BYOL-Explore:使用引导预测进行探索
BYOL-Explore Guided Prediction for Exploration

好奇驱动的探索是主动寻求新信息以增强代理对环境的理解的过程。假设代理已经学习了一个可以基于过去事件的历史来预测未来事件的世界模型。好奇驱动的代理可以使用世界模型的预测不匹配作为内在奖励,指导其探索策略以寻求新信息。随后,代理可以使用这些新信息来改进世界模型,以便能够做出更好的预测。这个迭代过程可以使代理最终探索世界中的每一个新颖之处,并利用这些信息构建准确的世界模型。
受bootstrap your own latent (BYOL)在计算机视觉、图表示学习和强化学习中的应用成功启发,我们提出了BYOL-Explore:一个概念简单但通用的、以好奇驱动为基础的AI代理,用于解决难度较高的探索任务。BYOL-Explore通过预测自己未来的表示来学习世界的表示。然后,它使用表示级别上的预测误差作为内在奖励来训练好奇驱动的策略。因此,BYOL-Explore同时学习了世界的表示、世界动态和好奇驱动的探索策略,只需通过优化表示级别上的预测误差。
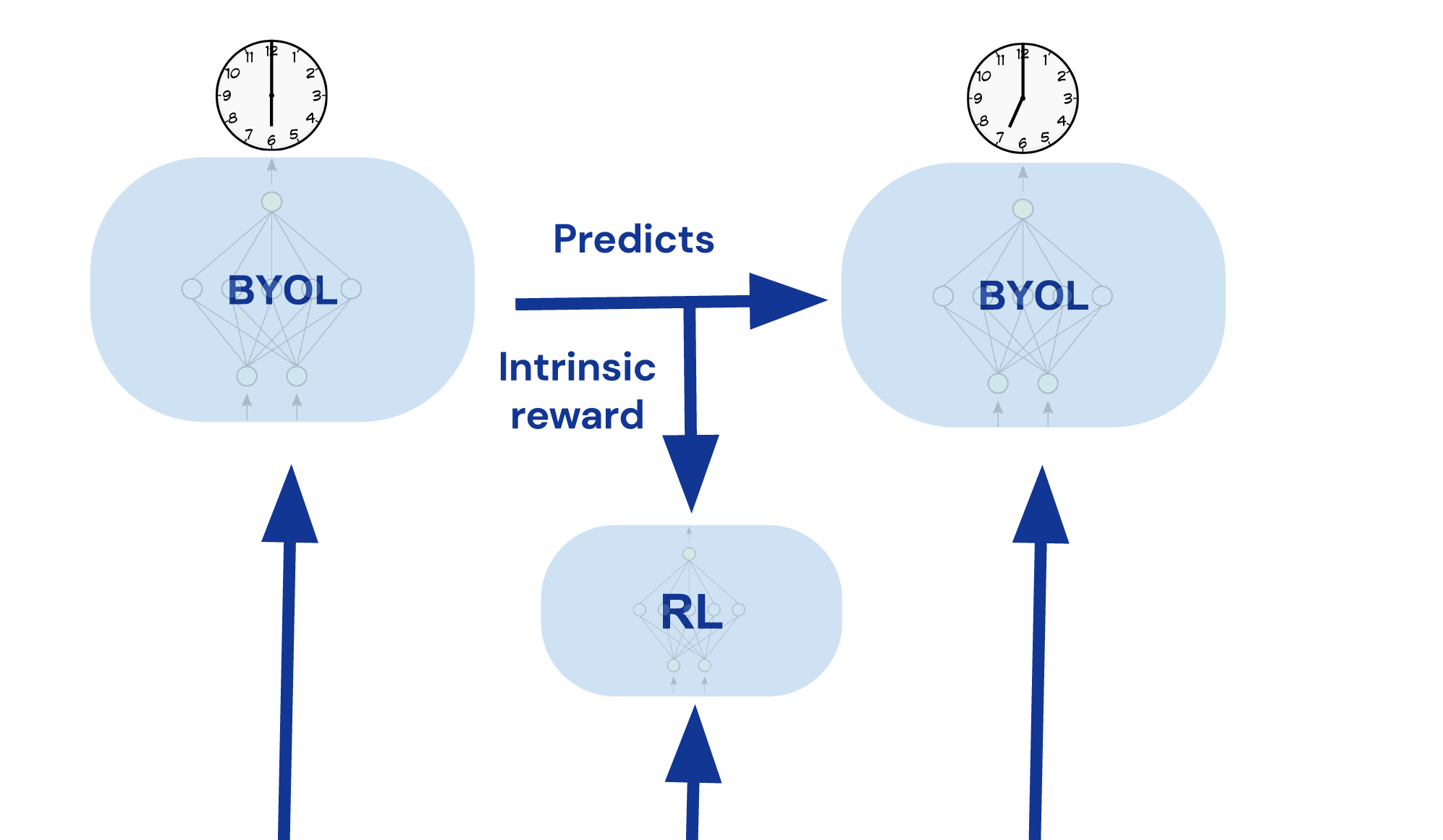

