使用推断终端快速部署MusicGen
使用推断终端快速部署MusicGen' can be condensed to '快速部署MusicGen推断终端
MusicGen是一个强大的音乐生成模型,它通过输入文本提示和可选旋律来输出音乐。本博客文章将指导您如何使用推理端点生成音乐。
推理端点允许我们编写自定义的推理函数,称为自定义处理程序。当一个模型不被transformers高级抽象pipeline直接支持时,这些处理程序尤其有用。
transformers管道提供了强大的抽象,可以运行基于transformers的模型的推理。推理端点利用管道API轻松部署模型,只需几次点击即可。然而,推理端点也可以用于部署没有管道的模型,甚至是非transformer模型!这是通过使用我们称为自定义处理程序的自定义推理函数来实现的。
让我们以MusicGen为例演示此过程。要为MusicGen实现一个自定义处理程序并部署它,我们需要:
- 复制我们想要提供的MusicGen存储库,
- 在复制的存储库中的
handler.py和requirements.txt中编写自定义处理程序和任何依赖项, - 为该存储库创建推理端点。
或者只需使用最终结果并部署我们的自定义MusicGen模型存储库,即刚刚按照上述步骤进行操作 🙂
让我们开始吧!
首先,我们将使用存储库复制器将facebook/musicgen-large存储库复制到我们自己的个人资料中。
然后,我们将handler.py和requirements.txt添加到复制的存储库中。首先,让我们看一下如何使用MusicGen进行推理。
from transformers import AutoProcessor, MusicgenForConditionalGeneration
processor = AutoProcessor.from_pretrained("facebook/musicgen-large")
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-large")
inputs = processor(
text=["80s pop track with bassy drums and synth"],
padding=True,
return_tensors="pt",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)让我们来听听它的声音:
您的浏览器不支持音频元素。
可选地,您还可以使用音频片段对输出进行条件限定,即生成一个结合了生成的文本音频和输入音频的补充片段。
from transformers import AutoProcessor, MusicgenForConditionalGeneration
from datasets import load_dataset
processor = AutoProcessor.from_pretrained("facebook/musicgen-large")
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-large")
dataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
sample = next(iter(dataset))["audio"]
