“任意物体的可提示分割”
Object Prompt Segmentation
文章解读 — 分割任何物体
今天的文章解读将是视觉化的!我们将分析 Meta 公司的 AI 研究团队所撰写的《分割任何物体》一文,这篇论文不仅在研究界引起了轰动,也受到了各种深度学习从业者和倡导者的关注。
《分割任何物体》介绍了可提示分割任务,介绍了分割任何物体模型(SAM),并详细介绍了一个包含超过1亿个掩码的1100万张图片的新公开数据集的生成。SAM 已被社区广泛采用,并导致了一些新的最先进的基础模型,例如将 Grounding DINO 与 SAM 结合的 Grounded-SAM。
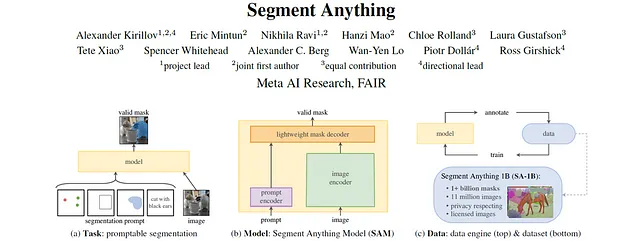
论文:分割任何物体
代码:https://github.com/facebookresearch/segment-anything
首次发布:2023年4月5日
作者:Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, Ross Girshick
分类:分割,零样本预测,计算机视觉,提示,大规模
大纲
- 背景与前言
- SAM — 分割任何物体模型
- SA-1B — 包含10亿个掩码的数据集
- 实验与消融分析
- 结论
- 进一步阅读与资源
背景与前言
