从纸质到像素:评估数字化手写文本的最佳技术
评估数字化手写文本的最佳技术
OCR、Transformer模型和基于提示工程的集成技术的比较研究
作者:Sohrab Sani和Diego Capozzi
组织长期以来一直在为历史手写文件进行繁琐且昂贵的数字化工作。以前,光学字符识别(OCR)技术,如AWS Textract (TT) [1]和Azure Form Recognizer (FR) [2],一直是这方面的领先者。尽管这些选项可能广泛可用,但它们也存在许多缺点:价格昂贵,需要长时间的数据处理/清理,并且可能导致不理想的准确性。最近,在利用基于Transformer架构的图像分割和自然语言处理的深度学习进展的基础上,出现了一种无需OCR的技术,例如文档理解Transformer(Donut)[3]模型。
在这项研究中,我们将使用我们自定义的数据集,该数据集由一系列手写表单创建,比较OCR和基于Transformer的技术在数字化过程中的表现。这个相对简单的任务的基准测试旨在为处理更长的手写文档的更复杂应用铺平道路。为了提高准确性,我们还尝试使用集成方法,通过利用带有gpt-3.5-turbo大型语言模型(LLM)的提示工程来结合TT和经过微调的Donut模型的输出。
这个工作的代码可以在这个GitHub存储库中查看。数据集可以在我们的Hugging Face存储库中获取。
目录:
· 数据集创建· 方法 ∘ Azure Form Recognizer(FR)∘ AWS Textract(TT)∘ Donut∘ 集成方法:TT,Donut,GPT· 模型性能的测量 ∘ FLA ∘ CBA ∘ 覆盖范围 ∘ 成本· 结果· 其他考虑因素 ∘ Donut模型训练 ∘ 提示工程的可变性· 结论· 下一步· 参考文献· 致谢
数据集创建
这项研究使用了来自NIST特殊数据库19数据集的2100个手写表单图像创建了一个自定义数据集[4]。图1展示了其中一个表单的示例图像。最终的数据集包括2099个表单。为了筛选这个数据集,我们裁剪了每个NIST表单的顶部部分,目标是日期、城市、州和邮政编码(现在称为“ZIP”)键,在红色框中突出显示[图1]。这种方法启动了一个相对简单的文本提取任务的基准测试过程,使我们能够快速选择和手动标记数据集。在撰写本文时,我们不知道是否有任何公开可用的带有手写表单图像的标记数据集,可以用于JSON键字段文本提取。
我们从文档中手动提取了每个键的值,并对其进行了准确性检查。总共,有68个表单因至少包含一个不可读字符而被丢弃。表单中的字符记录的是它们实际出现的方式,无论拼写错误或格式不一致。
为了在缺失数据上微调Donut模型,我们添加了67个空表单,以便为这些空字段进行训练。表单中的缺失值在JSON输出中表示为“None”字符串。
图2a展示了我们数据集中的一个样本表单,而图2b显示了与该表单相关联的JSON。
表1提供了数据集中每个键的变异性的详细信息。从最多变异到最少变异的顺序是ZIP、CITY、DATE和STATE。所有日期都在1989年内,这可能降低了整体DATE的变异性。此外,尽管只有50个美国州,但由于使用了不同的缩写词或区分大小写的拼写方式,STATE的变异性增加了。
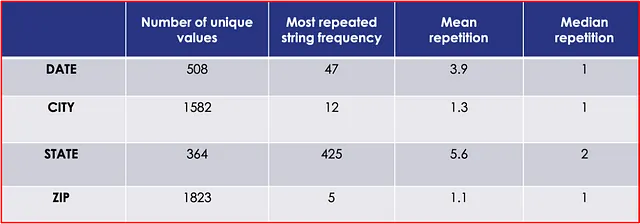
表2总结了我们的数据集各个属性的字符长度。
以上数据显示,CITY条目具有最长的字符长度,而STATE条目具有最短的字符长度。每个条目的中值与其相应的均值非常接近,表明每个类别的字符长度围绕着平均值呈相对均匀的分布。
在对数据进行注释之后,我们将其分成三个子集:训练集、验证集和测试集,分别具有1400、199和500个样本。这是我们用于此操作的笔记本的链接。
方法
我们将逐一介绍我们测试的每种方法,并将其链接到包含更多详细信息的相关Python代码。首先单独描述方法的应用,即FR、TT和Donut,然后使用TT+GPT+Donut集成方法进行次要描述。
Azure表单识别(FR)
图3描述了使用Azure FR从我们的表单图像中提取手写文本的工作流程:
- 存储图像:可以在本地驱动器或其他解决方案(例如S3存储桶或Azure Blob存储)上存储图像。
- Azure SDK:用于从存储中加载每个图像并通过Azure SDK将其传输到FR API的Python脚本。
