掌握Stratego,这款经典的不完全信息游戏
Master Stratego, the classic game of incomplete information.
DeepNash通过结合博弈论和无模型深度强化学习,从零开始学会玩Stratego
游戏人工智能(AI)系统已经进入了一个新的领域。Stratego这个比国际象棋和围棋更复杂、比扑克更狡猾的经典棋盘游戏现在已经被掌握了。在《科学》杂志上发表的论文中,我们介绍了DeepNash,一种AI代理,通过与自己对战从零开始学习该游戏,达到了人类专家水平。
DeepNash使用一种新颖的方法,基于博弈论和无模型深度强化学习。它的游戏风格收敛到纳什均衡,这意味着对手很难利用它的游戏方式。事实上,DeepNash在全球最大的在线Stratego平台Gravon上已经达到了有史以来排名前三的水平。
棋盘游戏在人工智能领域一直是进展的一个标志,它们让我们能够研究人类和机器在受控环境中如何制定和执行策略。与国际象棋和围棋不同,Stratego是一种不完全信息的游戏:玩家无法直接观察对手棋子的身份。
这种复杂性意味着其他基于AI的Stratego系统很难达到业余水平。这也意味着一种非常成功的AI技术,称为“博弈树搜索”,之前用于掌握许多完全信息的游戏,在Stratego中不够可扩展。因此,DeepNash完全超越了博弈树搜索。
掌握Stratego的价值超越了游戏本身。为了实现我们解决智能、推动科学和造福人类的使命,我们需要构建先进的AI系统,可以在复杂的现实情况下运行,并且只有有限的其他代理和人的信息。我们的论文展示了DeepNash如何应用于不确定性情况,并成功地平衡结果,帮助解决复杂问题。
了解Stratego
Stratego是一个回合制的夺旗游戏。这是一个关于虚张声势和策略、信息收集和巧妙操作的游戏。而且它是一个零和游戏,所以一方的任何收益都代表着对手同等大小的损失。
Stratego对AI来说具有挑战性,部分原因是它是一个不完全信息的游戏。双方玩家都开始时可以自由地将自己的40个棋子排列在起始阵型中,初始时对方是看不到的。由于双方玩家没有相同的知识,他们在做出决策时需要平衡所有可能的结果,这为研究战略互动提供了一个具有挑战性的基准。下面是各种棋子及其排名的信息。

