并使用LLM将文档总结为简洁的响应,从而减少了基于LLM的查询的一些缺点。请阅读此文章以了解如何使用Amazon Kendra实施RAG方法。以下是与基于LLM的查询相关的风险和限制,Amazon Kendra的RAG方法可以解决:
- 幻觉和可追溯性-LLM基于大数据集进行训练,并根据概率生成响应。这可能导致不准确的答案,即所谓的幻觉。
- 多个数据孤立-为了在响应中引用来自多个来源的数据,需要建立一个连接器生态系统来聚合数据。访问多个存储库是手动且耗时的。
- 安全性-在部署由RAG和LLM驱动的对话机器人时,安全性和隐私是重要考虑因素。尽管使用Amazon Comprehend来过滤可能通过用户查询提供的个人数据,但仍有可能意外显示个人或敏感信息,这取决于摄取的数据。这意味着控制对聊天机器人的访问至关重要,以防止对敏感信息的意外访问。
- 数据相关性-LLM基于一定日期的数据进行训练,这意味着信息通常不是最新的。使用最近数据训练模型的成本很高。为了确保准确和最新的响应,组织有责任定期更新和丰富索引文档的内容。
- 成本-在部署此解决方案时,与之相关的成本应该是企业考虑的因素。企业在实施此解决方案时需要仔细评估其预算和性能要求。运行LLM可能需要大量计算资源,这可能会增加运营成本。对于需要大规模运行的应用程序,这些成本可能成为限制因素。然而,AWS云的好处之一是只支付您使用的资源。AWS提供简单、一致的按使用量计费模型,因此您只支付所使用的资源。
使用Amazon SageMaker JumpStart
对于基于转换器的语言模型,组织可以从使用Amazon SageMaker JumpStart获益,该服务提供了一系列预构建的机器学习模型。Amazon SageMaker JumpStart提供了广泛的文本生成和问答(Q&A)基础模型,可以轻松部署和利用。此解决方案集成了一个FLAN T5-XL Amazon SageMaker JumpStart模型,但在选择基础模型时需要考虑不同的方面。