《分割任何物体》的作者明确表示:“[…] 我们的目标是构建一个图像分割的基础模型。” 基础模型源于自然语言处理(NLP)的巨大成功。这些模型以自我监督的方式进行大规模训练。这些模型通常在零样本任务上表现非常出色,即它们能够解决与它们训练时不同的任务,并且表现得合理甚至更好,超过了有监督的竞争对手。近年来,许多研究人员致力于将 NLP 基础模型的成功带到其他领域,如计算机视觉。
像 CLIP 和 GLIP 这样的模型使得在图像分类或目标检测任务中,可以使用文本提示而不是固定的类别集合。其他模型,如 BYOL 或 DINO,提出了不同的技术来学习输入图像的语义丰富表示,这是许多计算机视觉应用的关键要求之一。
《分割任何物体》的论文旨在:
- 通过提示实现零样本分割
- 训练一个大规模模型(SAM)作为演示者
- 收集并发布最大的公开可用于分割的数据集。
但为什么零样本性能如此重要? — 答案有两个方面。首先,最初的计算机视觉模型是以有监督的方式进行训练的,不仅需要数据,还需要大量的地面真实标签。收集这些数据非常耗时且昂贵。其次,模型可以预测的类别仅限于用于训练的固定类别集合。如果您想向模型添加一个新类别,您需要首先收集数据并重新训练模型。
如何提示分割模型? — 您可能对 ChatGPT、CLIP 或 GLIP 等模型的文本提示很熟悉。虽然 SAM 原则上也经过了文本提示的测试,但它主要通过掩码、点、框或点网格进行提示,如下图所示。

将SAM放入上下文中之后,现在让我们更近距离地看一下Segment Anything Model(SAM)。
SAM — Segment Anything Model