- 后处理:使用现成的方法意味着最终输出通常需要进行改进。以下是需要进一步处理的提取的21个键:[‘DATE’,’CITY’,’STATE’,’DATE’,’ZIP’,’NAME’,’E ZIP’,’·DATE’,’.DATE’,’NAMR’,’DATE®’,’NAMA’,’_ZIP’,’.ZIP’,’print the following shopsataca i’,’-DATE’,’DATE.’,’No.’,’NAMN’,’STATE\nZIP’]一些键上有额外的点或下划线,需要删除。由于表单中的文本位置接近,有许多情况下提取的值错误地与不正确的键关联。然后,这些问题在合理的程度上得到解决。
- 保存结果:以pickle格式将结果保存在存储空间中。
AWS Textract(TT)
图4描述了使用AWS TT从我们的表单图像中提取手写文本的工作流程:
- 存储图像:图像存储在S3存储桶中。
- SageMaker Notebook:笔记本实例便于与TT API交互,执行脚本的后处理清理,并保存结果。
- TT API:这是由AWS提供的现成的基于OCR的文本提取API。
- 后处理:使用现成的方法意味着最终输出通常需要进行改进。TT生成的数据集具有68列,比FR方法的21列多。这主要是由于在图像中检测到的额外文本被认为是字段。这些问题在基于规则的后处理过程中得到解决。
- 保存结果:然后使用pickle格式将精炼的数据存储在S3存储桶中。
Donut
与现成的基于OCR的方法相比,这一部分探讨了使用基于Transformer模型架构的Donut模型来改进无OCR方法,该方法能够通过自定义字段和/或模型再训练来适应特定的数据输入。
首先,我们使用我们的数据对Donut模型进行了微调,然后将该模型应用于我们的测试图像以以JSON格式提取手写文本。为了高效地重新训练模型并避免过拟合,我们使用了PyTorch Lightning中的EarlyStopping模块。训练批次大小为2,在经过14个周期后训练终止。以下是Donut模型微调过程的更多详细信息:
- 我们将1,400张图像用于训练,199张用于验证,剩余的500张用于测试。
- 我们使用naver-clova-ix/donut-base作为我们的基础模型,该模型可以在Hugging Face上获取。
- 然后,使用Quadro P6000 GPU(24GB内存)对该模型进行了微调。
- 整个训练时间约为3.5小时。
- 有关更复杂的配置详细信息,请参阅存储库中的
train_nist.yaml。
该模型也可以从我们的Hugging Face空间存储库中下载。
集成方法:TT,Donut和GPT
我们尝试了多种集成方法,其中TT,Donut和GPT的组合效果最好,如下所述。
一旦通过单独应用TT和Donut获得了JSON输出,这些输出将作为输入传递给一个提示,并传递给GPT。目标是使用GPT将这些JSON输入中的信息与上下文GPT信息相结合,创建一个具有增强内容可靠性和准确性的新/更干净的JSON输出[表3]。图5提供了这种集成方法的视觉概述。
为此任务创建适当的GPT提示是一个迭代的过程,需要引入临时规则。调整GPT提示以适应此任务 – 以及可能是数据集 – 是本研究需要探索的一个方面,如“其他注意事项”部分所述。
模型性能的测量
本研究主要通过使用两种不同的准确度指标来衡量模型性能:
- 字段级准确度(FLA)
- 基于字符的准确度(CBA)
还测量了其他指标,如覆盖率和成本,以提供相关的上下文信息。以下是所有指标的描述。
FLA
这是一个二进制度量:如果预测的JSON中的键的所有字符与参考JSON中的字符完全匹配,则FLA为1;但是,如果只有一个字符不匹配,则FLA为0。
考虑以下示例:
JSON1 = {'DATE': '8/28/89', 'CITY': 'Murray', 'STATE': 'KY', 'ZIP': '42171'}JSON2 = {'DATE': '8/28/89', 'CITY': 'Murray', 'STATE': 'KY', 'ZIP': '42071'}使用FLA比较JSON1和JSON2的结果得分为0,因为ZIP不匹配。然而,将JSON1与自身进行比较,FLA得分为1。
CBA
该准确度衡量方法的计算如下:
- 确定每个对应值对的Levenshtein编辑距离。
- 通过将所有距离相加并除以每个值的总字符串长度来获得归一化得分。
- 将此得分转换为百分比。
