大图像模型中的最新CNN内核
Latest CNN kernel in large-scale image models
可变形卷积网络(Deformable Convolutional Networks,DCNv2,DCNv3)中最新卷积核结构的高级概述

随着OpenAI的ChatGPT取得了显著的成功,大型语言模型的繁荣催生了人们对大型图像模型的下一个突破的预期。在这个领域,视觉模型可以被促使分析甚至生成图像和视频,类似于我们当前促使ChatGPT的方式。
大型图像模型的最新深度学习方法分为两个主要方向:基于卷积神经网络(CNNs)和基于transformers的方法。本文将重点介绍CNN方面,并对这些改进的CNN卷积核结构进行高级概述。
目录
- DCN
- DCNv2
- DCNv3
1. 可变形卷积网络(DCN)
传统上,CNN卷积核被应用于每层的固定位置,导致所有激活单元具有相同的感受野。
如下图所示,为了对输入特征图x进行卷积,每个输出位置p0的值被计算为核权重w与在x上的滑动窗口的逐元素乘法和求和结果。滑动窗口由网格R定义,也是p0的感受野。在同一层中,R的大小在所有位置保持不变。
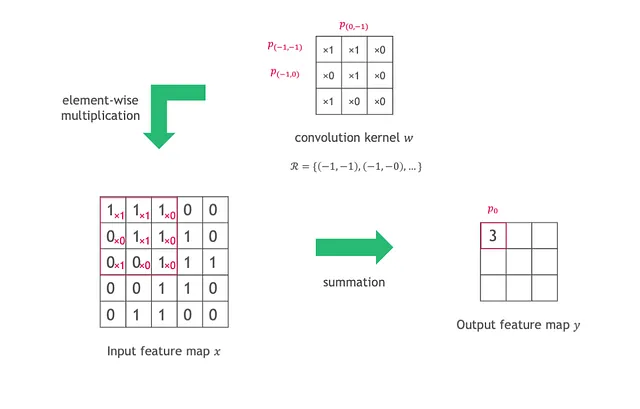
每个输出值的计算如下:
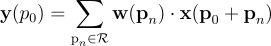
其中,pn枚举滑动窗口(网格R)中的位置。
RoI(感兴趣区域)池化操作也在每层上以固定大小的bin进行操作。对于包含nij个像素的(i,j)-th bin,其池化结果计算如下:

同样,每层中的bin的形状和大小相同。
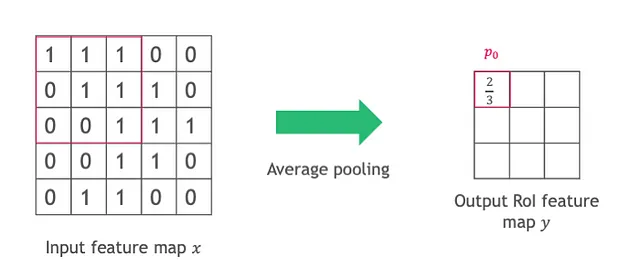
这两种操作对于编码语义的高层次层尤其存在问题,例如具有不同尺度的对象。
DCN提出了可变形卷积和可变形池化,这两种操作更灵活地模拟了这些几何结构。两者都在2D空间域上操作,即操作在通道维度上保持不变。
可变形卷积