Segment Anything Model(SAM)是一个多模型,它输入一张图像和一个或多个提示,并输出一个有效的分割掩码。该模型由三个主要模块组成:图像编码器、提示编码器和掩码解码器。
SAM可以根据以下任意组合的提示进行操作:掩码、一组点、边界框或文本。
注意:尽管论文提到并进行了与文本作为提示的实验,但官方实施方案和SAM演示(截止2023年9月)尚未发布。
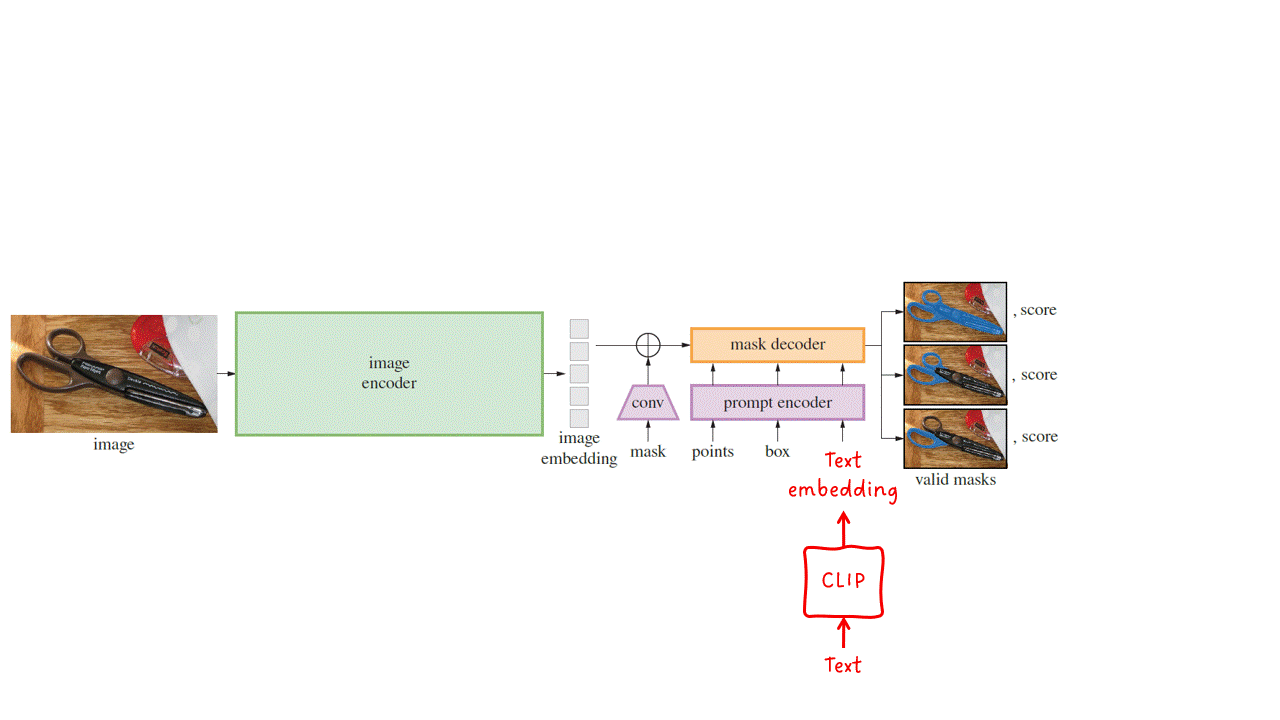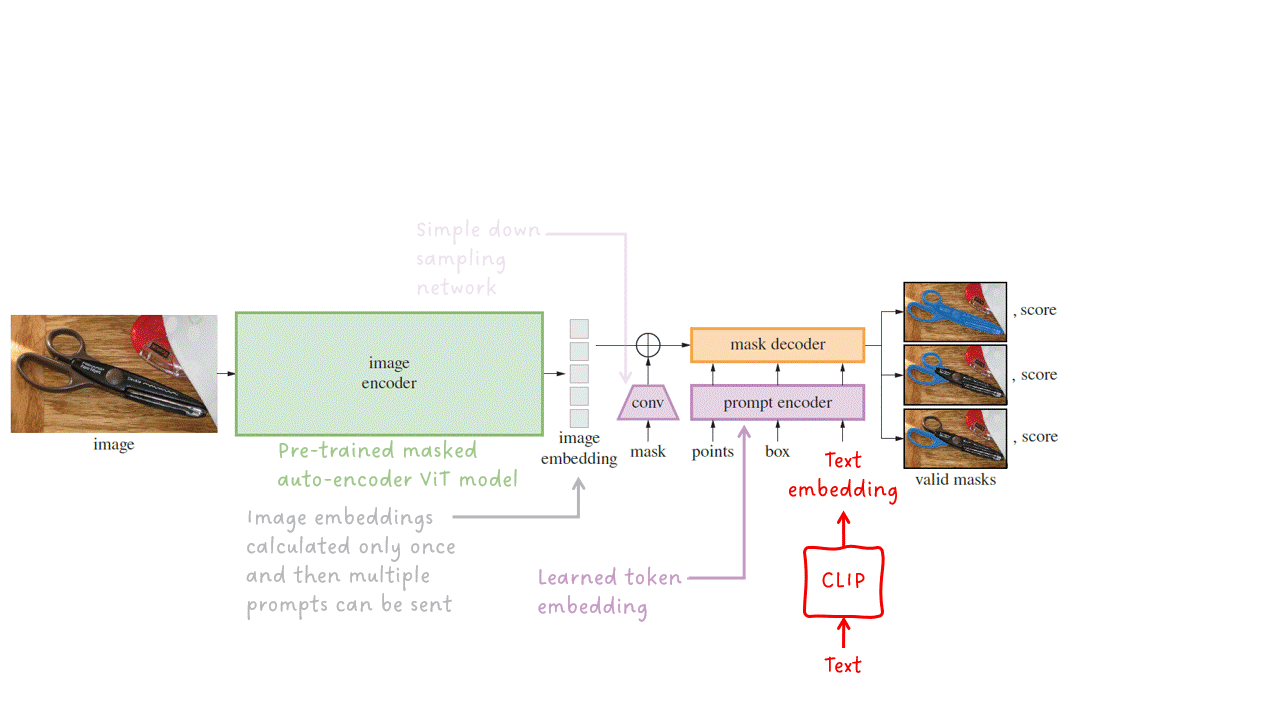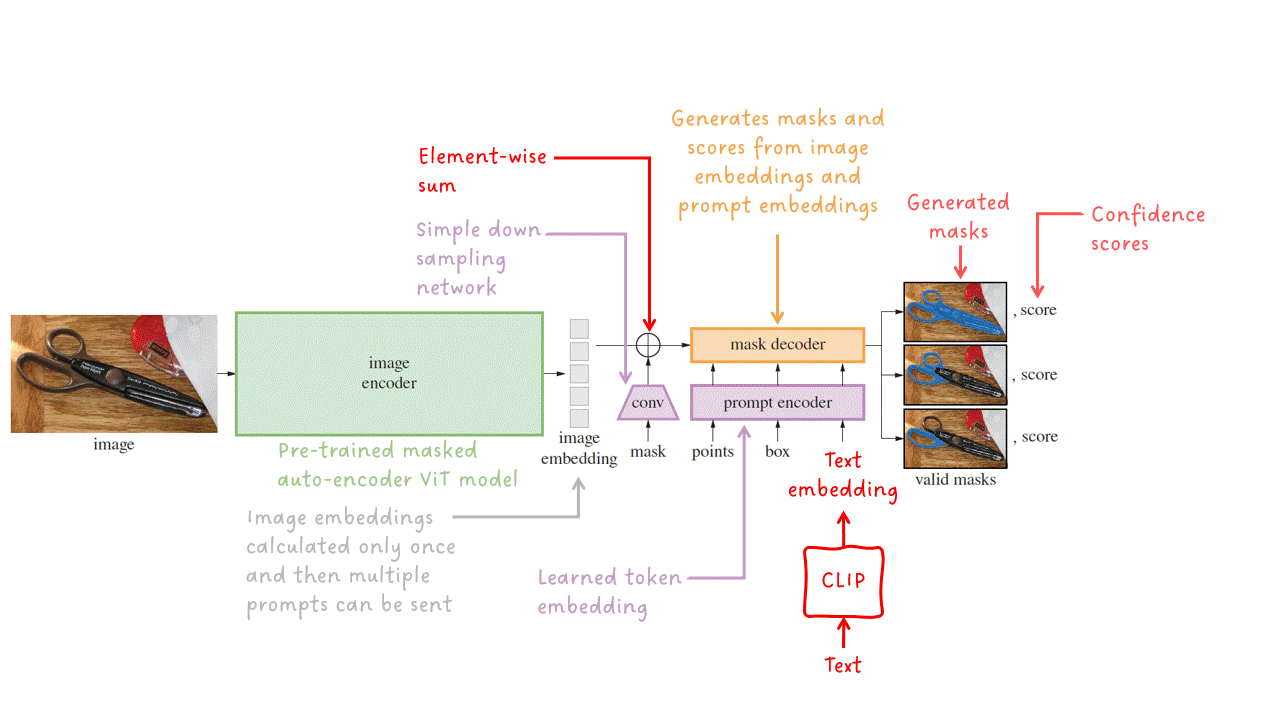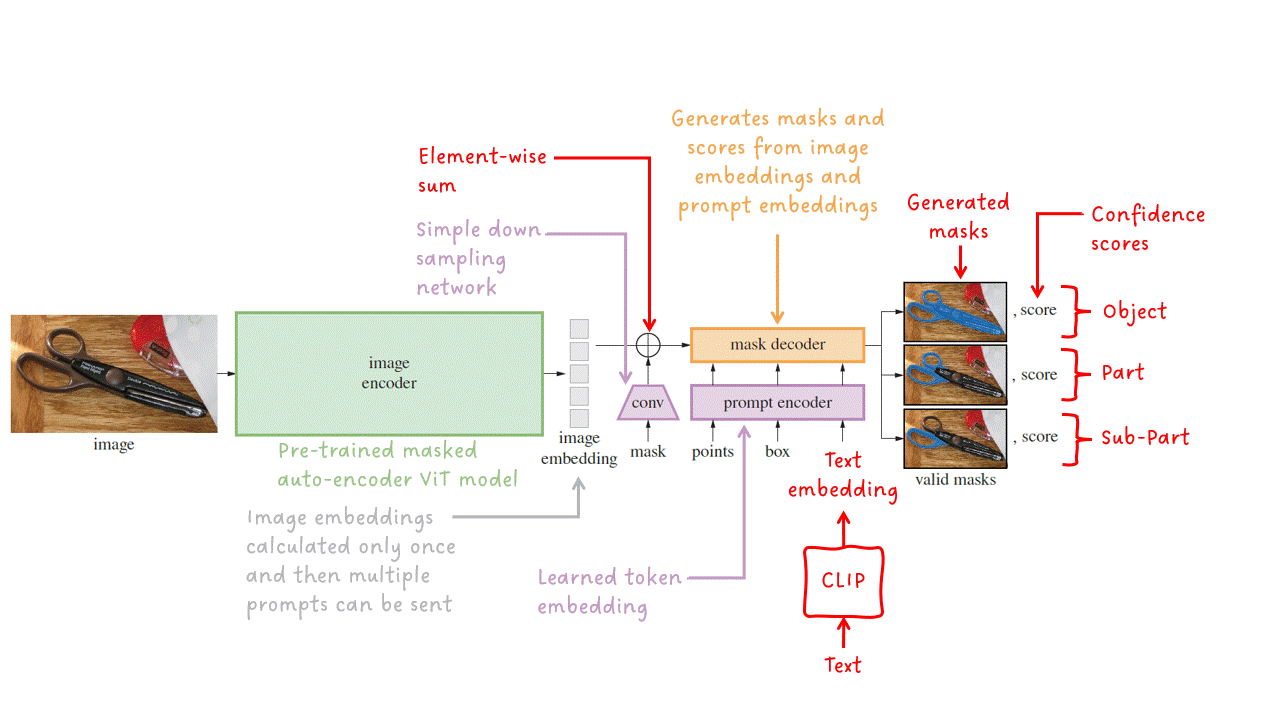
图像编码器 — 为给定的输入图像输出图像嵌入。SAM实现并调整了一个预训练的ViT-H/16掩码自编码器。这是一个相对较大且性能强大的模型。
提示编码器 — 稀疏提示(即点、框和文本)被转化为嵌入向量。文本提示在输入提示编码器之前使用CLIP转化为文本嵌入。密集提示(即掩码)通过步幅卷积进行下采样,并与图像嵌入相加。然后,所有嵌入都被输入到最后一个阶段:掩码解码器。
掩码解码器 — 接收一组图像嵌入(可包含密集掩码嵌入)和一组提示嵌入,并输出有效的分割掩码。
还有两个细节需要解释:提示的不确定性和性能。
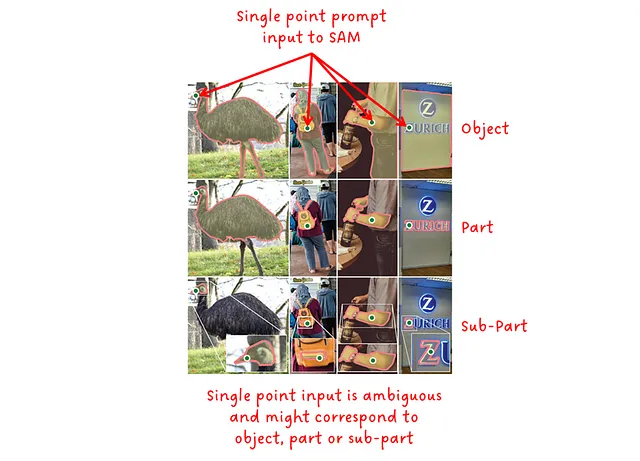