在Stratego中,信息很难获得。对手的棋子身份通常只有在它们在战场上相遇时才被揭示出来。这与国际象棋或围棋等完全信息游戏形成鲜明对比,因为双方玩家都知道每个棋子的位置和身份。
在完全信息游戏上表现出色的机器学习方法,例如DeepMind的AlphaZero,并不容易转移到Stratego上。在做出带有不完全信息的决策并进行虚张声势的潜力时,Stratego更类似德州扑克,并且需要一种人类般的能力,正如美国作家杰克·伦敦曾经指出的那样:“生活并不总是拿到好牌,而有时候是把糟糕的牌打好。”
像德克萨斯扑克等游戏中表现出色的AI技术在战略游戏中并不适用,因为这种游戏通常需要进行数百次的移动才能决出胜负。在战略游戏中,推理必须在大量的连续动作中进行,而每个动作对最终结果的贡献并不明显。
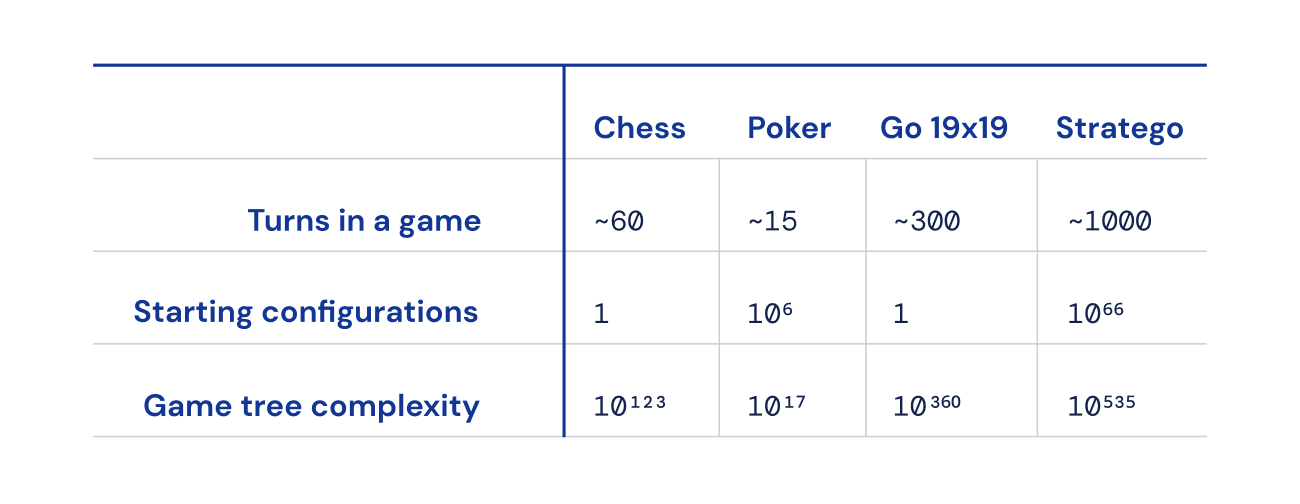
最后,与国际象棋、围棋和扑克相比,可能的游戏状态数量(表示为“游戏树复杂度”)超出了常规范围,因此解决起来非常困难。这就是我们对战略游戏的兴趣所在,也是它成为AI社区几十年来的挑战的原因。
寻找平衡点