将安全性整合到我们的工作流中
遵循Well-Architected Framework的安全支柱的最佳实践,我们使用Amazon Cognito进行身份验证。可以将Amazon Cognito用户池与支持包括OAuth(开放授权)、OIDC(开放ID连接)或SAML(安全断言标记语言)在内的几个用于访问控制的第三方身份提供者集成。识别用户及其操作可以确保解决方案的可追溯性。该解决方案还使用Amazon Comprehend的个人身份信息(PII)检测功能,自动识别和隐藏PII。隐藏的PII包括地址、社会安全号码、电子邮件地址和其他敏感信息。该设计确保通过输入查询提供的任何PII都将被隐藏。PII不会被存储、由Amazon Kendra使用或用于LLM。
解决方案概述
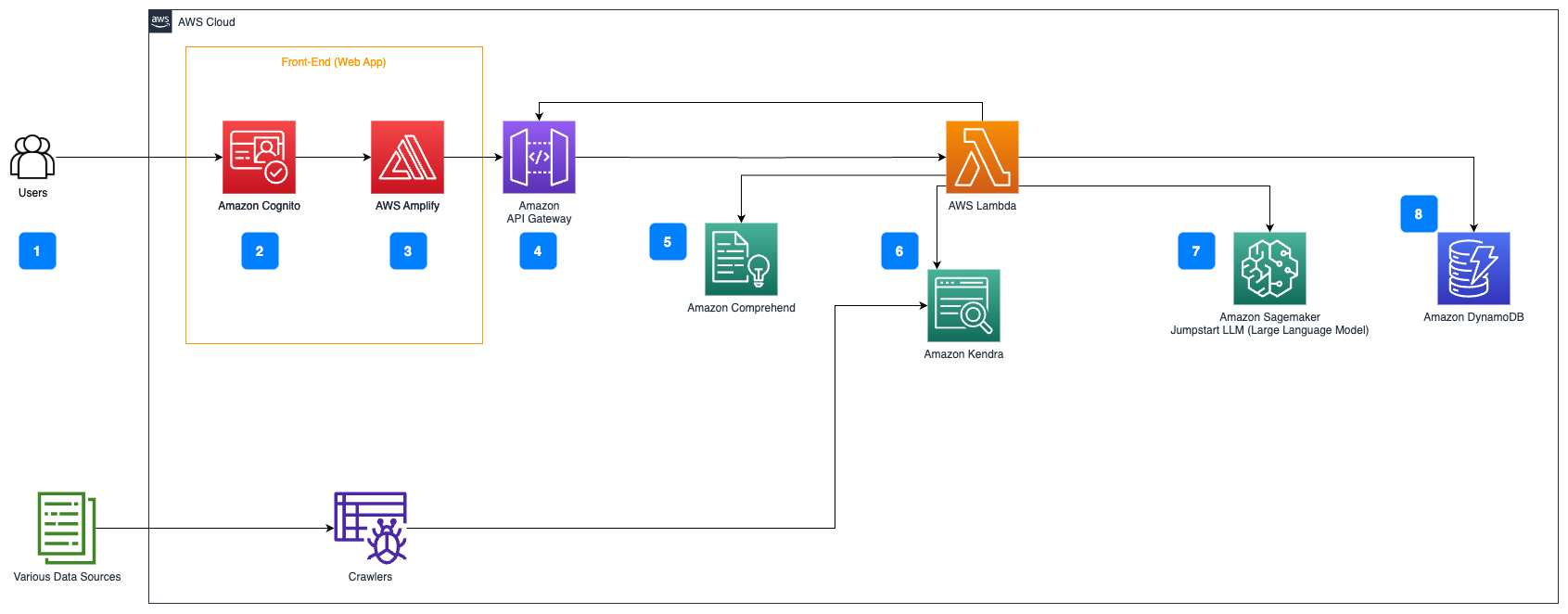
以下步骤描述了问答文档流程的工作流程:
- 用户通过Web界面发送查询。
- 使用Amazon Cognito进行身份验证,确保对Web应用程序的安全访问。
- Web应用程序前端托管在AWS Amplify上。
- Amazon API Gateway托管了一个REST API,其中包含各种端点来处理使用Amazon Cognito进行身份验证的用户请求。
- 使用Amazon Comprehend进行PII隐藏:
- 用户查询处理:当用户提交查询或输入时,首先通过Amazon Comprehend。该服务分析文本,并识别查询中存在的任何PII实体。
- PII提取:Amazon Comprehend从用户查询中提取检测到的PII实体。
- 使用Amazon Kendra进行相关信息检索:
- 使用Amazon Kendra管理包含用于生成用户查询答案的信息的文档索引。