两个字符串之间的Levenshtein编辑距离是将一个字符串转换为另一个字符串所需的更改次数。这涉及到计算替换、插入或删除的次数。例如,将“marry”转换为“Murray”需要两个替换和一个插入,总共三个更改。这些修改可以按不同的顺序进行,但至少需要三个操作。为了进行这个计算,我们使用了NLTK库中的edit_distance函数。
下面是一个代码片段,演示了所描述算法的实现。该函数接受两个JSON输入,并返回一个准确度百分比。
def dict_distance (dict1:dict, dict2:dict) -> float: distance_list = [] character_length = [] for key, value in dict1.items(): distance_list.append(edit_distance(dict1[key].strip(), dict2[key].strip())) if len(dict1[key]) > len(dict2[key]): character_length.append((len(dict1[key]))) else: character_length.append((len(dict2[key]))) accuracy = 100 - sum(distance_list)/(sum(character_length))*100 return accuracy为了更好地理解该函数,让我们看一下它在以下示例中的表现:
JSON1 = {'DATE': '8/28/89', 'CITY': 'Murray', 'STATE': 'KY', 'ZIP': '42171'}JSON2 = {'DATE': 'None', 'CITY': 'None', 'STATE': 'None', 'ZIP': 'None'}JSON3 = {'DATE': '8/28/89', 'CITY': 'Murray', 'STATE': 'None', 'ZIP': 'None'}dict_distance(JSON1, JSON1): 100% JSON1和JSON1之间没有任何差异,因此我们得到了100%的完美得分。dict_distance(JSON1, JSON2): 0% JSON2中的每个字符都需要更改才能与JSON1匹配,得分为0%。dict_distance(JSON1, JSON3): 59% JSON3中STATE和ZIP键的每个字符都必须更改才能与JSON1匹配,这导致准确度得分为59%。
现在,我们将关注分析图像样本中CBA的平均值。这两个准确度测量非常严格,因为它们衡量的是检查字符串是否完全匹配。由于FLA具有二进制特性,它对部分正确的情况视而不见,因此FLA尤其保守。尽管CBA比FLA保守性较低,但仍被认为是相对保守的。此外,CBA能够识别部分正确的实例,但它还考虑文本大小写,这可能在重点是恢复文本的适当内容还是保留书面内容的确切形式时具有不同的重要程度。总体而言,我们决定使用这些严格的测量方法来进行更保守的方法,因为我们将文本提取的正确性优先于文本语义。
覆盖率
覆盖率被定义为输出JSON中已提取的表单图像字段的比例。这有助于监控从表单中提取所有字段的整体能力,而不考虑其正确性。如果覆盖率非常低,说明某些字段在提取过程中被系统性地遗漏。
成本
这是将每种方法应用于整个测试数据集所产生的简单估计成本。我们没有捕捉微调Donut模型的GPU成本。
结果
我们对测试数据集中的所有方法的性能进行了评估,该数据集包含500个样本。这个过程的结果总结在表3中。
使用FLA时,我们观察到更传统的基于OCR的方法FR和TT的性能相似,准确度较低(FLA〜37%)。虽然不是理想的,但这可能是由于FLA的严格要求。另外,当使用CBA Total时,即考虑所有JSON键的平均CBA值时,TT和FR的性能要好得多,得到的值大于77%。特别是TT(CBA Total = 89.34%)的性能优于FR约15%。当专注于针对单个表单字段测量的CBA值时,尤其是在DATE和CITY类别中[表3],以及在整个样本中测量FLA和CBA Totals时(TT:FLA = 40.06%;CBA Total = 86.64%;FR:FLA = 35.64%;CBA Total = 78.57%),这种行为得以保持。虽然应用这两个模型的成本值相同,但TT更适合提取所有表单字段,其覆盖率值比FR高约9%。