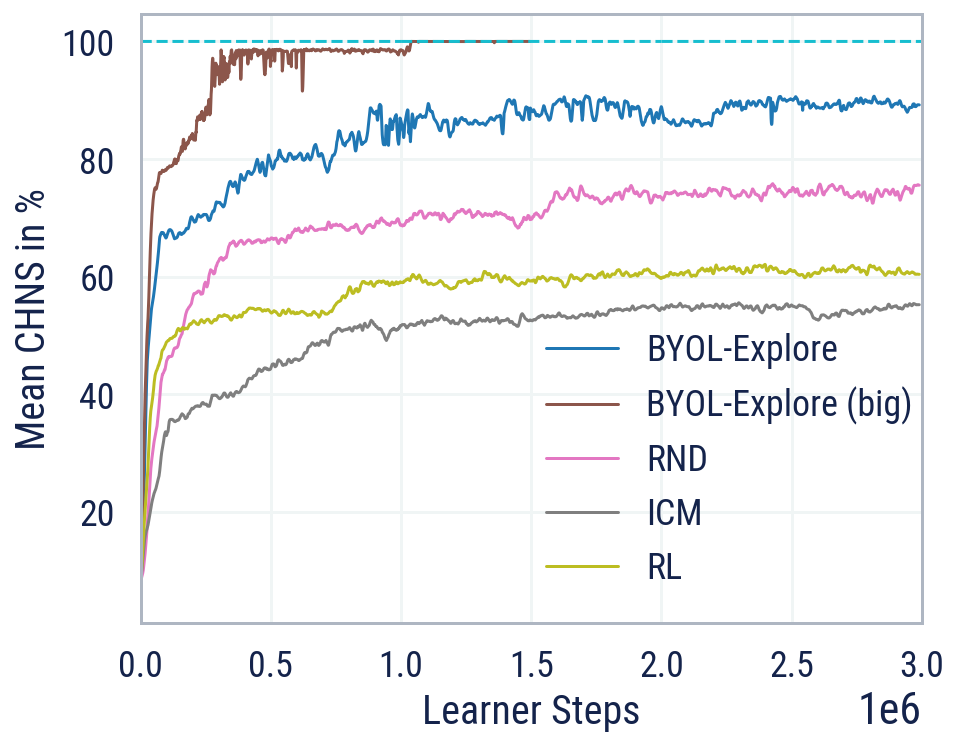
尽管其设计简单,但在面对具有挑战性的3D、视觉复杂和难度较高的探索任务DM-HARD-8时,BYOL-Explore优于标准的好奇驱动探索方法,如Random Network Distillation (RND)和Intrinsic Curiosity Module (ICM),在所有任务上的平均人类标准化分数(CHNS)方面。值得注意的是,BYOL-Explore仅使用一个网络同时在所有任务上进行训练,而之前的工作仅限于单任务设置,并且只能在提供人类专家演示的情况下在这些任务上取得有意义的进展。
作为其通用性的进一步证明,BYOL-Explore在最难的十个探索Atari游戏中实现了超人类的表现,同时比其他竞争对手如Agent57和Go-Explore具有更简单的设计。
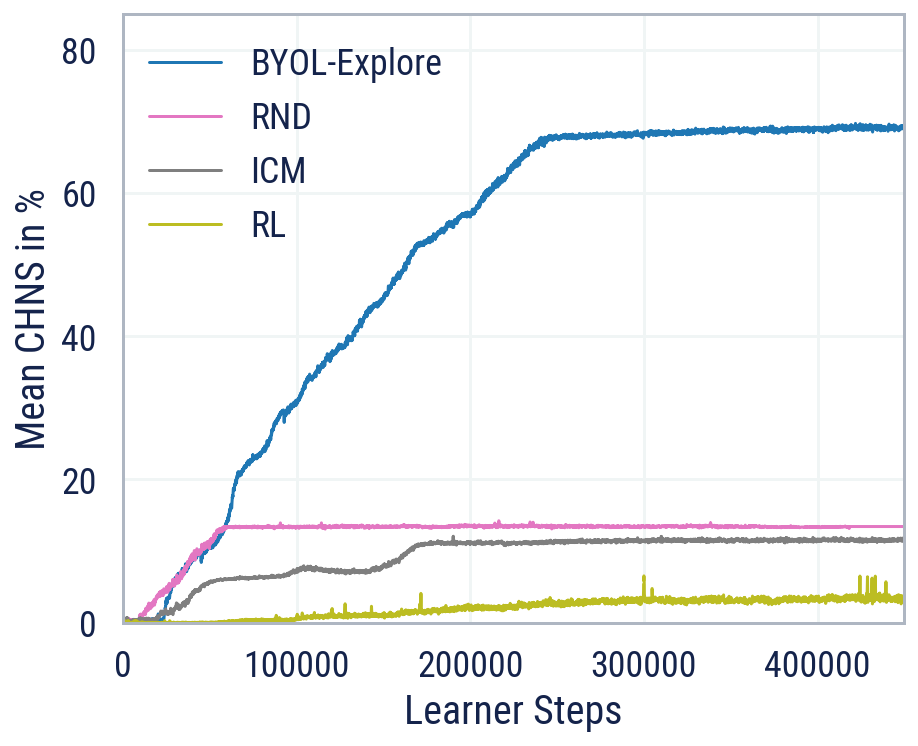
未来,我们可以通过学习概率世界模型来将BYOL-Explore推广到高度随机的环境中,该模型可以用于生成未来事件的轨迹。这将使智能体能够对环境的可能随机性建模,避免随机陷阱,并进行探索规划。






