遇见WavJourney:一种基于大型语言模型的音频创作AI框架
WavJourney An AI framework for audio creation based on large-scale language models


多模态人工智能(AI)的新兴领域将视觉、听觉和文本数据融合,为个性化娱乐和改进的辅助功能等各个领域提供了令人兴奋的潜力。作为一个强大的中介,自然语言在增强各种感官领域的理解和交流方面具有巨大的潜力。大型语言模型(LLMs)作为代理人,在与各种AI模型合作解决多模态挑战方面展示了令人印象深刻的能力。
虽然LLMs在解决多模态任务方面的效果备受赞赏,但是一个问题出现了,即这些模型的基本能力是什么:它们是否也可以作为动态多媒体内容的创作者?多媒体内容创作涉及以各种形式(如文本、图像和音频)生成数字媒体。音频作为多媒体的一个重要组成部分,不仅提供上下文和情感,还为沉浸式体验做出贡献。
过去的努力利用生成模型根据特定条件(如语音或音乐描述)合成音频上下文。然而,这些模型通常难以在这些条件之外生成多样化的音频内容,从而限制了它们在现实世界中的适用性。由于生成复杂的听觉场景的复杂性,组合音频创作存在固有的挑战。利用LLMs进行这项任务涉及到解决诸如上下文理解和设计、音频制作和创作以及建立交互式和可解释的创作流程等挑战。这些挑战包括增强LLMs的文本到音频叙事能力,协调音频生成模型,以及创建人机协作的交互式、可解释的流程。
基于上述问题和挑战,提出了一种新颖的系统称为WavJourney。其概述如下所示。
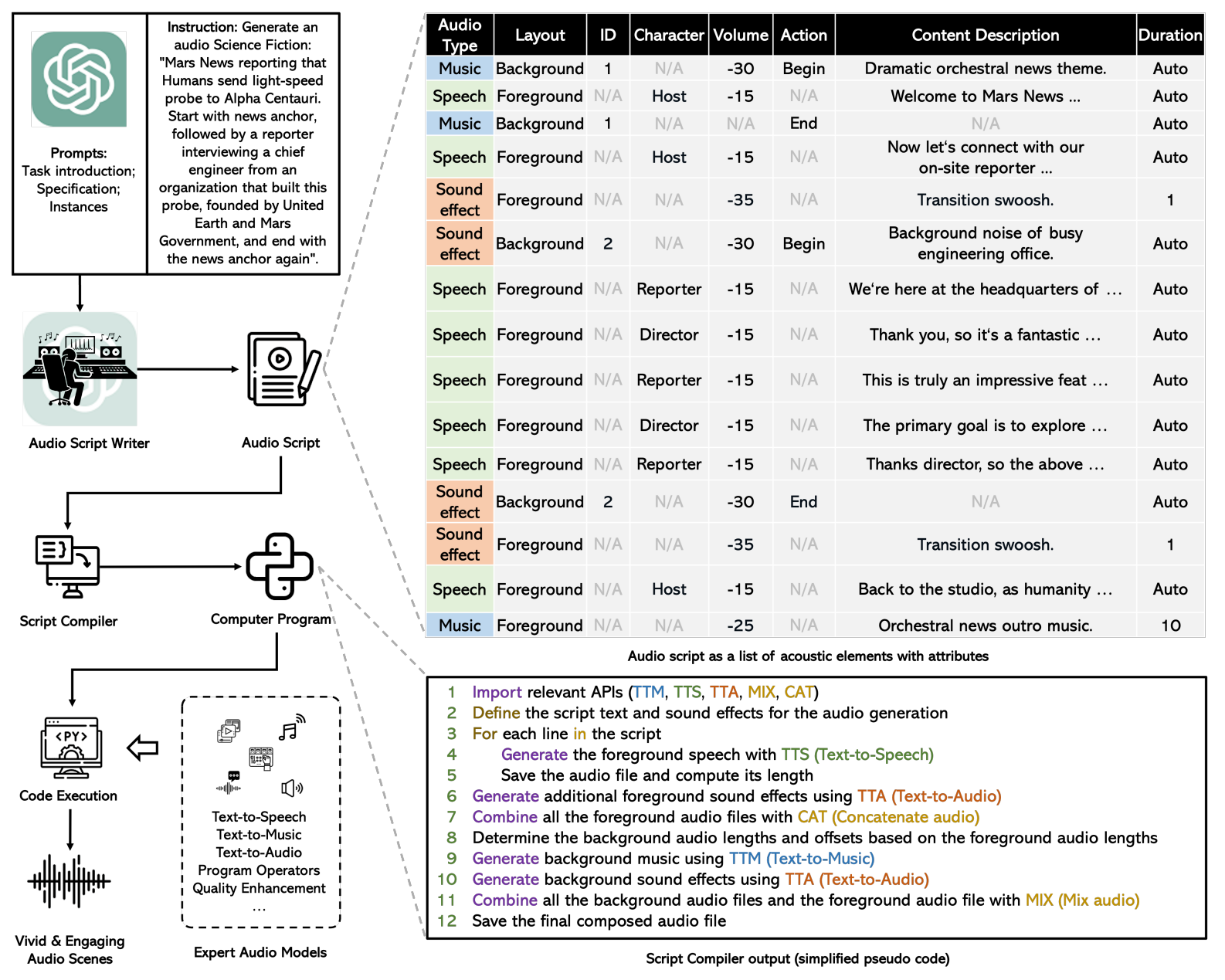

WavJourney利用LLMs来创建根据语言指令引导的组合音频。这种技术促使LLMs生成音频脚本,遵循包含语音、音乐和音效的预定义结构。这些脚本精细考虑了这些声学元素之间的时空关系。对于复杂的听觉场景,WavJourney将其分解为各个声学组件及其相应的声学布局。然后将这个音频脚本输入到一个脚本编译器中,生成一个计算机程序,其中每一行代码对应于调用特定任务的音频生成模型、音频输入/输出函数或计算操作。然后执行此程序以生成所需的音频内容。
WavJourney的设计提供了几个显著的好处。首先,它利用LLMs的理解和广泛知识来制作具有多样化声音元素、复杂声学连接和引人入胜的音频叙述的音频脚本。其次,它采用了组合策略,将复杂的听觉场景分解为不同的声音元素。这使得可以将多种任务特定的音频生成模型用于内容创作,使其与往往难以考虑所有文本描述元素的端到端方法有所区别。第三,WavJourney操作无需训练音频模型或微调LLMs,优化资源利用。最后,它促进了人机在现实世界音频制作中的共同创作。
研究中选择的示例结果如下图所示。这些案例研究提供了WavJourney和最先进的生成方法之间的比较概述。

这是WavJourney的摘要,WavJourney是一种利用LLMs来创建由语言指令引导的组合音频的新颖AI框架。如果您对此感兴趣并希望了解更多信息,请随时参考下面引用的链接。





