Transformers中的自注意力机制
Transformers的自注意力机制
自注意力机制入门指南

你是否对最近的技术(如OpenAI的ChatGPT、DALL-E、稳定扩散、Midjourney等)感到好奇?
“Transformer”是推动AI领域所有当前进展的关键驱动之一。就在几年前,AI被视为科幻,但在2022年,诸如ChatGPT和DALL-E的技术开始成为人们生活中不可或缺的一部分。这一切要归功于2017年由Google和多伦多大学发表的开创性论文“Attention Is All You Need”[1],该论文介绍了Transformer——一种严重依赖于注意力机制的深度神经网络架构。因此,了解注意力及其数学基础为AI工程师或研究人员打开了许多机会之门。
探索“注意力”的意义
让我们从“注意力”这个词的字面意义开始。根据维基百科的解释,
“它是一种有选择性地集中在信息的某个离散方面的过程。”
想象一下与朋友交谈的场景,你只关注某些词汇,而你的耳膜接收到所有的词汇。你对某些词给予更高的重视,忽略其他词汇。而这个过程是由你的潜意识自动完成的,你并不知道。这是我们人类固有的复杂认知能力。
机器学习中的注意力与此类似,只是涉及到数学。它使得AI模型能够专注于相关和重要的信息,忽略不太相关/重要的信息,有助于理解输入的上下文。
上下文理解
考虑以下句子,
句子1:“我去银行存钱。”
句子2:“河岸干燥而泥泞。”
让我们看看词汇“银行”。这个词在两个句子中的含义是不同的。请花点时间自己猜测一下含义。对于前者,你可能猜测它是某种金融机构;对于后者,如果我没记错的话,你可能猜测它是水体边界的陆地。记住,我之前已经提到过人类天生具有的天赋,我们应该为此感到自豪。
让我们分解一下,看看你是如何在潜意识中得出正确结果的。你的大脑观察到句子中的其他邻近词,并试图理解句子的上下文。在第一个句子中,你观察到了“存款”和“钱”等词汇。在第二个句子中,有“河流”、“干燥”和“泥泞”等词汇。因此,我们可以猜测,邻近词帮助你的大脑理解了“银行”这个词的上下文,一旦上下文清晰,你就猜对了。
这个实验非常重要的一点是,句子中每个词的含义取决于上下文,而上下文又取决于其他词语。因此,在ML模型处理输入时,添加上下文信息非常重要。
自注意力
将句子中的每个单词与词汇“银行”进行比较,可以为我们提供词汇“银行”的上下文信息。但事情并不总是这么简单。为了获得一句话的整体上下文信息,我们需要考虑句子中的所有词汇,而不仅仅是单个词汇“银行”。
整个句子的上下文信息取决于所有词汇的上下文信息。也就是说,对于句子中的每个词汇,我们应该尝试使用句子中的所有词汇来确定其上下文信息。这正是我们要做的事情,但是我们要使用数学来模拟人类的思维过程。这将使我们的模型能够轻松学习和理解复杂的句子。我们需要构建一种能够为我们完成这个任务的机制,然后,呀!我们将称之为自注意力。
自注意力接收表示每个单词/标记的向量作为输入。修改每个输入向量以融入上下文信息,并输出与输入相同维度的向量。
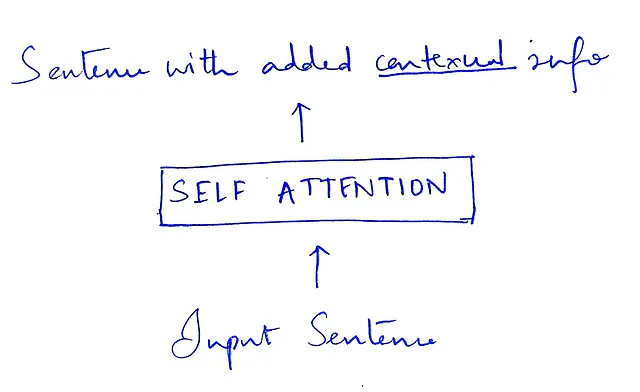
让我们更详细地了解自注意力块及其内部工作原理。
自注意力会检查句子中的每个单词,并计算它对所有其他单词的重要性。
在我们的例子中,单词“bank”对“money”和“deposit”给予了比其他单词更关注/重要性。或者我们可以说它们更相关。
然而,挑战在于确定两个单词之间的重要性/关注度/相关程度。解决方案就在我们的例子中。让我们以单词“bank”为例;对于这个词,对“money”和“deposit”的关注比其他词更高。我希望您也能观察到这些词与“bank”最相似,比其他词更相似。我们可以使用相似性评分作为关注/关注度/重要性的代理。是的,这就是论文“Attention is all you need”的作者所实现的。

但是我们如何计算两个单词之间的相似性呢?