简而言之,提示所包含的上下文越少,它就越不确定,对模型提供正确输出就越困难。对于文本提示,我们已经在CLIP和GLIP中看到了输入文本的具体性与模型性能之间的关联。类似地,仅提供一个点作为输入可能会导致多种可能的掩码。因此,SAM输出一组与图像中的对象级、部分级和子部分级相对应的三个输出掩码,如下图所示。
我要提到的第二个细节是推理速度方面的性能。你有没有注意到图像编码器是SAM中最大的子模块?这个问题其实有点不公平,因为到目前为止我还没有告诉你,但是SAM的设计是为了拥有语义丰富的图像嵌入(通常需要一个大模型),然后在这些嵌入上应用轻量级的提示编码器和轻量级的掩码解码器。好处是:只需要对每个图像运行一次图像编码器,然后可以使用相同的图像嵌入多次提示模型。这使得SAM能够在浏览器中执行,仅需约50毫秒即可对给定提示预测掩码(在计算图像嵌入后)。
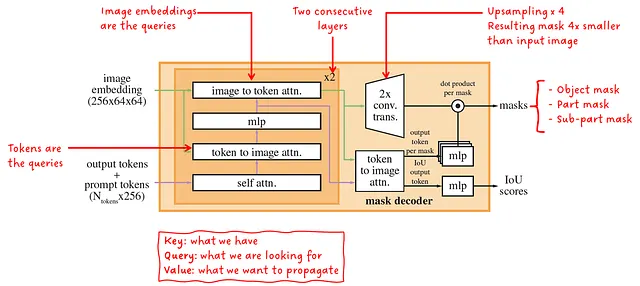
让我们更近距离地看一下轻量级的掩码解码器。它接收图像嵌入和提示嵌入,并输出一组具有相应分数的掩码。在内部,两个连续的解码器块执行自注意力和交叉注意力的组合,以在图像和提示之间生成强依赖关系。一个简单的上采样网络与另一个交叉注意力块组合生成掩码和分数。
SA-1B — 10亿掩膜的数据集
Segment Anything的第二个重大突破是创建和发布了一个大规模的分割数据集。该数据集包含了1100万张高分辨率和授权的图像,大约有11亿个掩膜。虽然原始版本的数据集平均拥有3300×4950像素,但发布版本经过下采样,最短边缩小到1500像素。该数据集在不同场景和每张图像上的掩膜数量方面具有多样性,范围从少于50个到超过500个。