- 使用LangChain QA检索模块构建包含有关用户查询的相关信息的对话链。
- 与Amazon SageMaker JumpStart集成:
- AWS Lambda函数使用LangChain库,并连接到带有上下文填充查询的Amazon SageMaker JumpStart端点。Amazon SageMaker JumpStart端点用于进行推断的LLM接口。
- 存储响应并返回给用户:
- LLM的响应与用户的查询、时间戳、唯一标识符和其他任意标识符(如问题类别)一起存储在Amazon DynamoDB中。将问题和答案作为离散项存储使得AWS Lambda函数可以根据提问时间轻松重现用户的对话历史。
- 最后,通过Amazon API Gateway REST API集成响应将响应发送回用户。
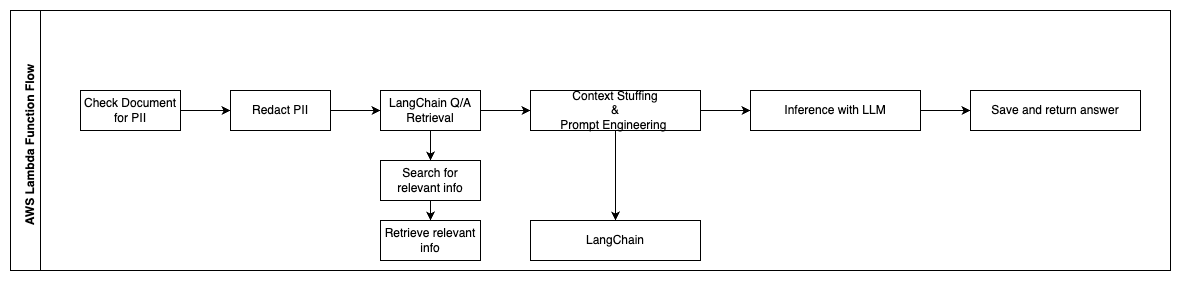
以下步骤描述了AWS Lambda函数及其在流程中的流动:
- 检查和隐藏任何PII/敏感信息
- LangChain QA检索链:
- 搜索和检索相关信息
- 上下文填充和提示工程:
- LangChain
- 使用LLM进行推断
- 返回响应并保存
用例
在许多业务用例中,客户可以使用此工作流程。以下部分解释了该工作流程如何在不同行业和领域中使用。
员工帮助
良好设计的企业培训可以提高员工满意度,并减少新员工入职所需的时间。随着组织的发展和复杂性的增加,员工难以理解内部文档的许多来源。在这种情况下,员工对如何处理和编辑内部问题工单提出了问题。员工可以访问并使用生成型人工智能(AI)对话机器人来询问和执行特定工单的下一步操作。
具体用例:根据公司指南自动解决员工问题。
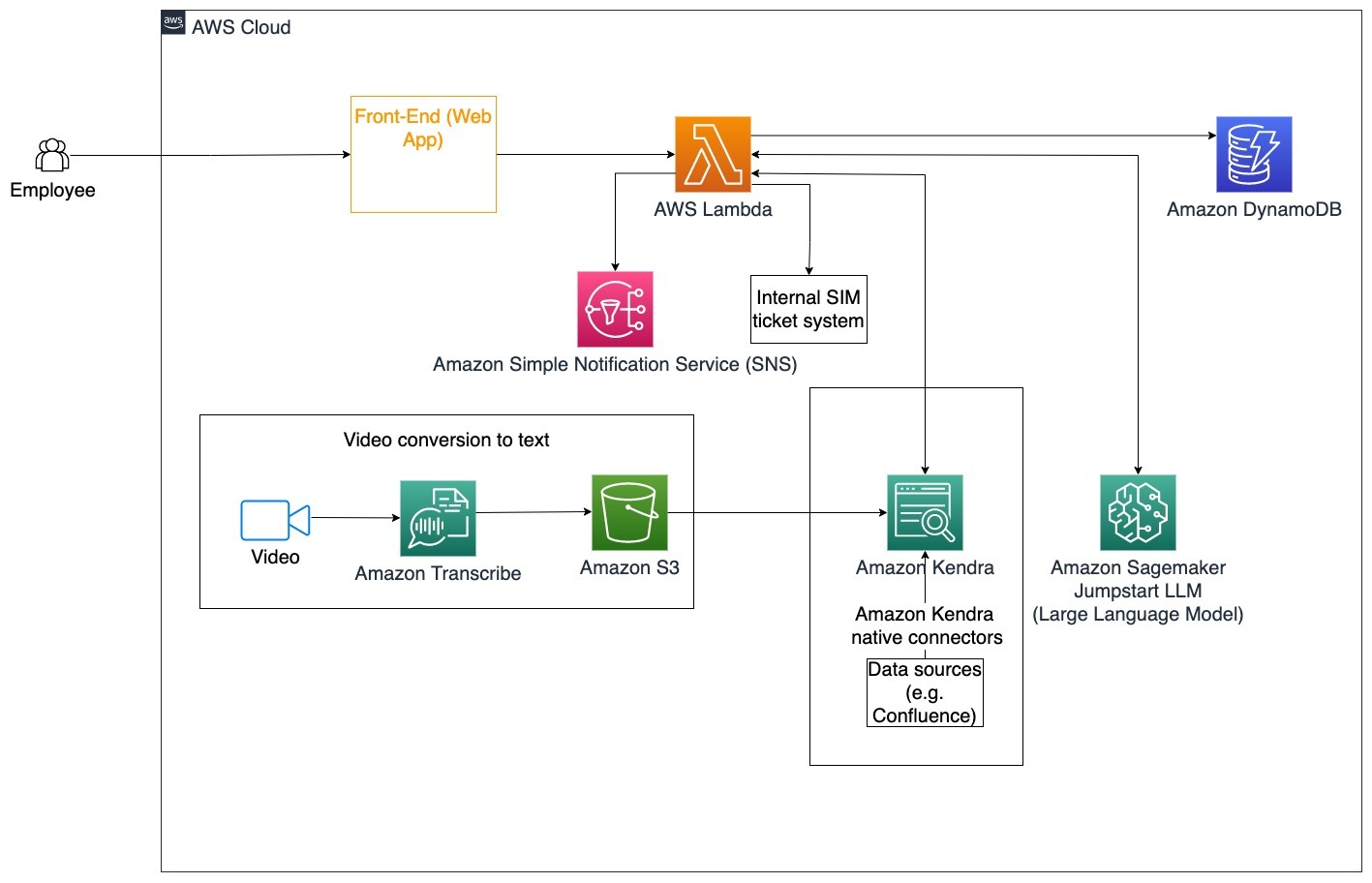
以下步骤描述了AWS Lambda函数及其在流程中的流动:
- LangChain代理识别意图
- 根据员工请求发送通知