对于我们人类来说,单词无处不在,但模型不理解单词。它们唯一操作的是向量/矩阵/张量。
因此,在将句子馈送给自注意力块之前,首先将其转换为嵌入向量。向量的维度始终固定。在嵌入向量之后,还会添加每个单词的位置信息,因为位置很重要,可以改变单词/句子的含义。这样可以让模型跟踪每个向量/单词的位置。所有这些概念超出了本文的范围。我们将只专注于自注意力。简而言之,实际的文本单词不会被输入到注意力块中;相反,会输入每个单词/标记的向量表示。
现在情况稍微简单了,因为我们得到的是向量而不是单词,而我们目前的目标是计算任意两个向量之间的相似性。
回想一下高中的线性代数。在计算两个向量之间的相似性时,我们可以使用两种指标。
i. 点积
ii. 余弦相似度
然而,点积计算速度更快且空间优化,所以我们将使用点积。但是您可以自由尝试使用余弦相似度。
点积
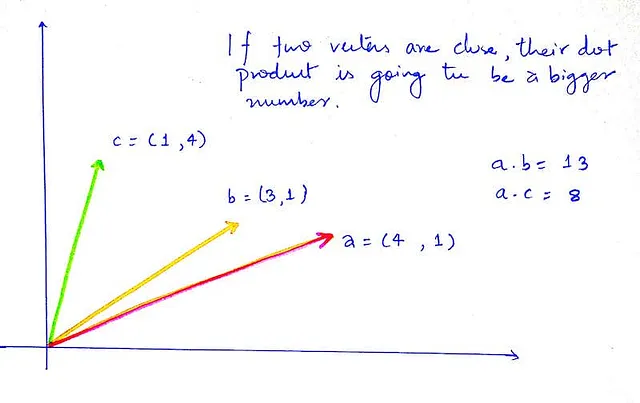

而对于相似性评分,我们希望得到一个数值,一个标量。幸运的是,点积总是给出标量结果。
让我们来看一个更简单的句子,“Hello I play games”。我们来看看如何计算相似性评分。
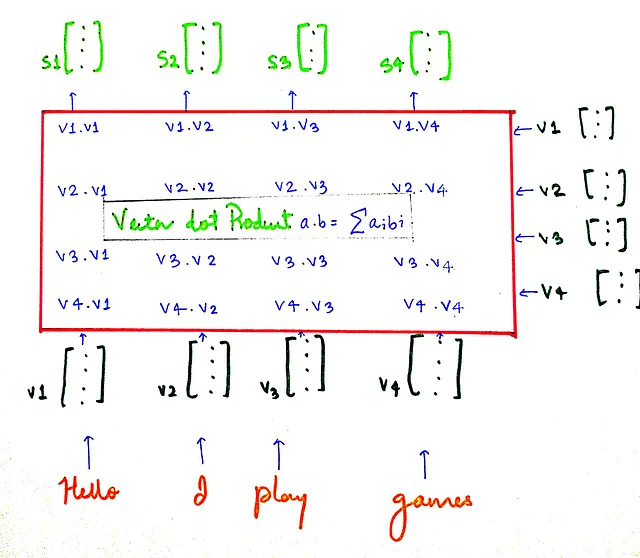
s向量是包含相似性评分的向量。
sᵢ 包含向量 vᵢ 与所有其他向量的相似性评分。例如,s₁ 包含向量 v₁ 与所有其他向量的相似性评分(在我们的例子中,v₁ 代表单词“Hello”)。现在我们有了相似性评分,让我们进行一些归一化操作,特别是缩放和 Softmax。
缩放点积
如果不进行缩放,点积的较大幅度会占主导地位,而掩盖其他部分。我们希望注意力/重要性分布更加平衡,并且对多个向量给予重要性,而不仅仅是最相似的向量。
因此,我们将结果(相似性分数)除以一个常数值,即√dₖ

使用Softmax进行标准化
通常,在深度学习中,我们使用LayerNorm/BatchNorm进行归一化,以获得更小的值,这有助于更快地收敛。在这里,我们做同样的事情,因为我们希望注意力/相似性分数的值小于1。对于每个单词,与其他所有单词的注意力分数应该总和为1。这就是softmax函数的作用。softmax函数将从点积得到的分数或logits转换为概率分布。
