“遇见BLIVA:一种多模态大型语言模型,用于更好地处理文本丰富的视觉问题”
BLIVA A multimodal large-scale language model for better handling visually rich text problems.


最近,大型语言模型(LLMs)在自然语言理解领域发挥了关键作用,展示了在广泛任务范围内泛化的非凡能力,包括零-shot和少-shot情景。视觉语言模型(VLMs)是OpenAI在2023年推出的GPT-4等代表作品,在解决开放式视觉问答(VQA)任务方面取得了显著进展,该任务要求模型回答关于图像或一组图像的问题。这些进展是通过将LLMs与视觉理解能力相结合实现的。
已经提出了各种方法来利用LLMs进行与视觉相关的任务,包括直接与视觉编码器的补丁特征对齐和通过固定数量的查询嵌入提取图像信息。
然而,尽管这些模型在基于图像的人机交互中有着重要的能力,但在解释图像中的文本方面仍面临挑战。含有文本的图像在日常生活中很常见,理解这种内容对于人类视觉感知至关重要。以前的研究采用了一个带有查询嵌入的抽象模块,但这种方法限制了它们捕捉图像中的文本细节的能力。
- “人工智能如何革新有声图书制作?利用神经文本转语音技术从电子书籍中创作成千上万本高质量的有声图书”
- 麻省理工学院的研究人员引入了一种新颖的轻量级多尺度关注机制,用于设备端的语义分割
- 谷歌DeepMind研究探索了神经网络中令人困惑的理解现象:揭示了记忆和泛化之间的相互作用
在本文概述的研究中,研究人员介绍了BLIVA(InstructBLIP with Visual Assistant),这是一个多模态LLM,它通过两个关键组件进行了战略性的工程设计:与LLM本身紧密对齐的学习查询嵌入以及包含更广泛的与图像相关数据的图像编码的补丁嵌入。下图概述了所提出方法的概况。
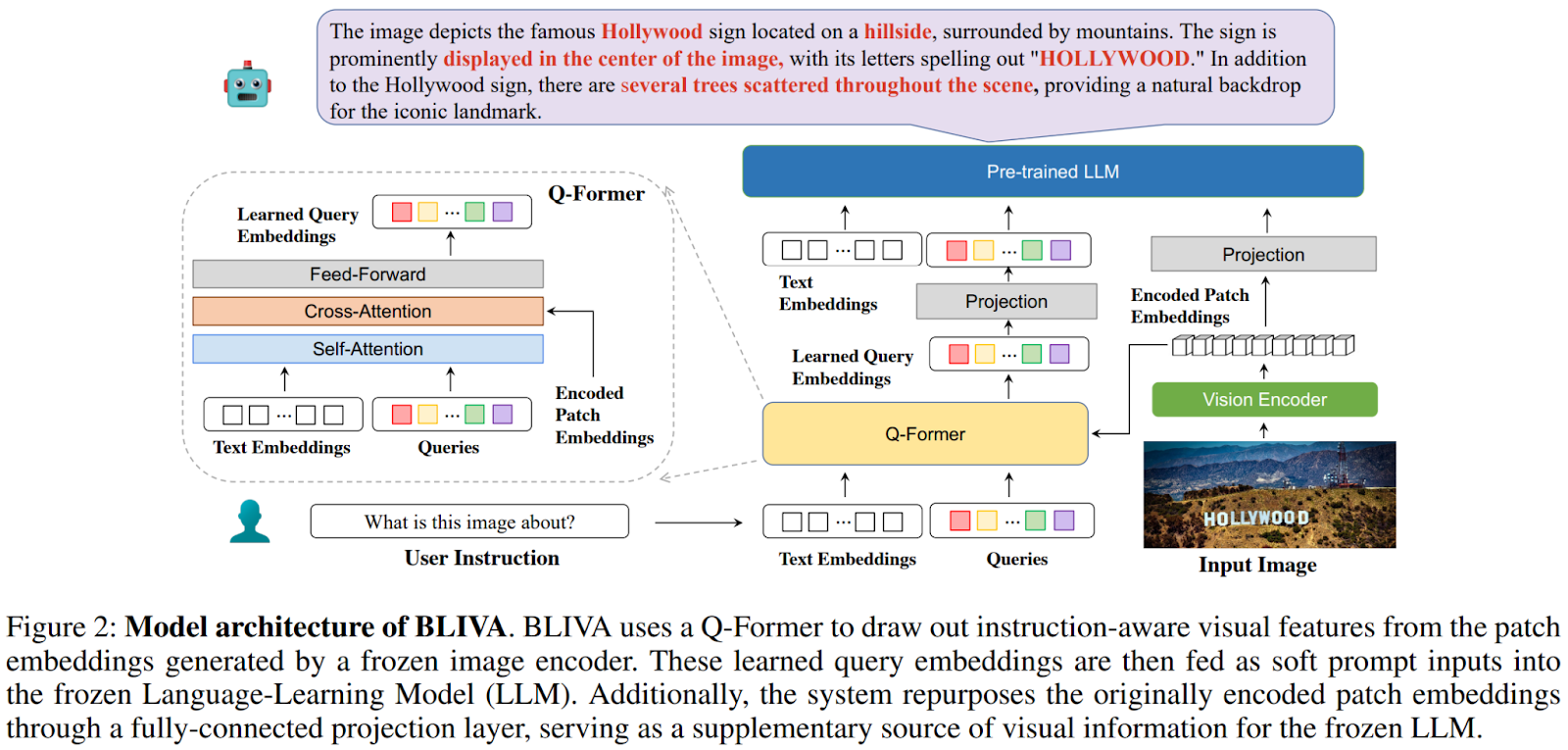
该技术克服了向语言模型提供图像信息时通常存在的限制,最终提高了文本-图像视觉感知和理解。该模型使用预训练的InstructBLIP和从零开始训练的编码补丁投影层进行初始化。遵循两阶段训练范式。初始阶段包括预训练补丁嵌入的投影层,并使用指令调整数据对Q-former和补丁嵌入的投影层进行微调。在整个这个阶段中,基于实验的两个关键发现,即解冻视觉编码器会导致先前知识的灾难性遗忘,同时训练LLM并没有带来改进,而是引入了显著的训练复杂性。
作者提供了两个示例场景,展示了BLIVA在解决与”Detailed caption”和”small caption + VQA”相关的VQA任务中的影响。

这是BLIVA的摘要,它是一种新颖的AI LLM多模态框架,将文本和视觉编码的补丁嵌入结合起来解决VQA任务。如果您对此感兴趣并且想要了解更多信息,请随时参考下面引用的链接。