- 修改工单状态

在此架构图中,可以通过Amazon Transcribe摄取企业培训视频以收集这些视频脚本的日志。此外,存储在各种来源(如Confluence、Microsoft SharePoint、Google Drive、Jira等)中的企业培训内容可以通过Amazon Kendra连接器创建索引。阅读本文以了解更多关于在Amazon Kendra中作为源点使用的原生连接器的信息。然后,Amazon Kendra爬虫能够使用企业培训视频脚本和存储在这些其他来源中的文档来协助对公司企业培训指南相关问题进行回答的对话机器人。LangChain代理通过使用Amazon Simple Notification Service(Amazon SNS)验证权限,修改工单状态并通知正确的个人。
客户支持团队
快速解决客户查询可以改善客户体验并鼓励品牌忠诚度。忠诚的客户群有助于推动销售,为公司贡献利润并增加客户参与度。客户支持团队花费大量精力参考许多内部文档和客户关系管理软件,以回答有关产品和服务的客户查询。在此上下文中,内部文档可以包括通用客户支持呼叫脚本、策略手册、升级指南和业务信息等。生成式AI对话机器人有助于成本优化,因为它代表客户支持团队处理查询。
具体用例:根据服务历史和客户服务计划处理更换机油的请求。
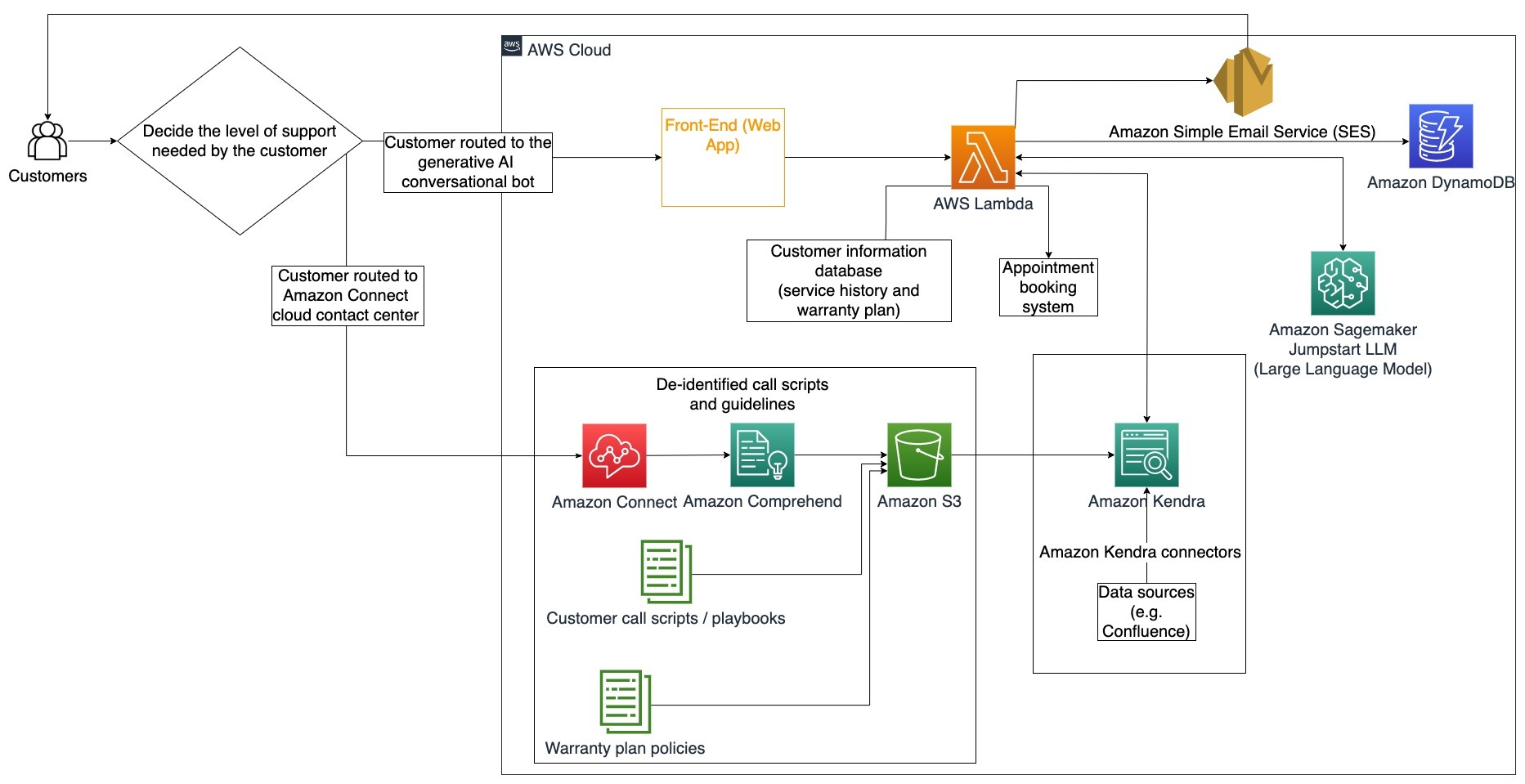
在此架构图中,客户被路由到生成式AI对话机器人或亚马逊联系中心。此决定可以基于所需的支持级别或客户支持代理的可用性。LangChain代理识别客户意图并验证身份。LangChain代理还检查服务历史记录和已购买的支持计划。
以下步骤描述了AWS Lambda函数及其在流程中的流动:
- LangChain代理识别意图
- 检索客户信息
- 检查客户服务历史记录和保修信息
- 预约、提供更多信息或路由到联系中心