当一个单词对所有其他单词的注意力分数总和为1时,它也变得可解释给人类。
Softmax函数接受一个k维实数向量,并将其转换为总和为1的k维实数向量。
无论输入值如何,输出始终是介于0和1之间的实数,并且总和为1,因此它也可以解释为权重除以1。
softmax的结果是我们将获得0到1之间的分数。这被称为注意力权重。这表示一个向量/单词在1的基础上应该给其他单词多少注意力权重。(请不要被术语权重所困惑,它不是模型的参数)
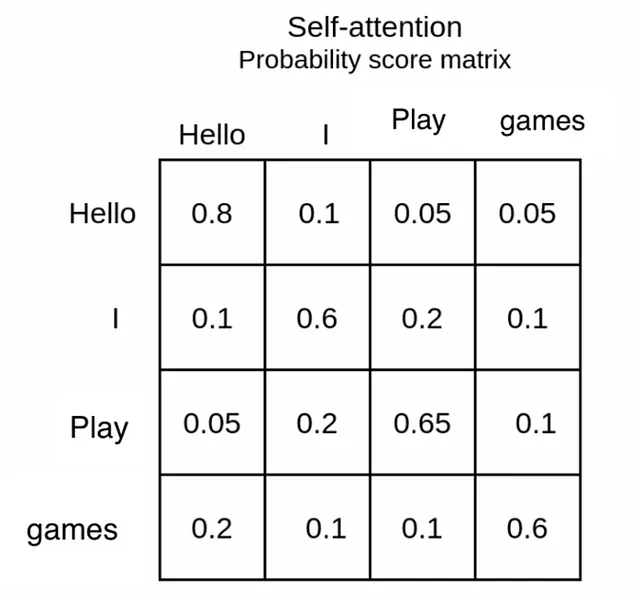
例如,以单词‘I’为例。它更关注自己,我们将忽略它(由于相似性,每个单词更关注自己),然后它给予单词‘Play’重要性。我们可以猜测这是因为单词‘I’是对问题‘谁玩游戏?’的回答。这就是softmax的结果。这些就是权重。
还记得我在自注意力的开始告诉你的‘提取上下文信息’和‘将其注入输入句子’吗?我们可以认为我们所做的就是提取上下文信息。现在让我们继续注入这些信息。
注入上下文信息
Softmax函数给我们提供了一个包含权重的注意力矩阵,现在我们知道每个单词应该给予其他单词多少注意力,为什么不突出重要的单词并抑制不太重要的单词呢?
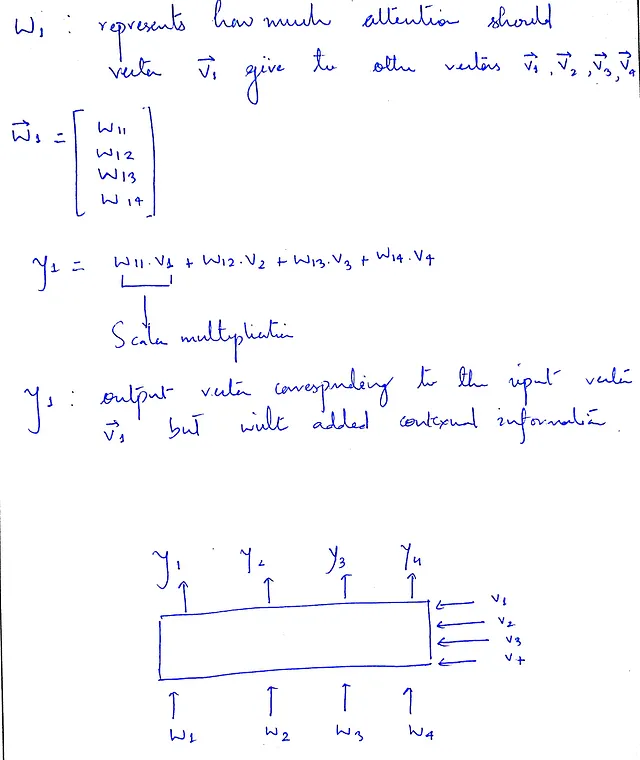
这就是我们要做的。对于每个向量vᵢ,我们将其注意力权重wᵢ与包含所有原始输入向量的矩阵V进行乘法运算。这样,重要的特征/单词将被突出显示,它们的影响将更大,而不太重要的单词将被抑制,这意味着它们对输出的影响不会那么大。
此外,对于考虑注意机制时为什么一个向量应该给予自身更大的注意力,理解其背后的原理很重要。这是因为希望保留向量自身的信息。
尽管合并上下文信息很重要,但不能忽视保留向量原始信息的重要性。
y₁的方程可以进一步阐明这个问题。
查询、键和值的概念
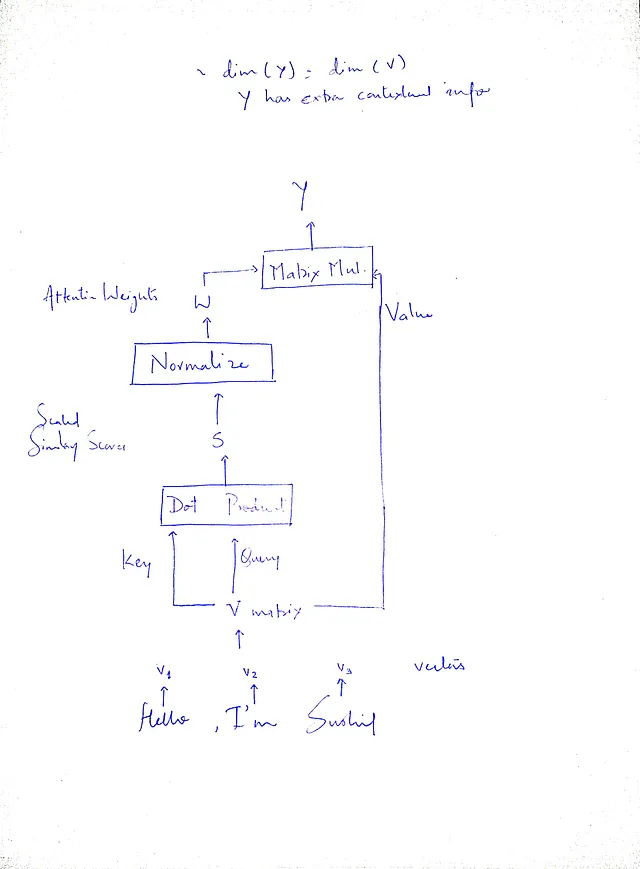