DeepNash采用了一种基于博弈论和无模型深度强化学习的新方法。 “无模型” 意味着DeepNash在游戏过程中并不试图明确建模对手的私有游戏状态。特别是在游戏的早期阶段,当DeepNash对对手的棋子了解甚少时,这种建模将是无效的,如果不是不可能的。
由于战略游戏的游戏树复杂度非常庞大,DeepNash无法采用基于AI的游戏的坚定方法-蒙特卡洛树搜索。树搜索是许多在较简单的棋盘游戏和扑克中取得了重大突破的关键因素。
相反,DeepNash采用了一种新的博弈论算法思想,我们称之为规范纳什动力学(R-NaD)。R-NaD在无与伦比的规模下工作,将DeepNash的学习行为引导到所谓的纳什均衡(详细技术细节请参阅我们的论文)。
导致纳什均衡的游戏行为在长期内是无法被利用的。如果一个人或机器能够完美地进行无法被利用的战略游戏,他们所能达到的最差胜率将是50%,而且只有在面对同样完美的对手时才能实现。
在与最佳战略游戏机器人(包括多个计算机战略游戏世界锦标赛冠军)的比赛中,DeepNash的获胜率达到了97%以上,经常达到100%。在Gravon游戏平台上与顶级专家级人类玩家的比赛中,DeepNash的获胜率为84%,获得了历史上排名前三的成绩。
