遇见ToolLLM:一种数据构建和模型训练的通用工具使用框架,增强了大型语言模型的API使用
ToolLLM是一种通用工具框架,用于数据构建和模型训练,可增强大型语言模型的API使用


为了高效地连接众多工具(API)并完成困难的任务,工具学习试图利用大型语言模型(LLMs)的潜力。通过与API连接,LLMs可以显着增加其价值,并获得作为消费者与庞大应用生态系统之间有效中间人的能力。尽管指令调整使得开源LLMs(如LLaMA和Vicuna)能够开发各种能力,但它们仍然需要处理高级任务,如理解用户指令和有效地与工具(API)进行交互。这是因为目前的指令调整主要集中在简单的语言任务(如随意聊天)而非工具使用领域。
另一方面,现代最先进的LLMs(如GPT-4)在工具使用方面显示出出色的能力,但是它们是闭源的,其内部工作原理是不透明的。由于这个原因,社区驱动的创新和开发以及AI技术的民主化受到了限制。因此,让开源LLMs能够熟练理解各种API是至关重要的。尽管早期的研究已经尝试创建用于工具使用的指令调整数据,但它们的固有限制阻碍了在LLMs中完全激发工具使用能力。其中包括:(1)受限的API:它们要么忽略了真实世界的API(如RESTAPI),要么只考虑了一小部分具有不足多样性的API;(2)受限的场景:现有的工作局限于仅使用一个单一工具的指令。相比之下,在真实世界的环境中,可能需要结合多个工具进行多轮工具执行以完成一个具有挑战性的任务。
此外,他们经常假设用户会预先确定某个命令的最佳API集,然而当提供了大量API时,这是不可能的;(3)低劣的规划和推理:现有的研究使用简单的提示机制进行模型推理(如思路链或ReACT),这无法完全引发LLMs中编码的能力,因此无法处理复杂的指令。对于开源LLMs来说,这个问题尤为严重,因为它们的推理能力远远不如最先进的LLMs。此外,一些工作甚至不使用API获取真实的回复,而这对于后续模型的发展来说是至关重要的。他们提出了ToolLLM,一个通用的工具使用框架,用于数据生成、模型训练和评估,以激发开源LLMs内部的工具使用能力。
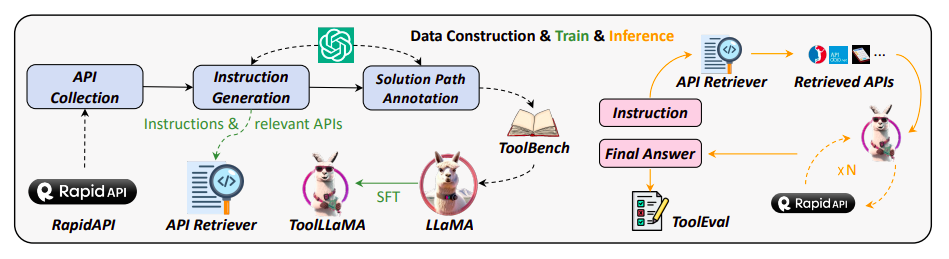
API检索器在指令推理过程中向ToolLLaMA建议相关的API,而ToolLLaMA则进行多次API调用以得出最终结果。ToolEval评估整个辩论过程。
他们首先收集了一个高质量的指令调整数据集,称为ToolBench,如图1所示。最新的ChatGPT(gpt-3.5-turbo-16k),已经更新了改进的函数调用能力,用于自动生成该数据集。表1提供了ToolBench和早期工作之间的比较。具体而言,创建ToolBench分为三个阶段:
• API收集:他们从RapidAPI2收集了16,464个REST(表现层状态转移)API。这个平台上有大量由开发人员提供的真实世界API。这些API涵盖了49个不同的领域,包括电子商务、社交网络和天气等。他们从RapidAPI上获取每个API的全面的API文档,包括功能摘要、必需的输入、API调用的代码示例等。为了使模型能够泛化到在训练过程中未遇到的API,他们期望LLMs通过理解这些文档来学会使用API。
• 指令生成:他们首先从整个API集合中选择几个API,然后要求ChatGPT为这些API开发各种指令。他们选择涵盖单工具和多工具场景的指令,以涵盖真实世界的情况。这确保了他们的模型学习如何单独处理各种工具以及如何将它们组合起来完成具有挑战性的任务。
• 解决方案路径注释:他们突出显示对这些指令的优秀回答。每个回答可能涉及多次模型推理和实时API请求的迭代,以达到最终结论。即使最先进的LLM(例如GPT-4),由于工具学习的固有困难,复杂命令的成功率也很低,使得数据收集无效。为了解决这个问题,他们创建了一种基于深度优先搜索的决策树(DFSDT),以提高LLMs的规划和推理能力。相比之下,与传统的思维链(CoT)和ReACT相比,DFSDT使LLMs能够评估各种推理,并决定是回溯还是继续沿着正确的路径。在研究中,DFSDT有效地完成了那些无法使用CoT或ReACT回答的困难指令,并大大提高了注释效率。
清华大学、模特最佳公司、中国人民大学、耶鲁大学、微信AI、腾讯公司和知乎公司的研究人员创建了一个名为ToolEval的自动评估器,该评估器由ChatGPT支持,用于评估LLMs的工具使用能力。它包括两个关键指标:(1)胜率,对比两种可能的解决方案方法的价值和效用;(2)通过率,评估在受限资源内成功执行指令的能力。他们表明,ToolEval与人工评估密切相关,并提供了准确、可扩展和一致的工具学习评估。他们通过优化LLaMA在ToolBench上获得了ToolLLaMA。
在使用他们的ToolEval进行分析后,他们得出以下结论:
• ToolLLaMA处理简单单工具和复杂多工具指令的能力很强。只需要API文档即可让ToolLLaMA成功地推广到新的API,这使其在该领域中独一无二。这种适应性使用户能够顺利地整合新的API,提高模型在实际应用中的实用性。尽管仅优化了12k+个实例,ToolLLaMA在工具使用方面的表现与“教师模型”ChatGPT相当。
• 他们展示了他们的DFSDT如何作为一种广泛的决策方法来提高LLMs的推理能力。
DFSDT通过考虑各种推理轨迹来扩展搜索空间,优于ReACT。此外,他们要求ChatGPT为每个指令提供相关的API建议,然后使用这些数据训练一个神经API检索器。在实践中,这个解决方案消除了从大量API池中手动选择的要求。他们可以有效地集成ToolLLaMA和API检索器。如图1所示,API检索器对于每个指令提供一系列相关的API建议,然后将其转发给ToolLLaMA进行多轮决策,以确定最终答案。他们证明了检索器显示出惊人的检索精度,通过在大量的API中进行排序,返回与实际数据密切匹配的API。总之,本研究旨在使开源LLMs能够在实际情况中使用各种API执行复杂命令。他们期待这项工作将进一步研究工具使用与指令调整之间的关系。他们还在GitHub页面上提供了演示和源代码。