通过量化这些更传统的基于OCR的模型的性能,我们得到了一个基准,然后用这个基准来评估使用纯Donut方法与使用TT和GPT相结合的优势。我们首先使用TT作为我们的基准。
利用这种方法的好处通过Donut模型的改进指标得到体现,该模型在1400个图像及其对应的JSON样本大小上进行了微调。与TT的结果相比,该模型的全局FLA为54%,CBA Total为95.23%,分别提高了38%和6%。FLA的增加最为显著,表明该模型能够准确地检索出超过一半的测试样本的所有表单字段。
考虑到用于微调模型的图像数量有限,CBA的增加是显著的。Donut模型显示出了优势,这可从覆盖率和基于键的CBA指标的整体改善值中得到证明,这些值增加了2%至24%。覆盖率达到了100%,表明该模型可以从所有表单字段中提取文本,从而减少了将这样的模型投入生产所需的后期处理工作。
基于这个任务和数据集,这些结果说明使用经过微调的Donut模型产生的结果优于OCR模型。最后,还探讨了集成方法,以评估是否可以继续进行额外的改进。
由TT和经过微调的Donut组成的集成模型的性能,由gpt-3.5-turbo提供支持,显示出如果选择特定的指标(如FLA),则可以实现改进。与我们经过微调的Donut模型相比,该模型的所有指标(不包括CBA State和覆盖率)都显示出增加,增加范围在约0.2%至约10%之间。唯一的性能下降出现在CBA State中,相对于我们经过微调的Donut模型的值,下降了约3%。这可能是由于所使用的GPT提示的原因,可以进一步进行微调以改善这个指标。最后,覆盖率的值保持不变,为100%。
与其他各个字段相比,日期提取(参见CBA Date)具有更高的效率。这可能是由于日期字段的变异性有限,因为所有日期均源自1989年。
如果性能要求非常保守,则FLA的10%增加是显著的,可能值得建立和维护更复杂的基础设施的更高成本。这也应考虑到由LLM提示修改引入的变异性来源,这在其他考虑因素部分中有所说明。然而,如果性能要求不太严格,则集成方法产生的CBA指标改进可能不值得额外的成本和努力。
总体而言,我们的研究表明,尽管个别的基于OCR的方法,即FR和TT,各有优势,但仅仅在1400个样本上进行微调的Donut模型轻松超越了它们的准确性基准。此外,将TT和经过微调的Donut模型通过gpt-3.5-turbo提示进行集成,通过FLA指标衡量,进一步提高了准确性。还必须对Donut模型的微调过程和GPT提示进行其他考虑,这将在下一节中进行探讨。
其他考虑因素
Donut模型的训练
为了提高Donut模型的准确性,我们尝试了三种训练方法,每种方法旨在提高推理准确性,同时防止过拟合训练数据。表4显示了我们的结果总结。
1. 30轮训练:我们使用Donut GitHub仓库中提供的配置对Donut模型进行了30轮训练。这次训练持续了大约7个小时,FLA达到了50.0%。不同类别的CBA值有所不同,其中CITY的值为90.55%,ZIP的值为98.01%。然而,我们注意到在第19轮训练后,当我们检查val_metric时,模型开始出现过拟合的情况。
2. 19轮训练:根据初始训练的经验,我们只对模型进行了19轮微调。我们的结果显示FLA有了显著提高,达到了55.8%。整体的CBA以及基于关键词的CBA都显示出了提高的准确性。尽管这些指标很有希望,但我们注意到val_metric表明存在轻微过拟合的迹象。
3. 14轮训练:为了进一步改进我们的模型并避免潜在的过拟合,我们使用了PyTorch Lightning中的EarlyStopping模块。这种方法在14轮训练后终止了训练。结果FLA达到了54.0%,而CBA与19轮训练相比是可比甚至更好的。
当比较这三个训练会话的输出时,尽管19轮训练的FLA略微更好,但14轮训练的CBA指标整体上更优秀。此外,val_metric加强了我们对19轮训练的担忧,表明存在轻微的过拟合倾向。
总结起来,我们得出结论,通过使用EarlyStopping进行14轮微调的模型既最为稳健,又最为经济高效。
提示工程的变异性
我们进行了两种提示工程方法(ver1和ver2),通过将经过微调的Donut模型和TT的结果进行集成,以提高数据提取的效率。在进行了14轮训练后,Prompt ver1显示出了优秀的结果,FLA达到了59.6%,并且所有关键词的CBA指标都较高[表5]。相比之下,Prompt ver2的结果有所下降,FLA降至54.4%。对CBA指标进行详细分析发现,与ver1相比,ver2的每个类别的准确性得分都稍微降低,突显了这一变化的显著差异。