料想不到
为了实现这些结果,DeepNash在初始部署阶段和游戏阶段都展现出了一些非凡的行为。为了不易被利用,DeepNash采用了一种不可预测的策略。这意味着在一系列游戏中,DeepNash的初始部署变化足够大,以防止对手发现模式。而在游戏阶段,DeepNash在看似等效的动作之间进行随机选择,以防止被利用的倾向。
战略游戏玩家力求不可预测,因此保持信息隐藏是有价值的。DeepNash以相当引人注目的方式展示了它如何评估信息的价值。在下面的示例中,与人类玩家对战时,DeepNash(蓝色)在游戏早期阶段牺牲了一些棋子,包括7(少将)和8(上校),结果能够找到对手的10(元帅)、9(将军)、8和两个7。
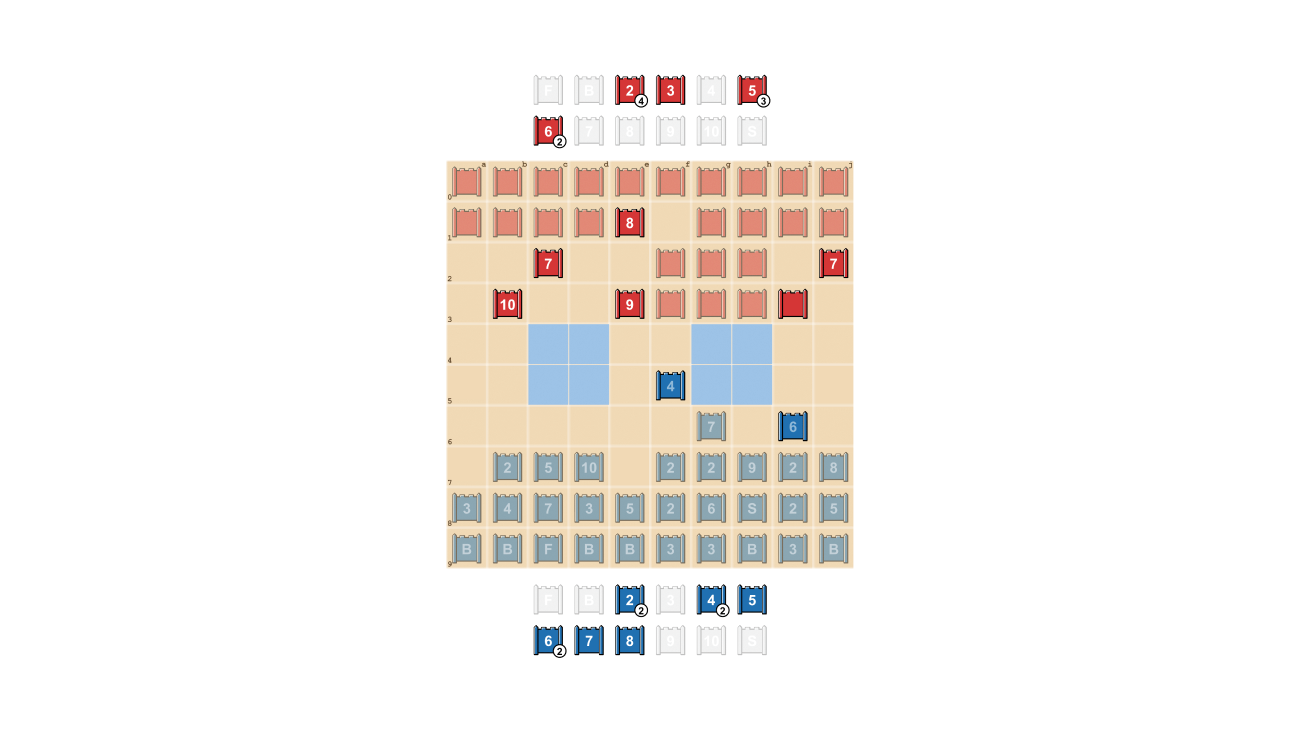
这些努力使DeepNash处于显著的物质劣势;在它的对手保存了所有排名在7及以上的棋子的同时,它失去了一个7和一个8。尽管如此,由于对对手高层的可靠情报,DeepNash评估了自己的获胜机会为70% – 并且获胜了。
