通过尺度解锁高准确性差分隐私图像分类
Scaling for highly accurate differentially private image classification.
一篇关于语言模型的伦理和社会风险的最新DeepMind论文指出,大型语言模型泄露其训练数据中的敏感信息是这些模型相关组织有责任解决的潜在风险。另一篇最新论文表明,标准图像分类模型中也可能出现类似的隐私风险:每个单独的训练图像的指纹可以在模型参数中找到,并且恶意方可能利用这些指纹从模型中重构训练数据。
隐私增强技术如差分隐私(DP)可以在训练时部署以减轻这些风险,但它们往往会导致模型性能显著降低。在这项工作中,我们在差分隐私下实现了高准确性的图像分类模型训练,取得了重大进展。
![图1:(左)GPT-2中的训练数据泄露示意图[来源:Carlini等人的"从大型语言模型中提取训练数据",2021年]。(右)从100K参数卷积神经网络中重构的CIFAR-10训练示例[来源:Balle等人的"利用知情对手重构训练数据",2022年]](https://assets-global.website-files.com/621e749a546b7592125f38ed/62ab43e65845e64d1a827c87_Figure.png)
差分隐私被提出作为一个数学框架,以捕捉在统计数据分析过程中(包括机器学习模型的训练)保护个体记录的要求。DP算法通过在计算所需的统计量或模型时注入精心校准的噪声,保护个体免受任何关于使其独特的特征的推断(包括完全或部分重构)的影响。使用DP算法在理论和实践中都提供了强大而严格的隐私保证,已成为许多公共和私人组织的事实标准。
深度学习中最流行的差分隐私算法是差分隐私随机梯度下降(DP-SGD),这是标准SGD的修改版本,通过剪辑个别示例的梯度并添加足够的噪声来掩盖任何个体对每个模型更新的贡献:
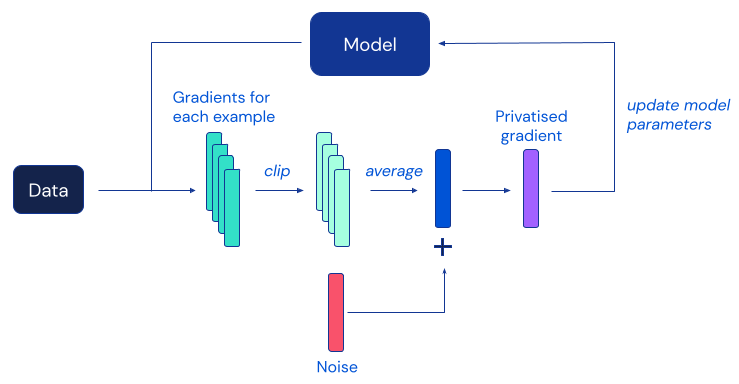
不幸的是,先前的研究发现,在实践中,DP-SGD提供的隐私保护往往以显著较低的准确性为代价,这对差分隐私在机器学习社区的广泛采用构成了重大障碍。根据先前工作的经验证据,DP-SGD在更大的神经网络模型上的效用退化更为严重,包括那些常用于在具有挑战性的图像分类基准上获得最佳性能的模型。
我们的工作研究了这一现象,并对训练过程和模型架构进行了一系列简单的修改,显著提高了在标准图像分类基准上进行DP训练的准确性。我们研究中最引人注目的观察结果是,只要确保模型的梯度表现良好,DP-SGD可以用于高效地训练比以前认为的要深得多的模型。我们相信我们的研究所取得的性能大幅提升有潜力解锁具有正式隐私保证的图像分类模型的实际应用。
下图总结了我们的两个主要结果:在没有额外数据的情况下进行私有训练时,与先前的工作相比,CIFAR-10的改进约为10%,并且在ImageNet上进行预训练模型的私有微调时,Top-1准确率达到86.7%,几乎达到了最佳非私有性能。

这些结果是在𝜺=8的情况下实现的,这是用于校准差分隐私在机器学习应用中提供保护强度的标准设置。我们在论文中讨论了这个参数,以及在其他𝜺值和其他数据集上的额外实验结果。除了论文外,我们还公开了我们的实现,以便其他研究人员验证我们的发现并在此基础上进行进一步研究。我们希望这一贡献能帮助其他对实际差分隐私训练感兴趣的人。
在GitHub上下载我们的JAX实现。