该数据集是通过三阶段数据引擎创建的,其中人工标注的手动标签与由SAM生成的自动标签相结合。
第一阶段:辅助手动阶段 — 一组专业标记人员在早期版本的SAM的辅助下对图像进行标记,该版本是在常见分割数据集上进行训练的。他们被要求标记最突出的对象,并鼓励在30秒后继续。在此阶段结束时,使用新的标签重新训练了SAM(共有12万张图像,430万个掩膜)。
第二阶段:半自动阶段 — 在这个阶段,目标是通过首先让SAM预测一些掩膜,然后让标记人员注释缺失的较不突出的对象,以增加掩膜的多样性。在此阶段结束时,使用新的样本再次对SAM进行了训练(共有30万张图像,1020万个掩膜)。
第三阶段:完全自动阶段 — 在这个阶段,标注是完全自动的。SAM通过32×32点网格生成掩膜,并应用一些后处理。
数据集分析
现在让我们更仔细地看一下论文中介绍的SA-1B数据集的一些分析结果。
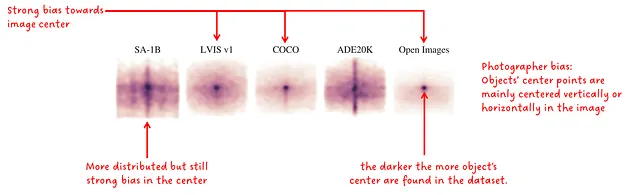
在初步评估中,作者创建了掩膜中心点的归一化分布。有趣的是,这些分布受摄影师的偏见影响,即大多数照片将感兴趣的对象置于图像的中心和主轴。
SA-1B的一个重要优势是每张图像上的掩膜数量较其他数据集更多(图7左)。这也意味着SA-1B有许多小掩膜(图7中)。比较掩膜的凹度,即复杂度的度量,SA-1B与手动标记的其他数据集非常相似(图7右)。

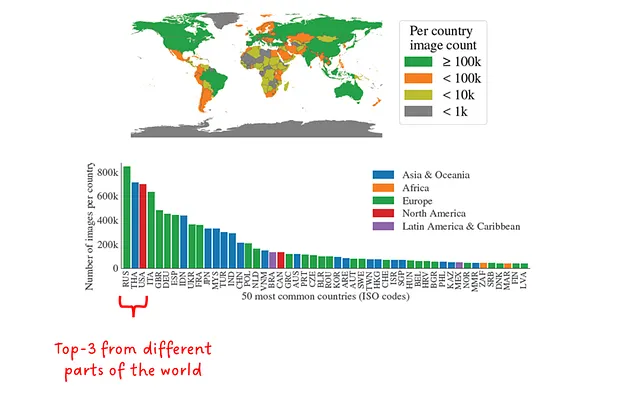