在对数据集进行手动标注的过程中,我们利用了TT和FR的结果,并在标注表单文本时开发了Prompt ver1。尽管与前身本质上相同,Prompt ver2经过了轻微的修改。我们的主要目标是通过消除Prompt ver1中的空行和冗余空格来完善提示。
总之,我们的实验突出了看似微小调整的微妙影响。虽然Prompt ver1展示了更高的准确性,但将其精简为Prompt ver2的过程,反而在所有指标上降低了性能。这突显了提示工程的复杂性,以及在最终确定使用的提示之前需要进行细致测试的必要性。
Prompt ver1在这个笔记本中可用,Prompt ver2的代码可以在这里查看。
结论
我们创建了一个用于从包含四个字段(DATE、CITY、STATE和ZIP)的手写表单图像中提取文本的基准数据集。这些表单已经手动注释为JSON格式。我们使用这个数据集来评估基于OCR的模型(FR和TT)以及通过我们的数据集进行微调的Donut模型。最后,我们使用TT和我们经过微调的Donut模型的输出通过提示工程构建了一个集成模型。
我们发现TT的表现优于FR,并将其作为一个基准来评估Donut模型在独立使用或与TT和GPT(即集成方法)相结合时可能产生的改进。正如模型性能指标所显示的,这个经过微调的Donut模型显示出明显的准确性提高,这证明了它在OCR模型上的应用的合理性。集成模型在FLA上显示出了显著的改进,但成本较高,因此只适用于对性能要求更严格的情况。尽管采用了一致的基础模型gpt-3.5-turbo,但我们观察到当提示发生微小变化时,输出JSON表单会有显著差异。这种不可预测性是在生产中使用现成的LLM时的一个重要缺点。我们目前正在开发一个基于开源LLM的更紧凑的清理过程来解决这个问题。
下一步
- 表2中的价格列显示OpenAI API调用是本工作中使用的最昂贵的认知服务。因此,为了最大程度地降低成本,我们正在通过使用全面微调、提示微调[5]和QLORA [6]等方法来微调一个用于seq2seq任务的LLM。
- 出于隐私原因,数据集中图像上的姓名框被黑色矩形覆盖。我们正在更新数据集,通过为数据集添加随机的名字和姓氏,从而将数据提取字段从四个增加到五个。
- 将来,我们计划通过将这项研究扩展到整个表格或其他更广泛的文档的文本提取,来增加文本提取任务的复杂性。
- 研究Donut模型的超参数优化。
参考文献
- Amazon Textract, AWS Textract
- 表格识别器,表格识别器(现为文档智能)
- Kim, Geewook and Hong, Teakgyu and Yim, Moonbin and Nam, JeongYeon and Park, Jinyoung and Yim, Jinyeong and Hwang, Wonseok and Yun, Sangdoo and Han, Dongyoon and Park, Seunghyun, OCR-free Document Understanding Transformer (2022), European Conference on Computer Vision (ECCV)
- Grother, P. and Hanaoka, K. (2016) NIST手写表单和字符数据库(NIST特殊数据库19)。DOI: http://doi.org/10.18434/T4H01C
- Brian Lester, Rami Al-Rfou, Noah Constant, The Power of Scale for Parameter-Efficient Prompt Tuning (2021), arXiv:2104.08691
- Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer, QLoRA: Efficient Finetuning of Quantized LLMs (2023), https://arxiv.org/abs/2305.14314
致谢
我们要感谢我们的同事Dr. David Rodrigues,感谢他对这个项目的持续支持和讨论。我们还要感谢Kainos的支持。