- 发送电子邮件确认

使用Amazon Connect收集语音和聊天日志,使用Amazon Comprehend从这些日志中删除个人身份信息(PII)。然后,Amazon Kendra爬虫能够使用经过删除的语音和聊天日志、客户呼叫脚本和客户服务支持计划政策来创建索引。一旦做出决策,生成式AI对话机器人将决定是预约、提供更多信息还是将客户路由到联系中心以获取进一步帮助。为了成本优化,LangChain代理还可以使用更少的标记和更便宜的大型语言模型来生成较低优先级的客户查询答案。
金融服务
金融服务公司依赖及时使用信息来保持竞争力并遵守金融法规。使用生成式AI对话机器人,金融分析师和顾问可以以对话方式与文本信息进行交互,减少做出更明智决策所需的时间和精力。除了投资和市场研究外,生成式AI对话机器人还可以通过处理传统上需要更多人力和时间的任务来增强人类能力。例如,专门从事个人贷款的金融机构可以提高贷款处理速度,同时为客户提供更好的透明度。
具体用例:使用客户的财务历史和先前的贷款申请来决定和解释贷款决策。
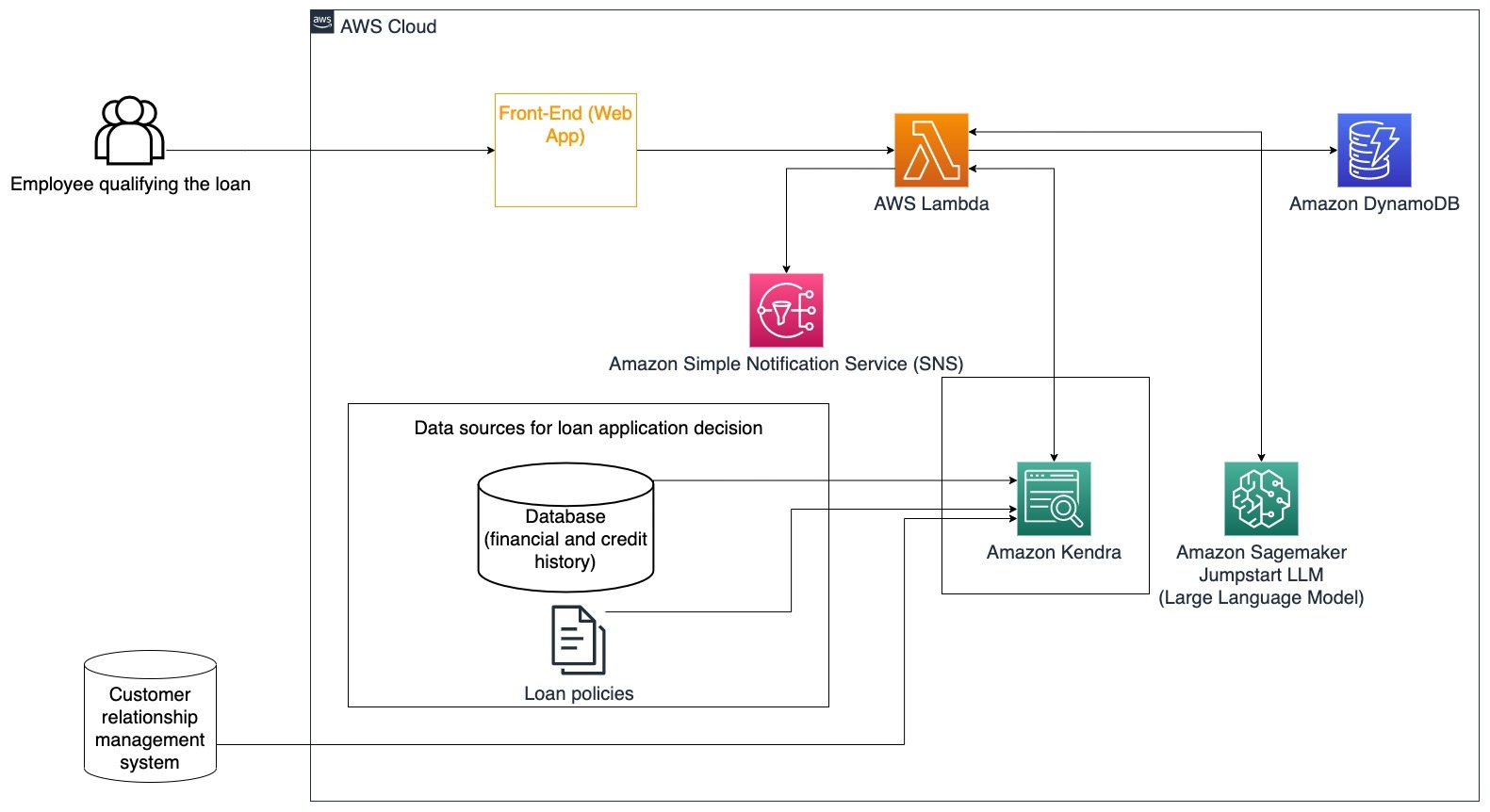
以下步骤描述了AWS Lambda函数及其在流程中的流动:
- LangChain代理识别意图
- 检查客户的财务和信用评分历史
- 检查内部客户关系管理系统
- 检查标准贷款政策并建议员工资格贷款的决策
- 向客户发送通知
该架构结合了存储在数据库中的客户财务数据和存储在客户关系管理(CRM)工具中的数据。这些数据点用于根据公司的内部贷款政策进行决策。客户可以提出澄清问题,以了解他们有资格申请的贷款和接受贷款的条件。如果生成式AI对话机器人无法批准贷款申请,用户仍然可以询问有关提高信用评分或替代融资选项的问题。
政府
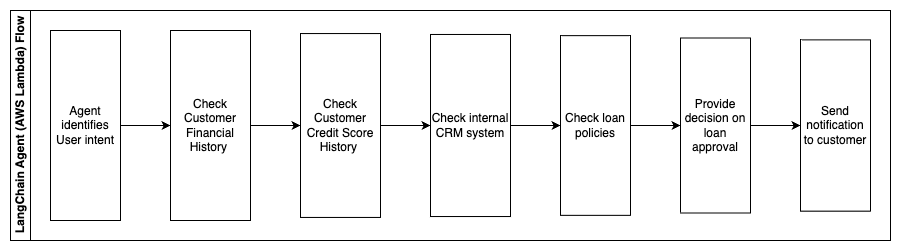