在负责任的AI(RAI)方面非常重视,不仅分析了对某些群体的偏见,还试图减轻这些偏见。如图8所示,世界上大多数国家拥有超过1000张图像,前3个国家来自世界不同地区。虽然低收入国家在相对比例上仍然代表了较少的样本(占总样本的0.9%),但绝对数量仍超过了900万个掩膜,超过了其他分割数据集。
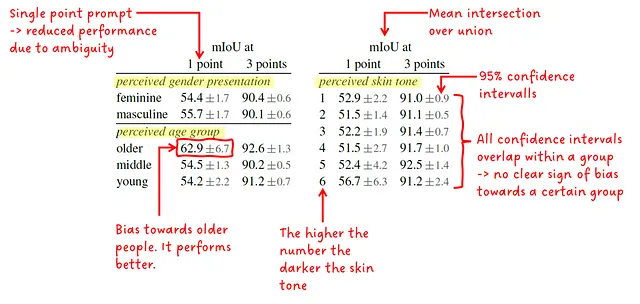
作者进一步调查了感知到的性别展示、感知到的年龄组和感知到的肤色之间的性能差异。他们提供了预测掩码与真实掩码之间的平均IoU(交并比)和95%的置信区间。SAM根据单个点或三个点的提示来运行。关键信息是,结果在同一组内非常相似(并且置信区间重叠),这表明没有任何一组成员受到偏爱。唯一的例外是在感知到的年龄组中的年长人群。
实验与剖析
Segment Anything为我们提供了一系列的实验,主要关注其零样本性能,因为这是作者的主要目标:找到一个可提示的零样本分割模型。我们还知道从其他模型(如CLIP和GLIP)中,提示调整几乎与对模型进行微调一样有效,从而提高性能。
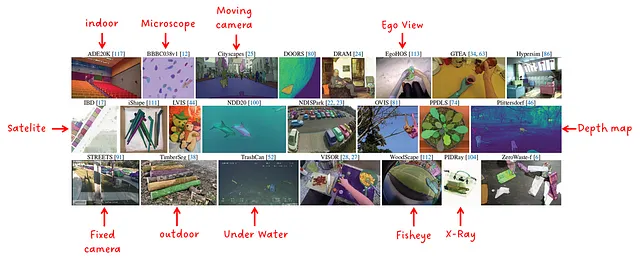
为了进行实验,编制了一个包含23个不同数据集的套件。如图10所示,其中包含了各种数据分布的样本。
零样本单点有效掩码评估
回想一下,零样本意味着模型在评估过程中没有接受过其所暴露的数据的训练。而且要记住,由于其模棱两可性,单点提示是一项相当困难的任务,如图3所示。
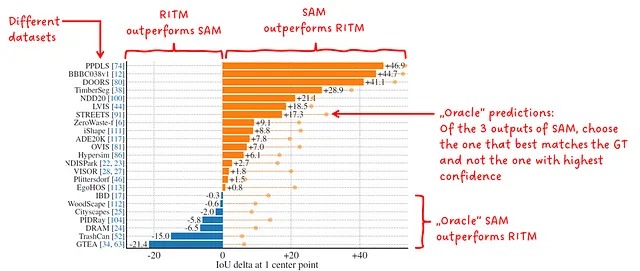
