“人工智能如何革新有声图书制作?利用神经文本转语音技术从电子书籍中创作成千上万本高质量的有声图书”
利用神经文本转语音技术,将电子书籍转化为高质量的有声图书


如今,许多人选择阅读有声书而不是传统的书籍或其他媒体。有声书不仅让读者在路上也能享受信息,还能帮助让内容对各个群体更易获得,包括儿童、视障人士和正在学习新语言的人。传统的有声书制作技术需要时间和金钱,并且可能导致录音质量参差不齐,例如专业人声朗读或志愿者驱动的项目如LibriVox。由于这些问题,跟上出版书籍的增加需要时间和精力。
然而,自动有声书的创建一直受到文本转语音系统机械化性质和决定哪些文本不应朗读的困难的影响(如目录、页码、图表和脚注等)。它们提供了一种通过从各种在线电子书集合中创建高质量有声书来克服上述困难的方法。它们的方法特别结合了神经文本转语音、富有表情的朗读、可扩展计算和自动识别相关内容的最新进展,以生成数千种自然音质的有声书。
它们为开源贡献了超过5,000个有声书的语音,总计超过35,000小时。它们还提供演示软件,使会议参与者能够通过用他们的声音朗读图书馆中的任何一本书的简短样本来制作自己的有声书。这项工作引入了一种将基于HTML的电子书转换为优秀有声书的可扩展方法。SynapseML是一个可扩展的机器学习平台,它能够对整个有声书生成过程进行分布式编排,是它们的流水线的基础。它们的分发链始于数千本由Project Gutenberg提供的免费电子书。它们主要处理这些电子书的HTML格式,因为它适合自动解析,是这些出版物中所有可用格式中最好的。
- 麻省理工学院的研究人员引入了一种新颖的轻量级多尺度关注机制,用于设备端的语义分割
- 谷歌DeepMind研究探索了神经网络中令人困惑的理解现象:揭示了记忆和泛化之间的相互作用
- 见到NExT-GPT:一种端到端的通用任意多模态大型语言模型(MM-LLMs)
因此,我们可以组织和可视化Project Gutenberg HTML页面的完整集合,并识别出许多相似结构文件的大型群组。电子书的主要类别被转换为一种标准格式,可以使用基于规则的HTML标准化程序自动处理这些HTML文件集合。多亏了这种方法,我们开发出了一种能够迅速和确定性地解析大量书籍的系统。最重要的是,它使我们能够专注于在朗读时会产生高质量录音的文件。
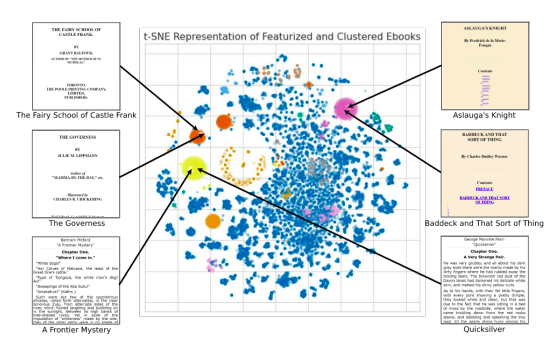
聚类的结果如图1所示,展示了在Project Gutenberg收藏中自发出现的各种组织良好的电子书群组。处理后,可以提取出纯文本流并输入到文本转语音算法中。不同的有声书需要不同的朗读技巧。对于非虚构作品,最好使用清晰客观的声音,而对于对话较多的小说,富有表情的朗读和一点“表演”效果更好。然而,在他们的现场演示中,他们将为客户提供更改文本的声音、节奏、音高和语调的选项。对于大部分书籍,他们使用清晰中性的神经文本转语音声音。
他们使用零样本文本转语音技术,将声音特征有效地从少量已注册录音中转移给用户的声音。通过这样做,用户只需使用少量已捕获的音频就能快速以自己的声音制作有声书。他们使用自动化的说话人和情感推断系统根据上下文动态调整朗读的声音和语调,以产生有情感的文本朗读。这提高了涉及多个人和动态互动的场景的逼真程度和趣味性。
为此,他们首先将文本分为叙述和对话,并为每一行对话指定一个不同的说话者。然后,他们利用自监督方法预测每个对话的情感语调。最后,他们使用多样式和基于上下文的神经文本转语音模型,为叙述和角色对话分配不同的声音和情感。他们认为这种方法可能会极大地增加有声书的可获得性和可访问性。