虚张声势的艺术
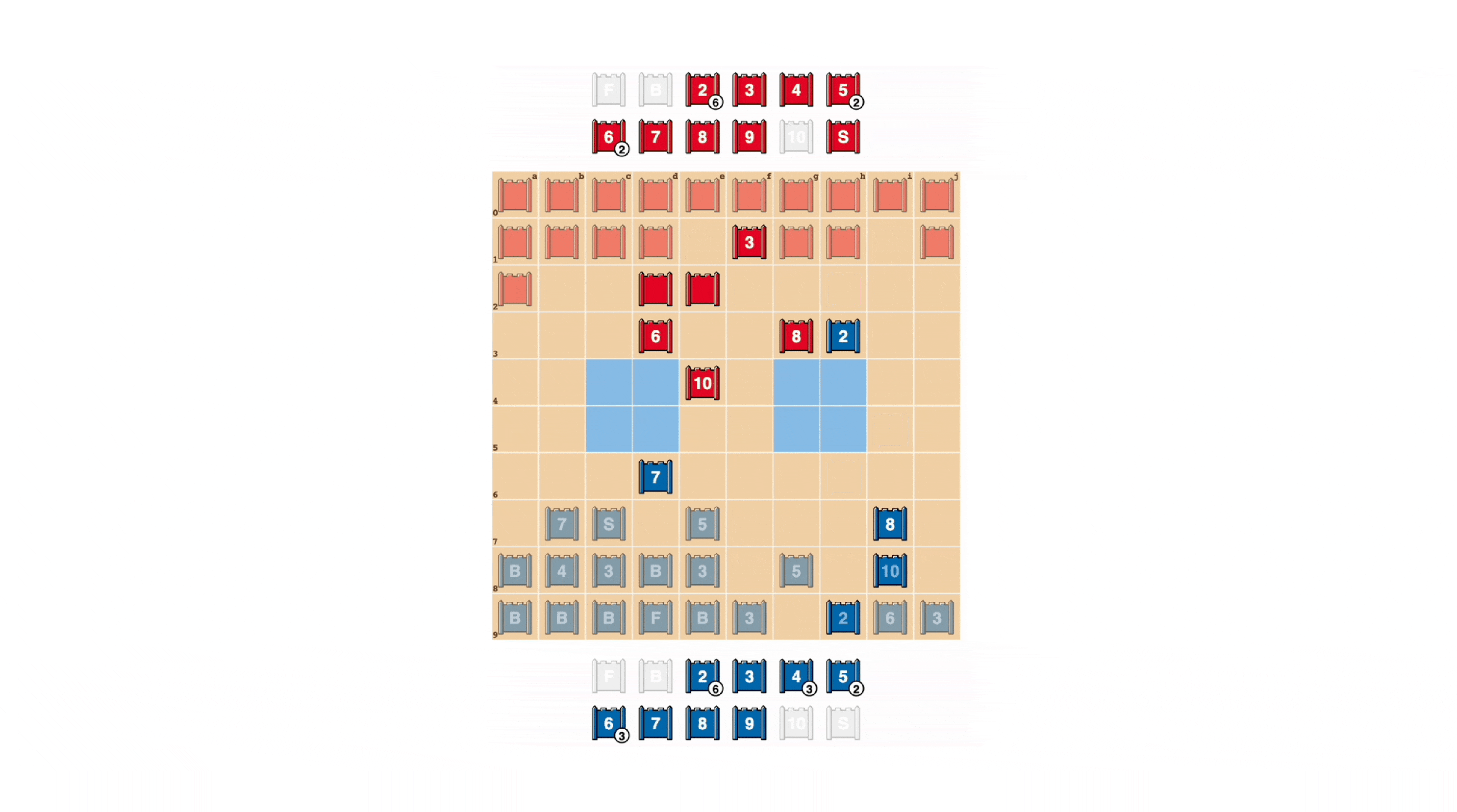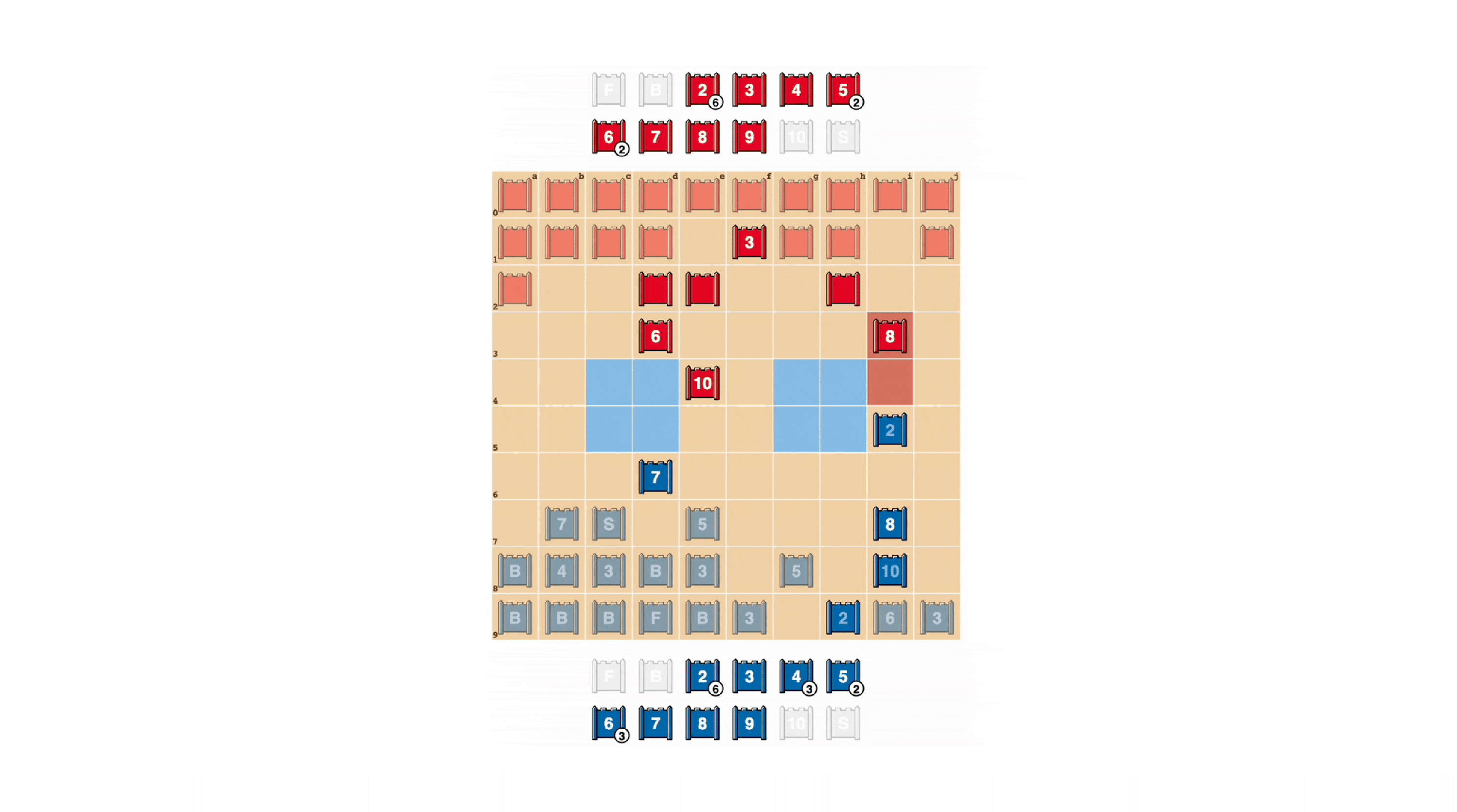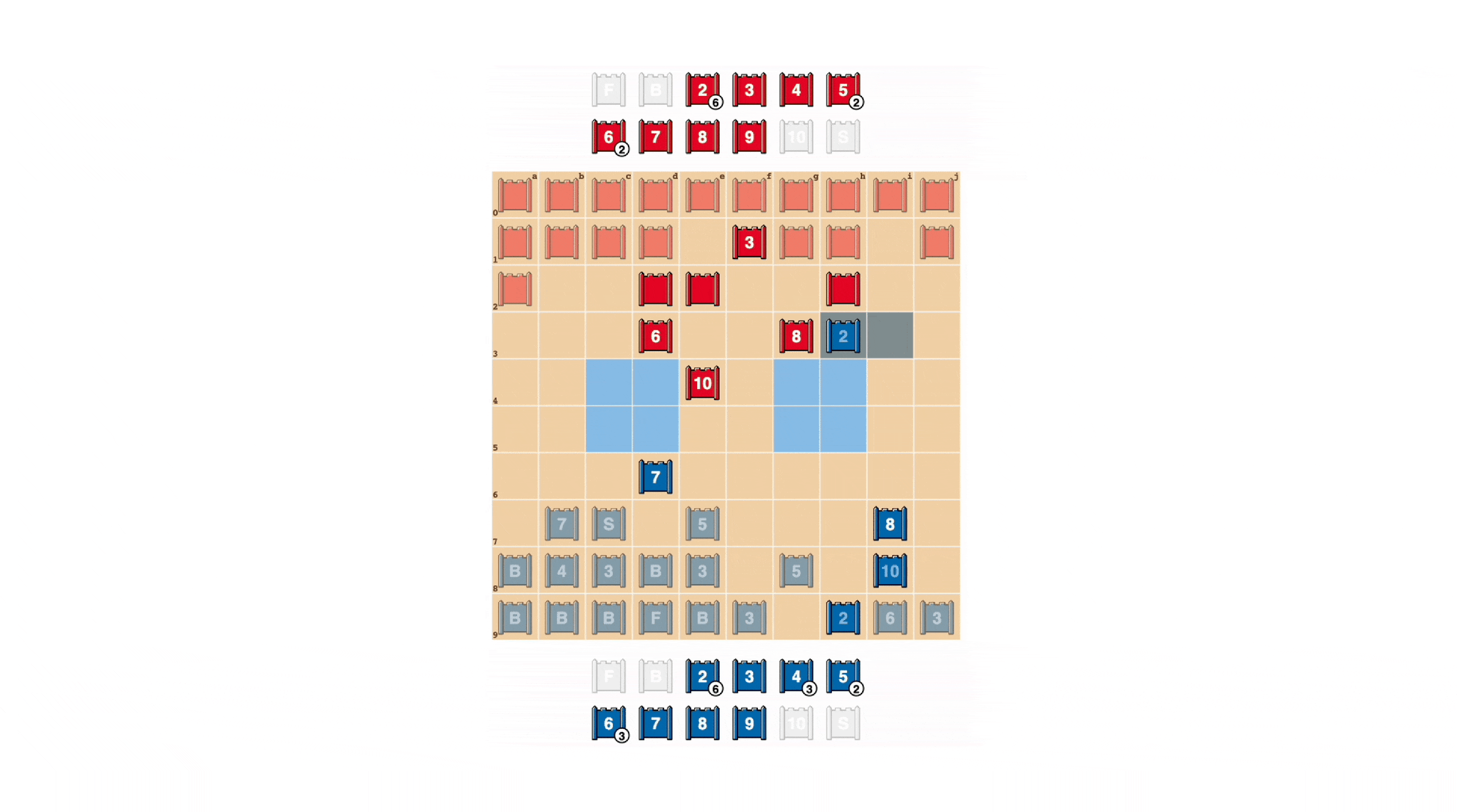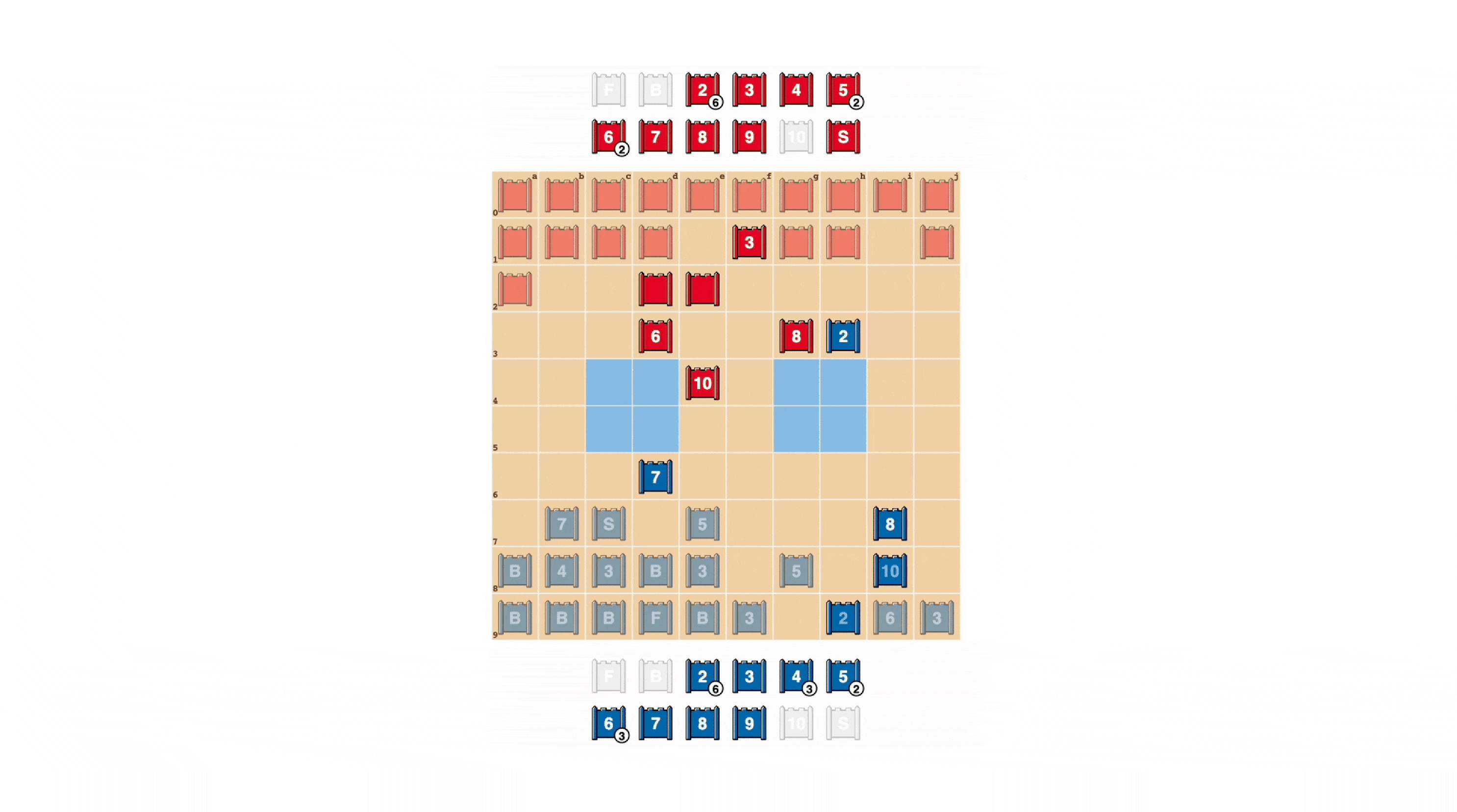
就像扑克牌一样,一个优秀的Stratego玩家有时必须展现出强大的气势,即使自己并不强大。DeepNash学会了各种虚张声势的策略。在下面的例子中,DeepNash将一个2(一个对手不知道的较弱的侦察兵)当作一个高级别的棋子,追击对手已知的8。人类对手认为追击者很可能是一个10,因此试图引诱它走进间谍的伏击。这种策略通过仅冒险损失一个次要棋子,成功地将对手的间谍,一个关键的棋子,逼出并消灭。
通过观看DeepNash与(匿名的)人类专家进行的四场完整对局的视频,了解更多:Game 1,Game 2,Game 3,Game 4。