在这个第一个实验中,作者将SAM与RITM进行了比较,后者是一种在他们的基准测试中表现最好的交互式分割器。
记住SAM在接收到一个单点提示时会输出3个不同的掩码,并附带一个得分。在这个实验中,选择得分最高的掩码进行评估。由于有时这种方法是错误的,作者还对最佳掩码进行评估,即将预测与真实掩码进行比较,并选择与之重叠最高的掩码。这些是“oracle”预测。
SAM在23个数据集中的零样本单点有效掩码预测中优于RITM。在进行oracle预测时,它在所有23个数据集中优于RITM。
零样本文本到掩码
在这个实验中,SAM通过文本进行提示。作者称这个特性为概念验证,因此既没有进行详细的实验,也没有在官方代码实现中发布此功能。
从图12可以看出,SAM能够为复杂对象(如“海狸牙格栅”)返回正确的掩码。在其他一些情况下,模型仅通过插入文本提示而失败,他们展示了当以点的形式提供上下文时,SAM能够正确预测单个或多个雨刷,这表明预测不仅考虑了点,还考虑了文本。

零样本边缘检测
有趣的是,SAM也可以用于边缘检测,这是它在训练期间没有考虑过也没有访问过相关数据的任务。
为了预测地图,SAM首先以一个16×16点的网格为输入,得到768个预测的掩模(对于每个256个点的对象、部分和子部分)。然后对结果进行过滤和后处理,得到边缘掩模。
如图13所示,与真实值相比,SAM预测出更多细节。但是公正地说,如果真实值不完整或者涵盖了不同的抽象层次,这种比较对我来说似乎不公平。但总体来说,性能非常好!