生成式AI对话机器人可以极大地提升政府机构的沟通速度、效率和决策过程。生成式AI对话机器人还可以提供对内部知识库的即时访问,帮助政府员工快速获取信息、政策和流程(如资格标准、申请流程和公民服务和支持)。其中一种解决方案是交互式系统,它允许纳税人和税务专业人员轻松找到与税收相关的详细信息和福利。它可以用于理解用户的问题,总结税收文件,并通过交互式对话提供清晰的答案。
用户可以提出以下问题:
- 继承税如何运作,税收阈值是什么?
- 你能解释一下所得税的概念吗?
- 出售第二套房产时的税务影响是什么?
此外,用户还可以方便地将税表提交到系统中,帮助验证提供的信息的准确性。
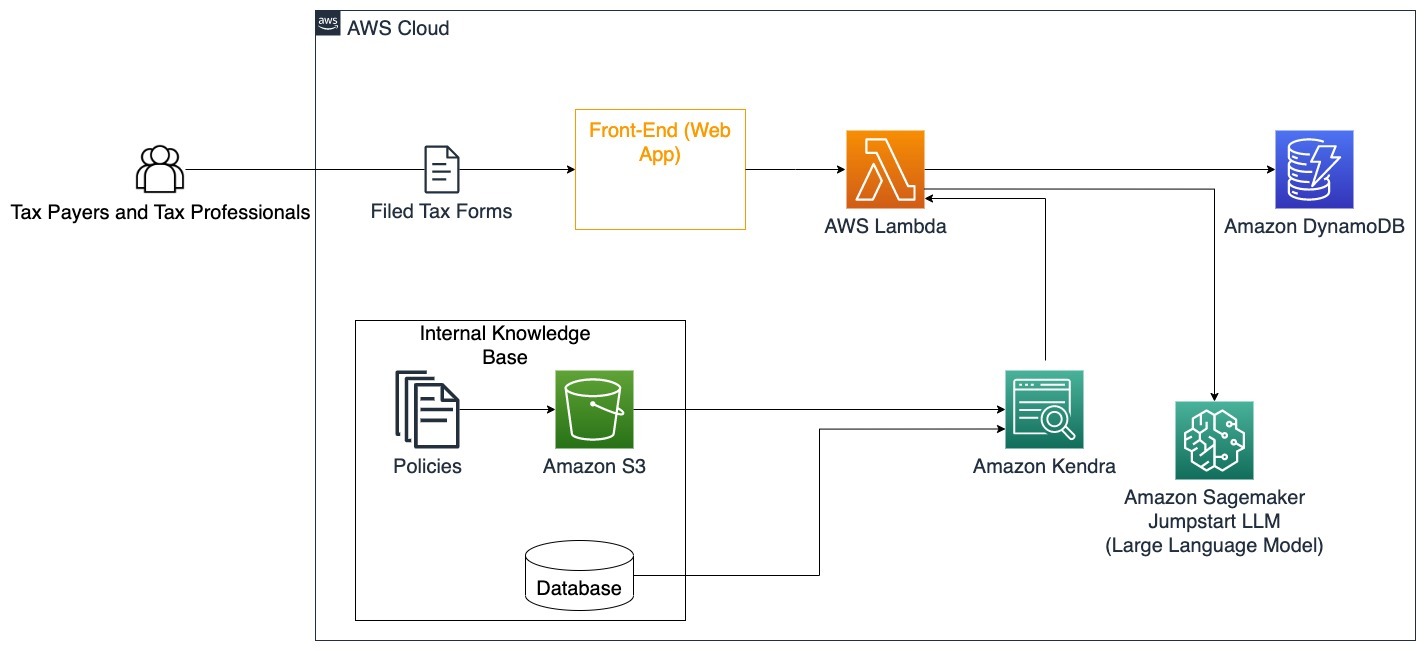
该架构说明了用户如何将填写完成的税表上传到解决方案中,并利用它进行交互式验证和准确填写必要信息的指导。
医疗保健
医疗保健企业有机会自动化使用大量的内部患者信息,同时解决有关治疗选择、保险理赔、临床试验和制药研究等用例的常见问题。使用生成式AI对话机器人可以快速准确地从提供的知识库中生成有关健康信息的答案。例如,一些医疗保健专业人员花费大量时间填写保险理赔表格。
在类似的情况下,临床试验管理员和研究人员需要查找有关治疗选择的信息。生成式AI对话机器人可以使用Amazon Kendra中的预建连接器,从制药公司和大学进行的持续研究所发布的数百万份文件中检索最相关的信息。
具体用例:减少填写和发送保险表格所需的错误和时间。
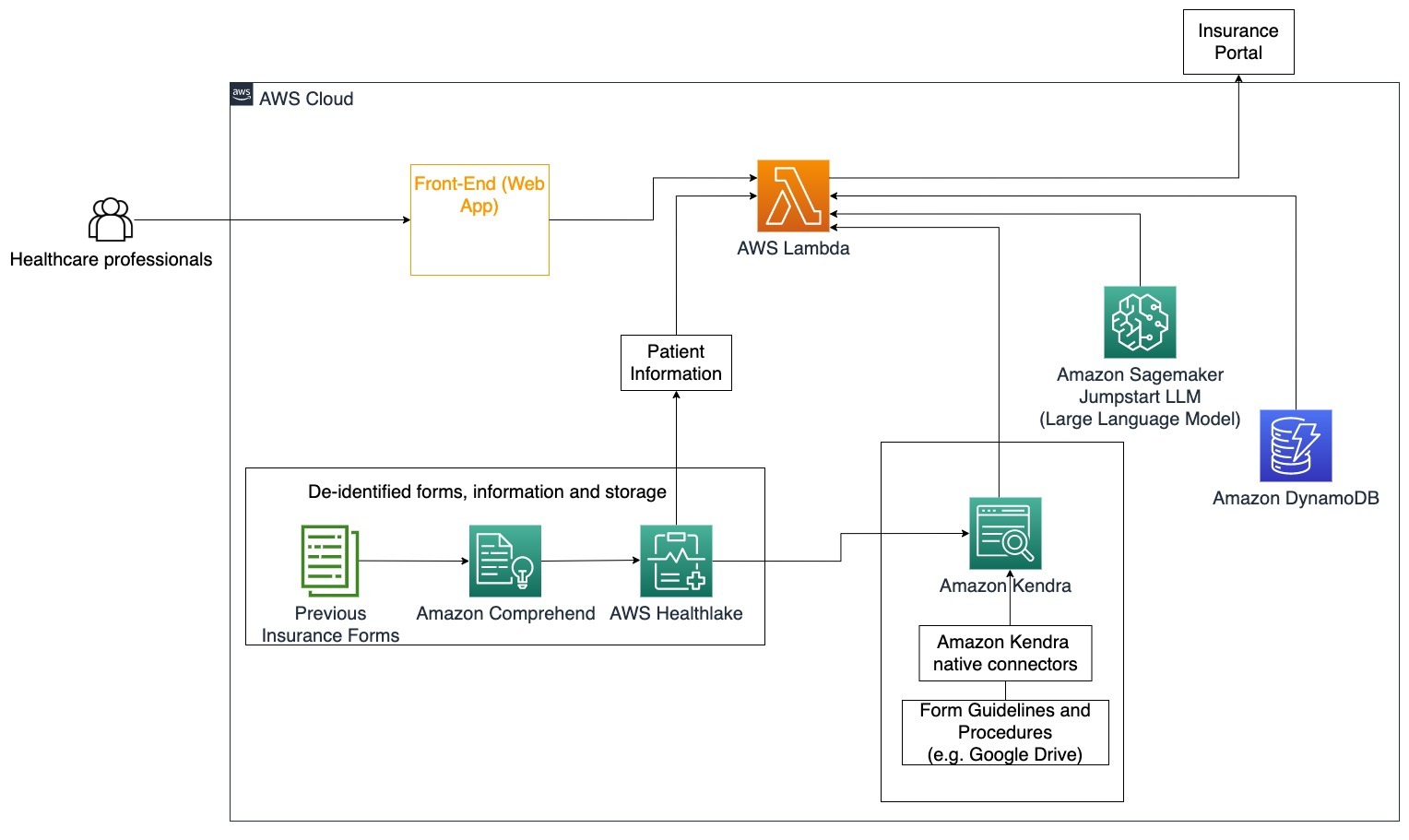
在此架构图中,医疗保健专业人员可以使用生成式AI对话机器人确定为保险填写哪些表格。然后,LangChain代理能够检索正确的表格,并根据保险政策和先前的表格为患者添加所需信息,并针对描述性部分提供响应。医疗保健专业人员可以在批准并将表单发送到保险门户之前编辑LLM给出的响应。
以下步骤描述了AWS Lambda函数及其在流程中的流动:
- LangChain代理以确定意图
- 检索所需的患者信息
- 根据患者信息和表单指南填写保险表格
- 在用户批准后将表单提交给保险门户
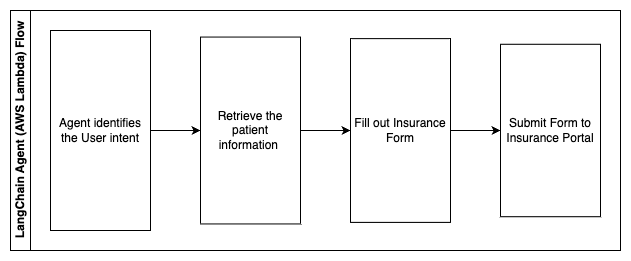
AWS HealthLake用于安全存储包括以前的保险表格和患者信息在内的健康数据,Amazon Comprehend用于从以前的保险表格中删除个人身份信息(PII)。然后,Amazon Kendra爬虫能够使用一组保险表格和指南来创建索引。一旦由生成式AI填写了表单,医疗专业人员审核后即可将表单发送到保险门户。
成本估计
将基本解决方案部署为概念验证的成本如下表所示。由于基本解决方案被视为概念验证,因此使用Amazon Kendra Developer Edition作为低成本选项,因为工作负载不会处于生产状态。我们对Amazon Kendra Developer Edition的假设是每月有730个活动小时。
对于Amazon SageMaker,我们假设客户将使用ml.g4dn.2xlarge实例进行实时推理,每个实例只有一个推理终点。您可以在此处找到关于Amazon SageMaker定价和可用推理实例类型的更多信息。
| 服务 | 资源消耗 | 每月估计成本(美元) |
| AWS Amplify | 150分钟构建时间 1 GB数据服务 500,000次请求 | 15.71 |
| Amazon API Gateway | 1百万REST API调用 | 3.5 |
| AWS Lambda | 100万次请求 每个请求5秒的持续时间 分配2 GB内存 | 160.23 |
| Amazon DynamoDB | 100万次读取 100万次写入 100 GB存储 | 26.38 |
| Amazon Sagemaker | 使用ml.g4dn.2xlarge进行实时推理 | 676.8 |