“DeepNash的水平让我感到惊讶。我以前从未听说过能够在与经验丰富的人类玩家对战中获胜的人工Stratego玩家。但在与DeepNash对战后,我对它在Gravon平台上获得的前三名并不感到惊讶。如果允许参加人类世界锦标赛,我相信它会表现出色。” – Vincent de Boer,论文合著者和前Stratego世界冠军
未来的方向
虽然我们为高度规定的Stratego世界开发了DeepNash,但我们的新颖R-NaD方法可以直接应用于其他两人零和博弈的游戏,无论是完全信息还是不完全信息。R-NaD有潜力远远超越两人游戏设置,解决大规模现实世界问题,这些问题通常在于不完全信息和庞大的状态空间。
我们也希望R-NaD能够帮助解锁人工智能在具有大量人类或人工智能参与者,并且他们之间可能没有关于其他人意图或环境发生情况的信息的领域中的新应用,例如大规模交通管理的优化以减少驾驶员的行程时间和相关车辆排放。
通过创建一个在不确定性面前具有鲁棒性的通用人工智能系统,我们希望将人工智能的问题解决能力进一步引入到我们本质上不可预测的世界中。
通过阅读我们在Science上的论文,了解更多关于DeepNash的信息。
对于有兴趣尝试或使用我们新提出的方法的研究人员,我们已经开源了我们的代码。