现代自然语言处理:详细概述第一部分:转换器
现代自然语言处理:详细概述第一部分:转换器' Condensed result 现代自然语言处理:详细概述第一部分:转换器

在过去的五年中,我们在自然语言处理领域取得了巨大的成就,引入了BERT和GPT等思想。本文旨在逐步深入研究这些改进的细节,并看到它们带来的演变。
注意力是你所需要的
2017年,来自Google Brains的Ashish Vaswani与多伦多大学的同事们提出了一种用于序列到序列任务的新思想,如神经语言翻译和改写,与LSTM和RNN等现有的逐字逐步方法不同。
检测到RNN现有架构的问题包括:
- Meta发布LLaMA 2 商业免费使用
- GPT-Engineer:你的新的AI编程助手
- OmniSpeech成为Cadence Tensilica音频软件合作伙伴,为下一代人工智能语音算法提供更好的汽车、移动、消费者和物联网客户服务
- 在添加一个词时,在长序列的情况下,很难保留信息。在使用RNN和LSTM的编码器-解码器结构模型中,隐藏向量从一个时间戳传递到另一个时间戳。然后,在最后一步,我们将最终的上下文向量传递给解码器。传递给解码器的隐藏上下文向量对序列的最后几个词的影响要大于对序列的前几个词的影响,因为信息随时间逐渐消失。
- 为了解决第一个问题,引入了注意力机制。这意味着在解码过程中,我们单独关注输入序列中的每个单词。输入序列中的每个单词都获得一个特定的注意力权重向量,然后将该单词向量乘以权重向量以创建向量的加权和。但问题是,由于我们一次只执行一步操作,计算时间过长,并且并没有完全消除信息丢失。
这个想法
Transformer建议使用了一个称为自注意力的概念。模型一次接收整个句子,然后使用自注意力来决定当前单词在句子中的其他单词的重要性。因此,与传统的循环架构相比,它具有一些优势:
- 在检测权重时,我们已经有了所有的单词,因此不存在信息丢失的可能性,而且我们从两个方向上获得了上下文。也就是说,我们既了解所选单词之前的单词,也了解跟随它的单词,这有助于形成更好的上下文,而不是循环结构(除了双向LSTM的情况)。
- 由于我们拥有完整的句子,并且需要找到每个单词对句子中所有其他单词的重要性,我们可以同时为所有单词进行操作。这节省了很多处理时间,并充分利用了处理能力。
自注意力: 基本构件
自注意力机制试图找出其他单词相对于特定单词的重要程度,然后创建一个组合的上下文向量来表示该单词。基本上,这意味着,如果你选择一个句子中的单词,那么它与句子中的其他单词有多大关联?正如我们所知,单词定义了句子的上下文,并且单词的意义往往取决于该上下文。这是一种找出句子和相关单词上下文的方法。
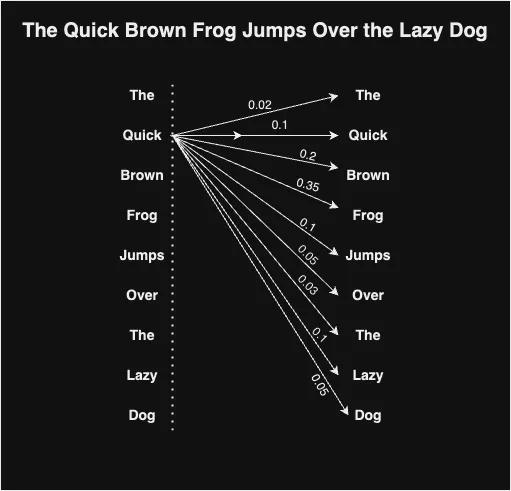