塔达,我们已成功修改了原始向量以包含上下文信息。但是看起来一切都很凌乱,不是吗?让我们让它清晰简明起来。深度学习算法通常不是在向量上进行操作,而是在张量/矩阵上进行操作。请注意,我们使用输入矩阵(V)3次,让我们给每个矩阵一个名称,这样对我们来说就很容易。第一次进行点积时,我们使用这个V矩阵两次。让我们这样说,我们向自己提出一个问题,在点积步骤中我们到底做了什么?
答案将给我们一个合适的名称。对于每个向量vᵢ,我们询问其他所有向量(v₁、v₂、v₃、v₄)的相似程度。那么为什么不给矩阵V(由v向量组成)一个名字叫做“查询(Query)”,我们用这个矩阵询问相似度得分呢?
从之前的两句话的例子中,当确定单词“bank”的上下文时,它可以被视为查询词(与查询向量相同,所有单词的查询向量的串联可以被视为查询矩阵)。而其他词如“deposits”、“money”等可以被视为关键词(构成“键矩阵”)。
为什么不将矩阵V的名称称为“键”,这样我们就可以用它来计算与查询的点积相似性呢?
最好的类比是在YouTube上搜索视频。你在搜索框中输入查询,YouTube后台尝试将您的查询与存储在YouTube数据库中的所有视频标题进行匹配。最相似/匹配的视频将首先显示。这正是我们在点积步骤中所做的。我们询问查询矩阵与键矩阵的相似程度,从而得到相似度得分矩阵。查询矩阵和键矩阵是相同的,即相等,因为它们都是输入向量的矩阵表示。
我们第三次使用矩阵V是在将上下文信息注入回输入矩阵时。我们成功提取了上下文信息,并需要突出重要信息并抑制不相关的信息。我们应该称之为“值矩阵”。当操作以矩阵形式进行时,可以使用矩阵乘法来实现这一步骤。
矩阵乘法相当于没有激活函数和偏置的线性层-因此在实现时不应该是个大问题。
值得注意的是,矩阵Q、K和V本质上是相同的,并且在值上是相等的。我们为它们分配不同的名称的唯一原因是为了表示它们在注意机制中的特定角色和目的。通过根据它们的使用提供不同的标签,我们可以有效地传达它们的预期功能,同时保持它们的相等性。我们的过程的清晰简明步骤如下:
但有一件事仍然缺少,你猜到了吗?