# 取音频样本的前半部分
sample["array"] = sample["array"][: len(sample["array"]) // 2]
inputs = processor(
audio=sample["array"],
sampling_rate=sample["sampling_rate"],
text=["80s blues track with groovy saxophone"],
padding=True,
return_tensors="pt",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)让我们来听听它的声音:
您的浏览器不支持音频元素。
在这两种情况下,model.generate方法会生成音频,并遵循与文本生成相同的原则。您可以在我们的生成博客文章中了解更多信息。
好了!通过上面概述的基本用法,让我们为了好玩和利润部署MusicGen!
首先,在handler.py中定义一个自定义处理程序。我们可以使用推理端点模板,并覆盖__init__和__call__方法以添加我们自定义的推理代码。__init__将初始化模型和处理器,__call__将接收数据并返回生成的音乐。下面是修改后的EndpointHandler类的代码。👇
from typing import Dict, List, Any
from transformers import AutoProcessor, MusicgenForConditionalGeneration
import torch
class EndpointHandler:
def __init__(self, path=""):
# 从路径加载模型和处理器
self.processor = AutoProcessor.from_pretrained(path)
self.model = MusicgenForConditionalGeneration.from_pretrained(path, torch_dtype=torch.float16).to("cuda")
def __call__(self, data: Dict[str, Any]) -> Dict[str, str]:
"""
Args:
data (:dict:):
包含文本提示和生成参数的载荷。
"""
# 处理输入
inputs = data.pop("inputs", data)
parameters = data.pop("parameters", None)
# 预处理
inputs = self.processor(
text=[inputs],
padding=True,
return_tensors="pt",).to("cuda")
# 将所有kwargs与输入一起传递给模型
if parameters is not None:
with torch.autocast("cuda"):
outputs = self.model.generate(**inputs, **parameters)
else:
with torch.autocast("cuda"):
outputs = self.model.generate(**inputs,)
# 后处理预测结果
prediction = outputs[0].cpu().numpy().tolist()