给定输入特征图x,对于输出特征图y中的每个位置p0,DCN在枚举正则网格R中的每个位置pn时添加二维偏移量△pn。
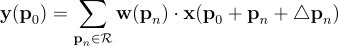
这些偏移量是通过在特征图上添加附加的卷积层获得的先前特征图来学习的。由于这些偏移量通常是分数,因此通过双线性插值来实现。
可变形区域兴趣池化
与卷积操作类似,池化偏移量△pij被添加到原始的分箱位置。
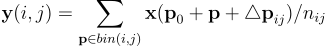
如下图所示,这些偏移量是在原始池化结果之后通过全连接(FC)层学习的。
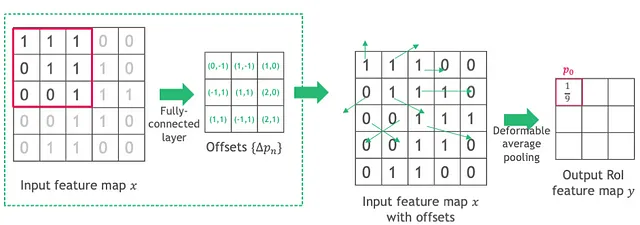
可变形位置敏感(PS)区域兴趣池化
在将可变形操作应用于PS区域兴趣池化(Dai等人,n.d.)时,如下图所示,偏移量应用于每个分数图而不是输入特征图。这些偏移量是通过卷积层而不是FC层学习的。
位置敏感区域兴趣池化(Dai等人,n.d.):传统的区域兴趣池化丢失了关于每个区域表示哪个对象部分的信息。PS区域兴趣池化通过将输入特征图转换为每个对象类别的k²个分数图来保留此信息,其中每个分数图表示特定的空间部分。因此,对于C个对象类别,总共有k²(C+1)个分数图。
2. DCNv2
尽管DCN允许更灵活地建模感受野,但它假设感受野内的像素对响应的贡献是相等的,而这通常并不是事实。为了更好地理解贡献行为,作者使用三种方法来可视化空间支持:
- 有效感受野:对每个图像像素的强度扰动,节点响应的梯度
- 有效采样/分箱位置:对采样/分箱位置的网络节点梯度
- 误差边界显著区域:逐步遮罩图像的部分,以找到产生与整个图像相同响应的最小图像区域
为了在感受野内为位置分配可学习的特征振幅,DCNv2引入了调制的可变形模块:
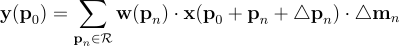
对于位置p0,偏移量△pn及其振幅△mn通过应用于相同输入特征图的单独的卷积层进行学习。
DCNv2通过为每个(i,j)-th bin添加可学习的振幅△mij来修订可变形RoI池化。