所有可学习参数在哪里?
请注意,没有可在反向传播期间优化的可学习参数。没有这个,我们整个系统将毫无用处,我非常怀疑我们是否可以将其称为具有可学习权重的机器学习模型。
因此,问题出现在哪里我们应该添加可学习参数?
请注意,我们所做的一切都是基于输入向量查询(Q)、键(K)和值(V)进行的计算。为什么不在使用它们之前将这些矩阵相乘,这样我们就有了我们的可学习参数,并且Q、K和V的维度仍然保持不变(如何?如果与适当形状的矩阵相乘,矩阵乘法可以保持维度完整)?
看起来我们找到了解决方案;这就是论文实现的方式。现在我们可以开始了。我们将把这些矩阵称为查询权重(Wᵩ)、键权重(Wₖ)和值权重(Wᵥ)。

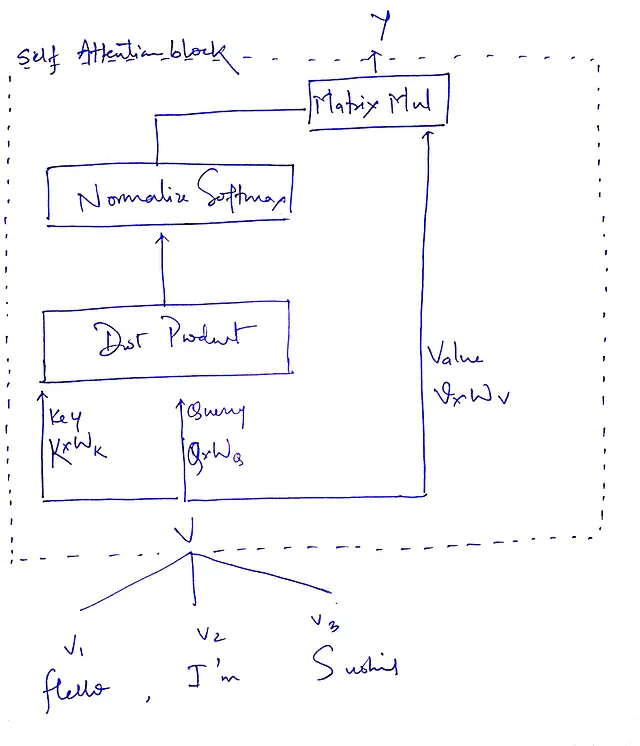
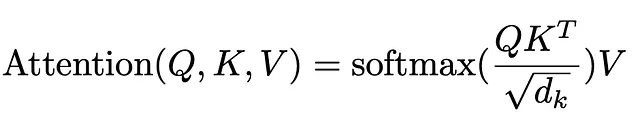
这个公式总结了我们的整个过程。首先是Q和K的点积(转置——当你深入研究/实现时,你会明白为什么要转置,这留作作业)。然后进行缩放,然后应用softmax函数来获得注意力权重,最后与原始输入向量相乘,根据从softmax获得的权重进行加权。
就是这样!
变压器无疑是自反向传播以来人工智能领域最显著的研究进展之一。每周都会有众多最先进的模型被引入,进一步增加了该领域的激动和创新。我强烈推荐阅读这篇文章[2]并在YouTube上观看这个视频[3]。这些资源可以提供有价值的见解和观点,帮助你理解这个突破性架构的复杂性和重要性。
别忘了动手实践。保持好奇心,关注我以获取更多类似内容。
参考资料
[1] Vaswani, Ashish & Shazeer, Noam & Parmar, Niki & Uszkoreit, Jakob & Jones, Llion & Gomez, Aidan & Kaiser, Lukasz & Polosukhin, Illia, “Attention is all you need”, 2017.
[2] Micheal Phi, “Illustrated Guide to transformers- Step by Step Explanation”, 博客文章, 2020.
[3] Ark, “Intuition Self-Attention Mechanism in Transformer Networks”, 2021, Youtube.