return [{"generated_audio": prediction}]为了保持简单,在这个示例中我们只是从文本生成音频,而不是用旋律来进行控制。接下来,我们将创建一个包含所有依赖项的requirements.txt文件,以便运行推断代码:
transformers==4.31.0
accelerate>=0.20.3将这两个文件上传到我们的仓库中就足以提供模型服务。
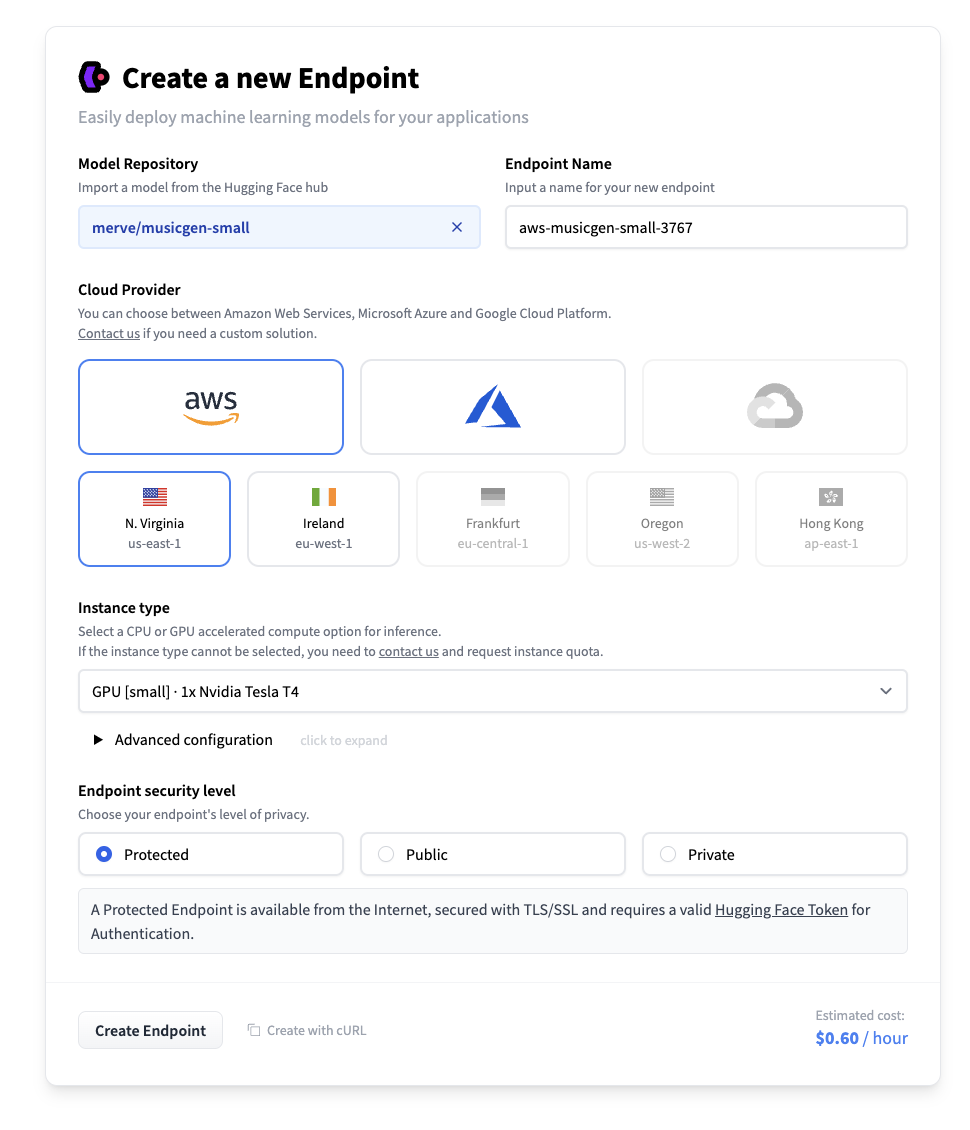
现在我们可以创建推断端点了。转到推断端点页面,点击部署第一个模型。在“模型仓库”字段中,输入您复制的仓库的标识符。然后选择您想要的硬件,并创建端点。任何至少具有16 GB RAM的实例都可以用于musicgen-large。
创建端点后,它将自动启动并准备好接收请求。
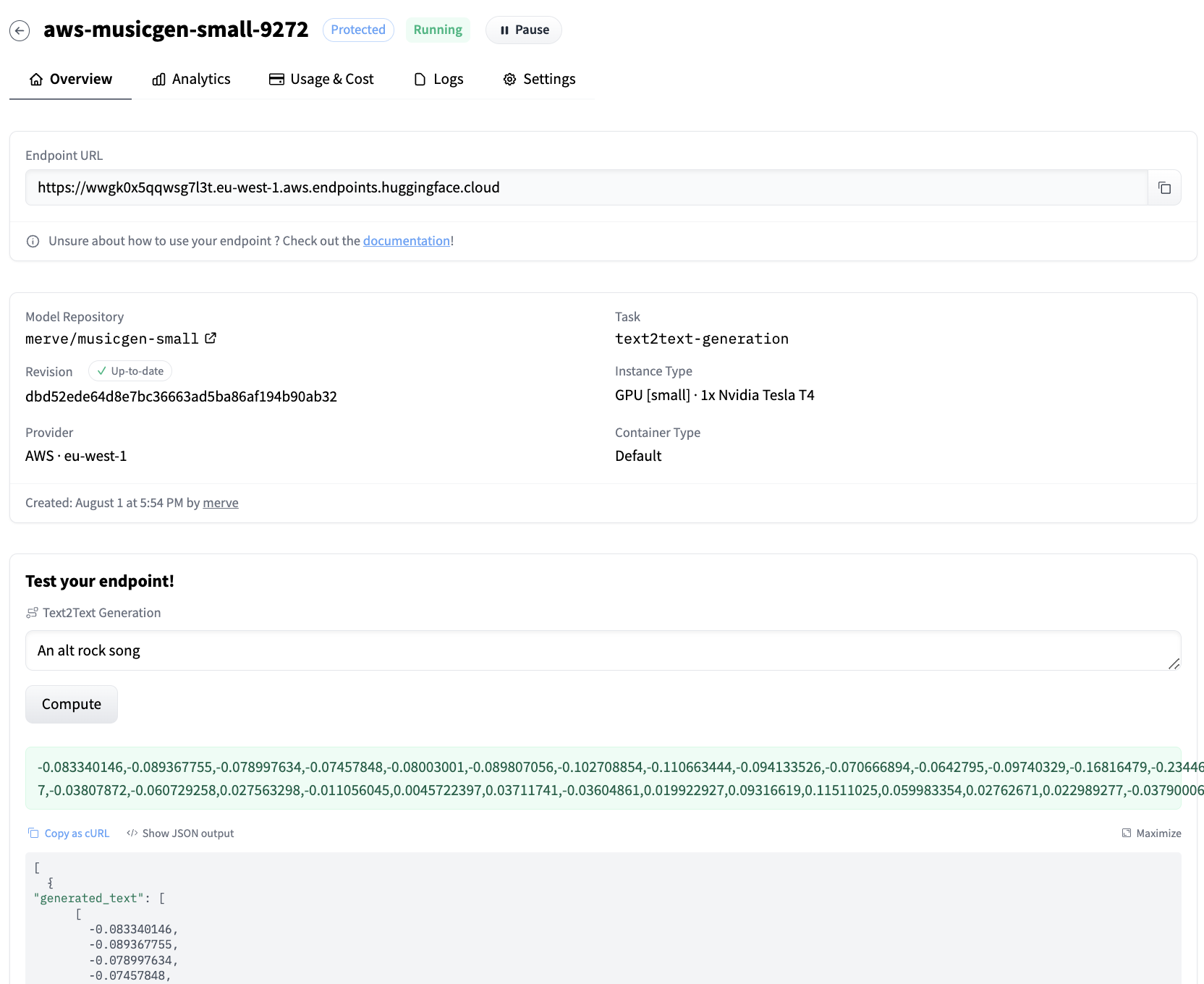
我们可以使用下面的代码片段查询端点。
curl URL_OF_ENDPOINT \
-X POST \
-d '{"inputs":"happy folk song, cheerful and lively"}' \
-H "Authorization: {YOUR_TOKEN_HERE}" \
-H "Content-Type: application/json"我们可以看到以下波形序列作为输出。
[{"generated_audio":[[-0.024490159,-0.03154691,-0.0079551935,-0.003828604, ...]]}]以下是它的声音。
您的浏览器不支持音频元素。
您还可以使用huggingface-hub Python库的InferenceClient类来访问端点。
from huggingface_hub import InferenceClient
client = InferenceClient(model = URL_OF_ENDPOINT)
response = client.post(json={"inputs":"an alt rock song"})
# response looks like this b'[{"generated_text":[[-0.182352,-0.17802449, ...]]}]
output = eval(response)[0]["generated_audio"]您可以以任何您想要的方式将生成的序列转换为音频。您可以使用Python中的scipy将其写入.wav文件中。
import scipy
import numpy as np
# output is [[-0.182352,-0.17802449, ...]]
scipy.io.wavfile.write("musicgen_out.wav", rate=32000, data=np.array(output[0]))完成!
请使用下面的演示来尝试端点。
结论
在本篇博文中,我们展示了如何使用自定义推断处理程序部署MusicGen。相同的技术也可以用于Hub中没有相关管道的任何其他模型。您只需要在handler.py中覆盖Endpoint Handler类,并添加requirements.txt以反映您项目的依赖关系。
了解更多
- 推断端点文档,包括自定义处理程序