为了实现这一点,它使用三个向量,即查询(Query,Qi),键(Key,Ki)和值(Value,Vi),对句子中的每个输入词嵌入(xi)进行表示。根据论文的建议,嵌入向量x的长度建议为512。为了获得这些向量,首先定义了三个权重矩阵:Wq,Wv和Wk。我们将每个输入词向量Xi与相应的权重矩阵相乘,以获得给定单词的结果键、查询和值向量。
Qi = Xi * Wq
Vi = Xi * Wv
Ki = Xi * Wk
为了找出单词xi在单词xj上下文中的重要性,我们需要找到与单词xi对应的关键向量Ki和单词xj的查询向量Qj的标量点积。然后,将点积结果除以向量Ki的维度的平方根,即8,因为根据论文给出的k的维度为64。正如论文建议的那样,如果我们不进行除法运算,点积的值会变得过大,导致softmax值变得过陡,从而产生平滑学习的不良梯度。
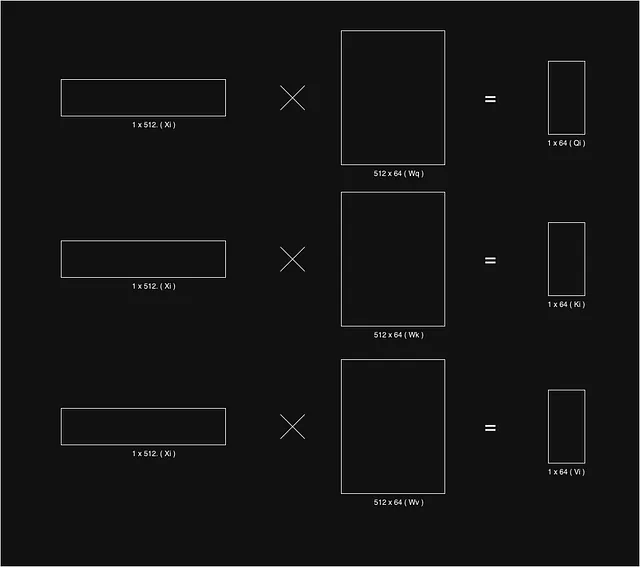
一旦我们找出给定单词的所有单词的重要性,我们对所有单词的结果使用softmax函数。softmax函数提供了所有单词的最终重要性,使它们的总和为1。接下来是单词的值向量Vi,我们将向量Vi与其对应的重要性相乘。这样做的直觉是值向量创建单词的表示,而重要性因子为主题单词的上下文提供权重。如果一个单词与上下文单词没有关系,它的重要性值将非常低,因此最终的乘积向量将非常低,我们可以忽略它对任务的意义。最后,我们将所有这些加权值向量的总和作为该特定单词的最终上下文向量,这是我们从注意力块中获得的。

多头注意力
我们已经看到了注意力是如何工作并为每个单词产生上下文向量的。论文的作者使用多头注意力来获得一个无偏的综合上下文向量。他们使用了8个这样的注意力头,为一个单词提供8个不同的上下文向量。其思想是,由于每个内部的权重矩阵(Wq、Wv和Wk)都是随机初始化的,因此每个头中初始化点的变化可能有助于捕捉上下文向量中的一系列不同特征。
最后,对于每个单词,我们有8个上下文向量,我们将它们连接在一起,以获得给定单词的代表性上下文向量。
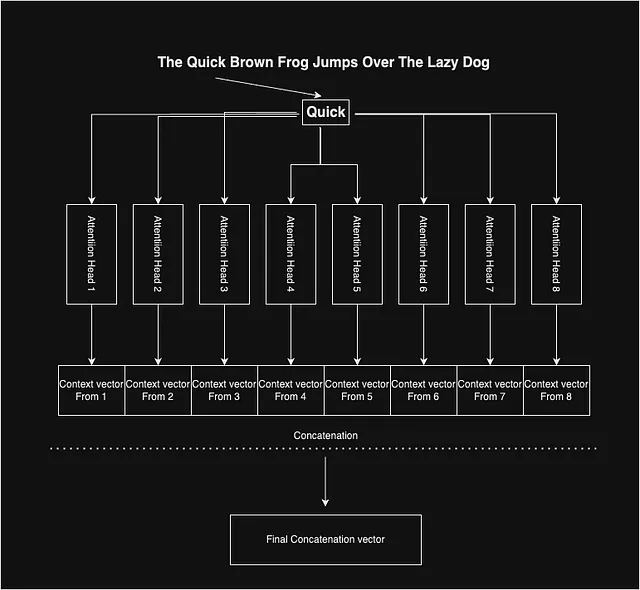
自注意力块:将所有内容整合在一起
到目前为止,我们所讨论的都是基于句子中的一个特定单词,但我们确实需要考虑句子中的所有单词并使系统并行化。
论文建议我们使用长度为512的嵌入来表示句子中的每个单词。现在,我们已经知道,在自然语言处理任务中,我们通常需要使用零填充来使句子长度相等。接下来,我们将所有512维的单词向量堆叠在一起,由于句子中的单词数量是固定的,我们得到一个固定维度的二维向量来表示整个句子,并将其通过整个注意力机制。
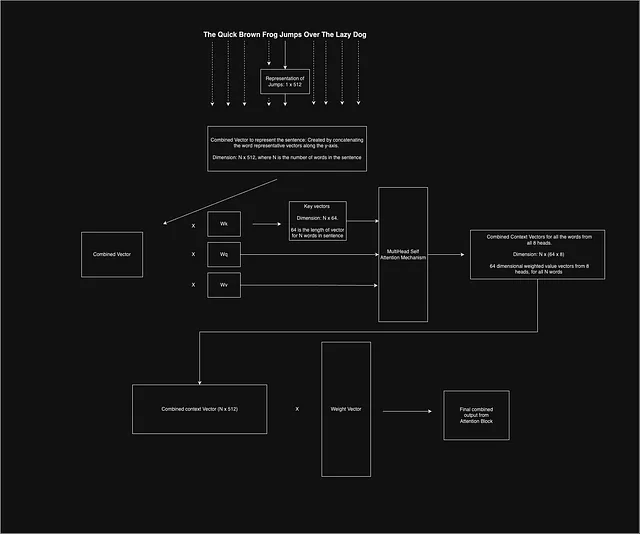
一旦我们获得了所有单词的组合上下文向量,它会被另一个权重矩阵乘以,以集中学习并减小向量的维度。
Transformer:架构
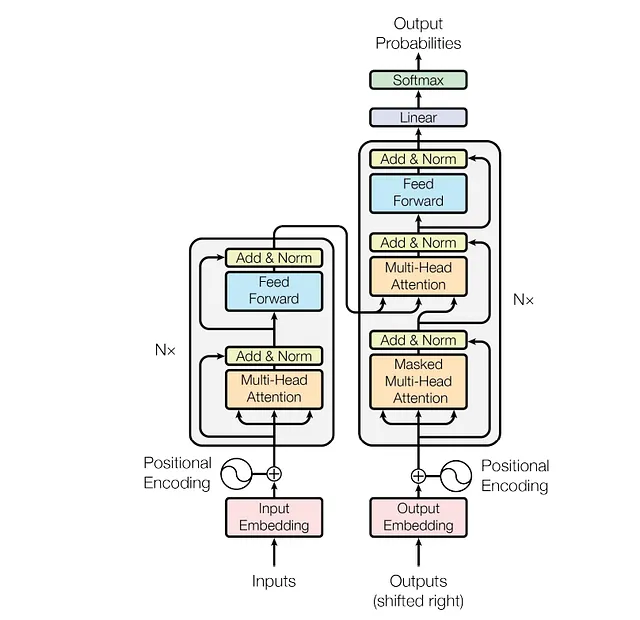