| Amazon Kendra | Developer Edition,每月730小时 10,000个文档扫描 5,000个查询/天 | 821.25 |
| . | . | 总成本:1703.87 |
* Amazon Cognito有一个免费层,每月使用Cognito用户池的活跃用户数为50,000或使用SAML 2.0身份提供者的活跃用户数为50。
清理
为了节省成本,请删除教程中部署的所有资源。您可以通过SageMaker控制台删除任何可能创建的SageMaker终点。请记住,删除Amazon Kendra索引不会从存储中删除原始文档。
结论
在本文中,我们向您展示了如何通过实时从多个存储库中汇总来简化对内部信息的访问。在商业可用的LLM最新发展之后,生成式AI的可能性变得更加明显。在本文中,我们展示了使用AWS服务创建无服务器聊天机器人的方法,该机器人使用生成式AI来回答问题。该方法包含身份验证层和Amazon Comprehend的PII检测,以过滤用户查询中提供的任何敏感信息。无论是医疗保健行业的个人了解申请保险的细节,还是HR了解特定的公司内部规定,都有多个行业和垂直领域可以从这种方法中受益。Amazon SageMaker JumpStart基础模型是聊天机器人的引擎,而使用RAG技术的上下文填充方法用于确保回答更准确地引用内部文档。
要了解更多关于在AWS上使用生成式AI的工作方式,请参考《宣布在AWS上构建生成式AI的新工具》。要获取有关在AWS服务中使用RAG技术的深入指导,请参考《使用Amazon Kendra、LangChain和大型语言模型快速构建高准确性的生成式AI应用程序》。由于这篇博客中的方法对LLM不加偏好,任何LLM都可以用于推理。在我们的下一篇文章中,我们将概述使用Amazon Bedrock和Amazon Titan LLM实现此解决方案的方法。