零样本实例分割
在这个实验中,SAM使用一个在COCO和LVIS上训练的全监督ViTDet-H的边界框输出作为输入。然后将得到的掩模再次输入SAM,与初始边界框一起进行结果的精炼。ViTDet和SAM的比较如图14所示。

这里需要注意两点:如果你查看COCO和LVIS,你会发现掩模与对象的像素不对齐。这种偏差存在于ViTDet中,所以SAM的质量似乎更好。由于计算的度量标准具有相同的偏差,并且与糟糕的真实值相比,SAM的性能会更差,因此他们请人进行目视检查。其次,为什么这只大象只有三条腿 😅。无论我如何努力,我都看不到第四条腿…
消融实验
在消融实验部分,作者主要关注数据集的规模、提示点的数量和图像编码器的大小的缩放(参见图13)。性能以平均IoU报告。
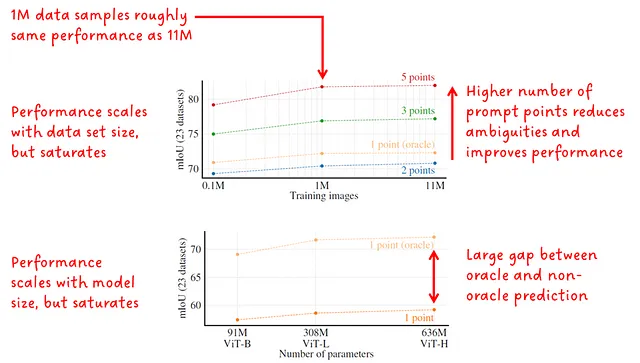
有趣的是,即使缩放数据和模型大小对mIoU性能有影响,但它会饱和。这可能表明模型非常好,没有太多改进的空间,或者可能是他们方法的限制。
结论
Segment Anything介绍了可提示的Segment Anything模型(SAM),以及一个包含超过11百万张图像中超过10亿个掩模的大规模分割数据集。能够提示分割模型带来了很大的灵活性,比如使训练模型适应未见任务或能够检测未知类别。虽然有人争论SAM是否被视为基础模型,因为它是以监督方式训练的,但它仍然展示了出色的结果,并被广泛采用。
进一步阅读和资源
你可能自己知道:深度学习领域发展得非常快。因此,不足为奇的是,在SAM发布后不久,许多新项目都以其成功为基础,进一步改进预测质量、减少推理时间或使模型适用于边缘应用。
以下是一些建立在SAM基础上的有趣资源列表:
- Grounded Segment Anything(基于SAM的图像分割)
- Segment Anything in High Quality(高质量的图像分割)
- Fast Segment Anything(快速的图像分割)
- Faster Segment Anything: Towards Lightweight SAM for Mobile Applications(更快的图像分割:面向移动应用的轻量级SAM)
这里我分享一些链接,如果你想亲自体验SAM和SA-1B:
- SA-1B数据集下载
- 图像分割演示
- 图像分割GitHub
- 用于SAM实验的Python笔记本
这是我分析一些相关基础模型的文章:
CLIP基础模型
论文摘要 – 从自然语言监督中学习可迁移的视觉模型
towardsdatascience.com
GLIP:引入语言-图像预训练到目标检测
论文摘要 – 基于图像的语言-图像预训练
towardsdatascience.com
BYOL – 对比自监督学习的替代方法
论文分析 – Bootstrap Your Own Latent: 一种新的自监督学习方法
towardsdatascience.com