Transformer模型也遵循标准的编码器-解码器架构。为了便于学习和更好的理解,单词向量和层输出的维度都保持在512。模型的学习是以自回归的方式进行的,即逐个生成单词,对于预测第(t+1)个单词,我们将第t个单词的输出连接到输入中,然后输入到模型中。
编码器:作者使用了包含两个子层的模块。第一层包含多头注意力机制,我们上面已经讨论过了,第二个子层是一个全连接前馈层。前馈层由两个连接的普通神经网络层组成。前馈层的输入和输出维度均为512,但内部维度为2048,即内部层中的节点数为2048。全连接层采用ReLU激活函数。作者还使用了一个加法和归一化层,以平滑学习过程并避免信息损失,正如我们在几个自然语言处理和计算机视觉案例中所看到的那样。
因此,方程变为
输出 = Norm( x + f(x)),其中x是输入,f()是层的变换,可以是前馈层或注意力块。
编码器块中有6个这样的模块。
解码器:这与编码器块非常相似。它也有6个模块和类似的架构。唯一的区别是除了已经存在的2个子层外,解码器块引入了第三个子层,也是一个注意力层,但输入被掩码处理,以便模型在预测第t个单词时不能使用第(t+1)个时间步的单词。没有掩码的多头注意力子层从相应层的编码器中获取值。因此,该层接收来自前一个解码器层和相应编码器层的输入。
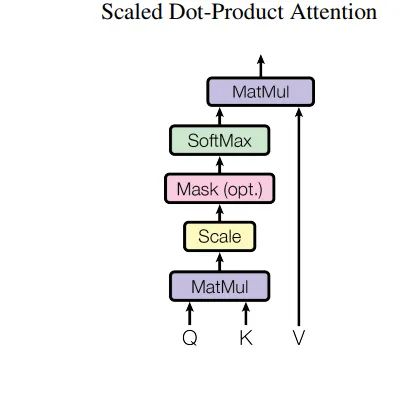
作者在训练过程中以三种不同方式使用了注意力层。正如我们已经知道的,我们将关键词、查询和值三个向量输入到注意力块中,作者使用这一点来更好地训练模型。
选项1:在这种情况下,查询来自前一个解码器层,记忆的键和值来自编码器的输出。这允许解码器中的每个位置都能够关注输入序列中的所有位置。

选项2:在这种情况下,值和查询来自编码器中前一层的输出。编码器中的每个位置都能够关注编码器前一层的所有位置。
选项3:在这种情况下,值和查询来自解码器中前一层的输出。解码器中的每个位置都能够关注解码器前一层的所有位置。现在,这就体现了掩码多头注意力的重要性,因为模型不能看到t+1时刻的单词,自回归属性得到了保留。
最后,作者使用了一个线性变换层,然后是一个softmax层。
位置编码
除了模型之外,这篇论文还引入了位置编码的概念。问题是,由于这篇论文不使用循环或卷积网络,也不是基于时间步的,作者认为应该有一种方式来表示单词的位置,因为位置在表达句子的含义中起着重要作用。
为了解决这个问题,作者提出了两种估计方法。
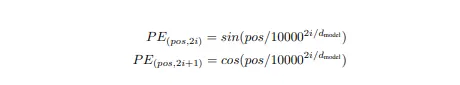
其中pos是单词的位置,i是维度,dmodel = 512,输入维度大小。编码的尺寸也保持在512维,因此可以轻松地与单词嵌入相加。作者选择了这些特定函数,因为这些函数在某个偏移量之后给出相同值的倍数,因此可以表示为线性函数。
结论
我们已经了解了transformers的工作原理;接下来,我们还将学习其他的演进以及它们的实现方式。
在那之前,祝您阅读愉快!!!