DCNv2还扩展了可变形卷积层的使用,以替换ResNet-50中的conv3到conv5阶段的常规卷积层。
3. DCNv3
为了减少DCNv2的参数大小和内存复杂度,DCNv3对内核结构进行了以下调整。
- 受深度可分离卷积(Chollet, 2017)的启发
深度可分离卷积将传统卷积分解为:1. 深度卷积:输入特征的每个通道分别与一个滤波器进行卷积;2. 点卷积:在通道之间应用1×1卷积。
作者建议将特征振幅m作为深度部分,将在网格中的位置共享的投影权重w作为点部分。
2. 受组卷积(Krizhevsky, Sutskever and Hinton, 2012)的启发
组卷积:将输入通道和输出通道分成组,并对每个组应用单独的卷积。
DCNv3(Wang et al., 2023)建议将卷积分成G组,每组都有单独的偏移量△pgn和特征振幅△mgn。
因此,DCNv3的公式为:
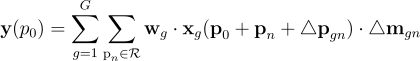
其中G是卷积组的总数,wg与位置无关,△mgn通过softmax函数进行归一化,使得在网格R上的总和为1。
性能
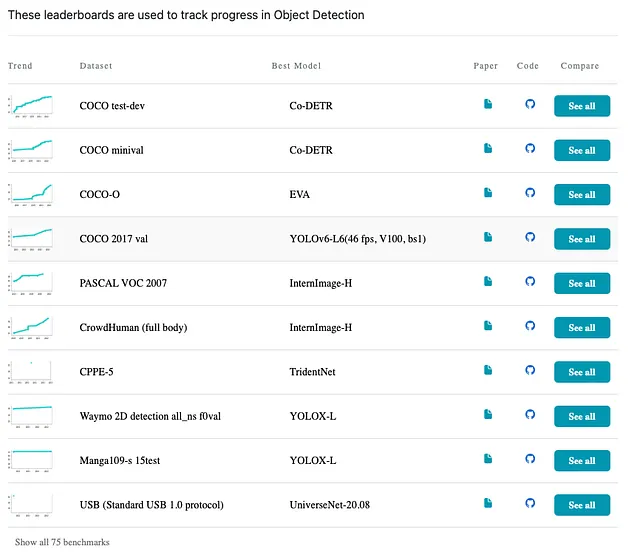
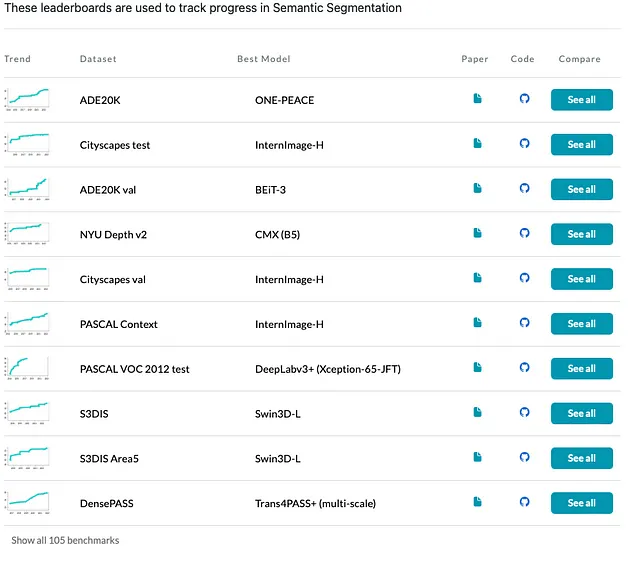
到目前为止,基于DCNv3的InternImage在多个下游任务(如检测和分割)中展示了优越的性能,如下表所示,以及paperswithcode上的排行榜。更详细的比较请参考原始论文。

摘要
在本文中,我们回顾了常规卷积网络的内核结构,以及它们的最新改进,包括可变形卷积网络(DCN)和两个更新的版本:DCNv2和DCNv3。我们讨论了传统结构的局限性,并突出了基于先前版本进行创新的进展。要更深入地了解这些模型,请参考参考文献部分的论文。
致谢
特别感谢Kenneth Leung,他激发了我创作这篇文章并分享了令人惊叹的想法。非常感谢Kenneth、Melissa Han和Annie Liao对改进这篇文章的贡献。你们的深思熟虑的建议和建设性的反馈对内容的质量和深度产生了重大影响。
参考文献
Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H.和Wei, Y.(无日期)。Deformable Convolutional Networks. [在线] 可获取:https://arxiv.org/pdf/1703.06211v3.pdf。
Zhu, X., Hu, H., Lin, S.和Dai, J.(无日期)。Deformable ConvNets v2:更可变形,更好的结果。[在线] 可获取:https://arxiv.org/pdf/1811.11168.pdf。
Wang, W., Dai, J., Chen, Z., Huang, Z., Li, Z., Zhu, X., Hu, X., Lu, T., Lu, L., Li, H., Wang, X.和Qiao, Y.(无日期)。InternImage:通过可变形卷积探索大规模视觉基础模型。[在线] 可获取:https://arxiv.org/pdf/2211.05778.pdf [访问日期:2023年7月31日]。
Chollet, F.(无日期)。Xception:深度学习与深度可分离卷积。[在线] 可获取:https://arxiv.org/pdf/1610.02357.pdf。
Krizhevsky, A., Sutskever, I.和Hinton, G.E.(2012)。使用深度卷积神经网络的ImageNet分类。ACM通信,60(6),pp.84–90。doi:https://doi.org/10.1145/3065386。
Dai, J., Li, Y., He, K.和Sun, J.(无日期)。R-FCN:基于区域的全卷积网络的对象检测。[在线] 可获取:https://arxiv.org/pdf/1605.06409v2.pdf。





