这项AI研究介绍了Point-Bind:一种将点云与2D图像、语言、音频和视频进行对齐的3D多模态模型
This AI research introduces Point-Bind a 3D multimodal model that aligns point clouds with 2D images, language, audio, and video.


在当前的技术环境中,3D视觉因其快速增长和演化而备受关注,成为崭露头角的明星。对此兴趣的激增主要归因于对自动驾驶、增强导航系统、先进的3D场景理解以及蓬勃发展的机器人领域的高需求。为了扩展其应用场景,已经做出了许多努力,将3D点云与其他模态的数据结合起来,实现了改进的3D理解、文本到3D生成和3D问题回答。

研究人员提出了Point-Bind,这是一种革命性的3D多模态模型,旨在将点云与2D图像、语言、音频和视频等各种数据源无缝集成。在ImageBind的指导下,该模型构建了一个统一的嵌入空间,弥合了3D数据和多模态之间的差距。这一突破使得许多令人兴奋的应用成为可能,包括但不限于任意到3D生成、3D嵌入算术和全面的3D开放世界理解。
在上面的图片中,我们可以看到Point-Bind的整体流程。研究人员首先收集用于对比学习的3D-图像-音频-文本数据对,这些数据对是在ImageBind的指导下将3D模态与其他模态对齐的。通过一个共享的嵌入空间,Point-Bind可以用于3D跨模态检索、任意到3D生成、3D零样本理解以及开发3D大型语言模型Point-LLM。
Point Blind在本研究中的主要贡献包括:
- 将3D与ImageBind对齐:在一个共享嵌入空间中,Point-Bind首先将3D点云与ImageBind引导的多模态数据对齐,包括2D图像、视频、语言、音频等。
- 任意到3D生成:基于现有的文本到3D生成模型,Point-Bind能够根据任何模态条件生成3D形状,例如文本/图像/音频/点云到网格的生成。
- 3D嵌入空间算术:我们观察到Point-Bind的3D特征可以与其他模态相加,以融合它们的语义信息,实现组合的跨模态检索。
- 3D零样本理解:Point-Bind在3D零样本分类方面达到了最先进的性能。此外,我们的方法还支持基于音频的3D开放世界理解,除了文本参考之外。
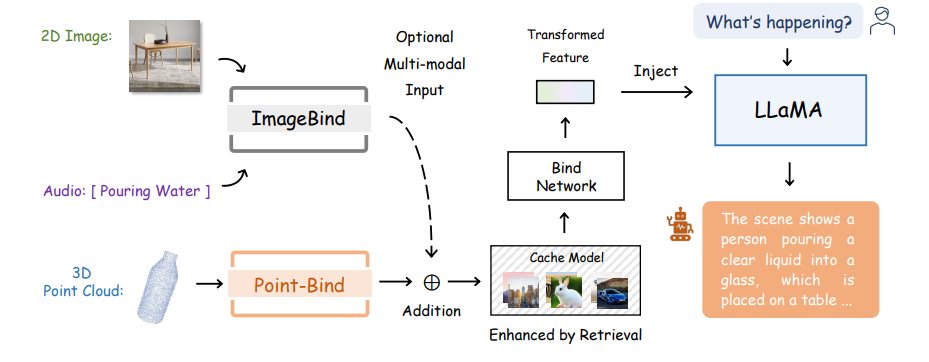
研究人员利用Point-Bind开发了3D大型语言模型(LLM),称为Point-LLM,该模型通过微调LLaMA实现了3D问题回答和多模态推理。Point-LLM的整体流程如上图所示。
Point LLM在本研究中的主要贡献包括:
- Point-LLM 用于 3D 问题回答:通过使用 PointBind,我们引入了 Point-LLM,这是第一个能够根据 3D 点云条件回应指令的 3D LLM,支持英文和中文。
- 数据和参数效率:我们仅利用公共的视觉语言数据进行调优,没有使用任何 3D 指令数据,并采用参数高效的微调技术,节省了大量资源。
- 3D 和多模态推理:通过联合嵌入空间,Point-LLM 可以通过推理 3D 和多模态输入的组合生成描述性的回应,例如点云和图像/音频。
未来的工作将专注于将多模态与更多样化的 3D 数据进行对齐,例如室内和室外场景,从而实现更广泛的应用场景。






