发现系统中代理存在的时候
When proxies are found in the system.
新的、形式化的代理定义为AI代理和它们所面临的激励提供了清晰的因果建模原则
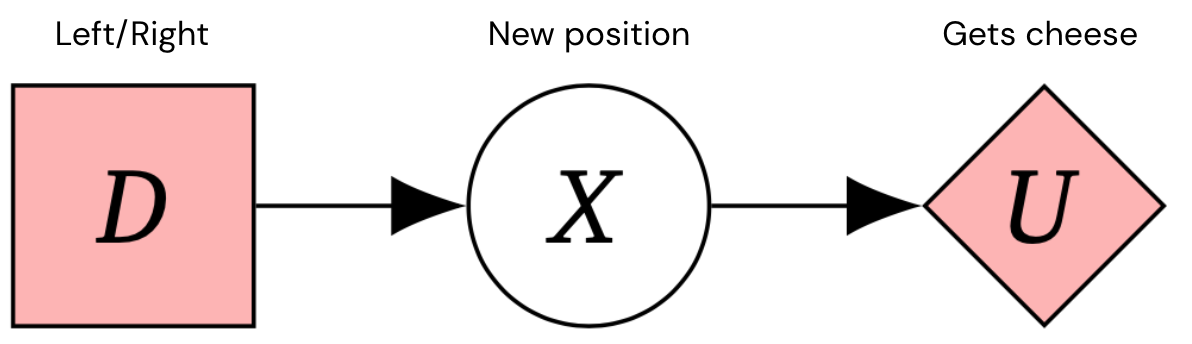
我们希望构建安全、对齐的人工通用智能(AGI)系统,使其追求设计者的预期目标。因果影响图(CIDs)是一种用于建模决策情境的方法,可以让我们推理代理的激励。例如,这是一个用于1步马尔可夫决策过程的CID——这是一个典型的决策问题框架。

通过将训练设置与塑造代理行为的激励联系起来,CIDs可以在训练代理之前揭示潜在风险,并激发更好的代理设计。但是,我们如何知道CID是否是训练设置的准确模型?
我们的新论文《Discovering Agents》介绍了解决这些问题的新方法,包括:
- 代理的首个形式化因果定义:如果代理的行为以不同的方式影响世界,它们将调整策略
- 从经验数据中发现代理的算法
- 因果模型和CIDs之间的转换
- 纠正先前关于代理因果建模的混淆
综合起来,这些结果提供了额外的保证层次,以确保没有建模错误,这意味着CIDs可以更自信地用于分析代理的激励和安全属性。
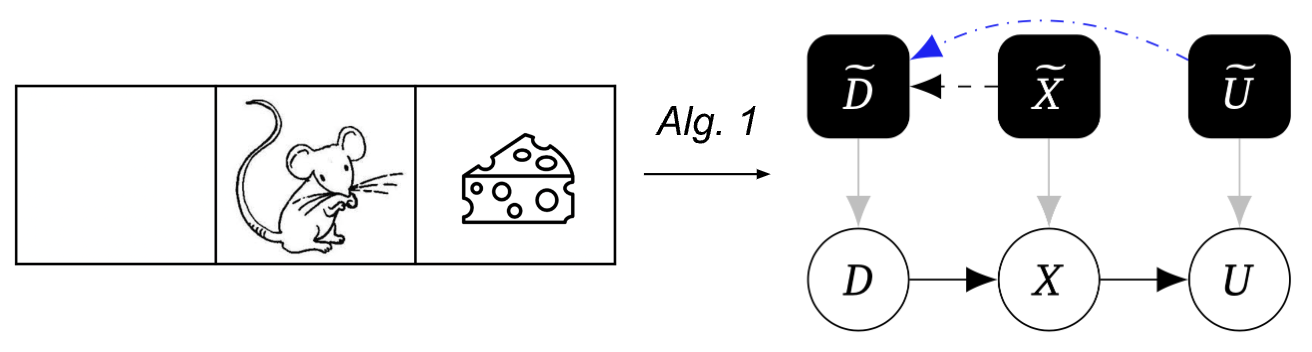
示例:将老鼠建模为代理
为了帮助说明我们的方法,考虑以下示例,包含一个世界,其中有三个方块,老鼠从中间方块开始选择向左或向右,到达下一个位置,然后可能获得一些奶酪。地板很滑,所以老鼠有可能滑倒。有时奶酪在右边,有时在左边。

这可以用以下CID表示:
可以通过机械化因果图捕捉到鼠标在不同环境设置(冰冷度、奶酪分布)下选择不同行为的直观感受,对于每个(对象级)变量,该图还包括一个控制变量的机制变量,该机制变量决定了变量如何依赖其父节点。关键是,我们允许机制变量之间存在链接。
该图中包含了额外的黑色机制节点,代表鼠标的策略以及冰冷度和奶酪分布。
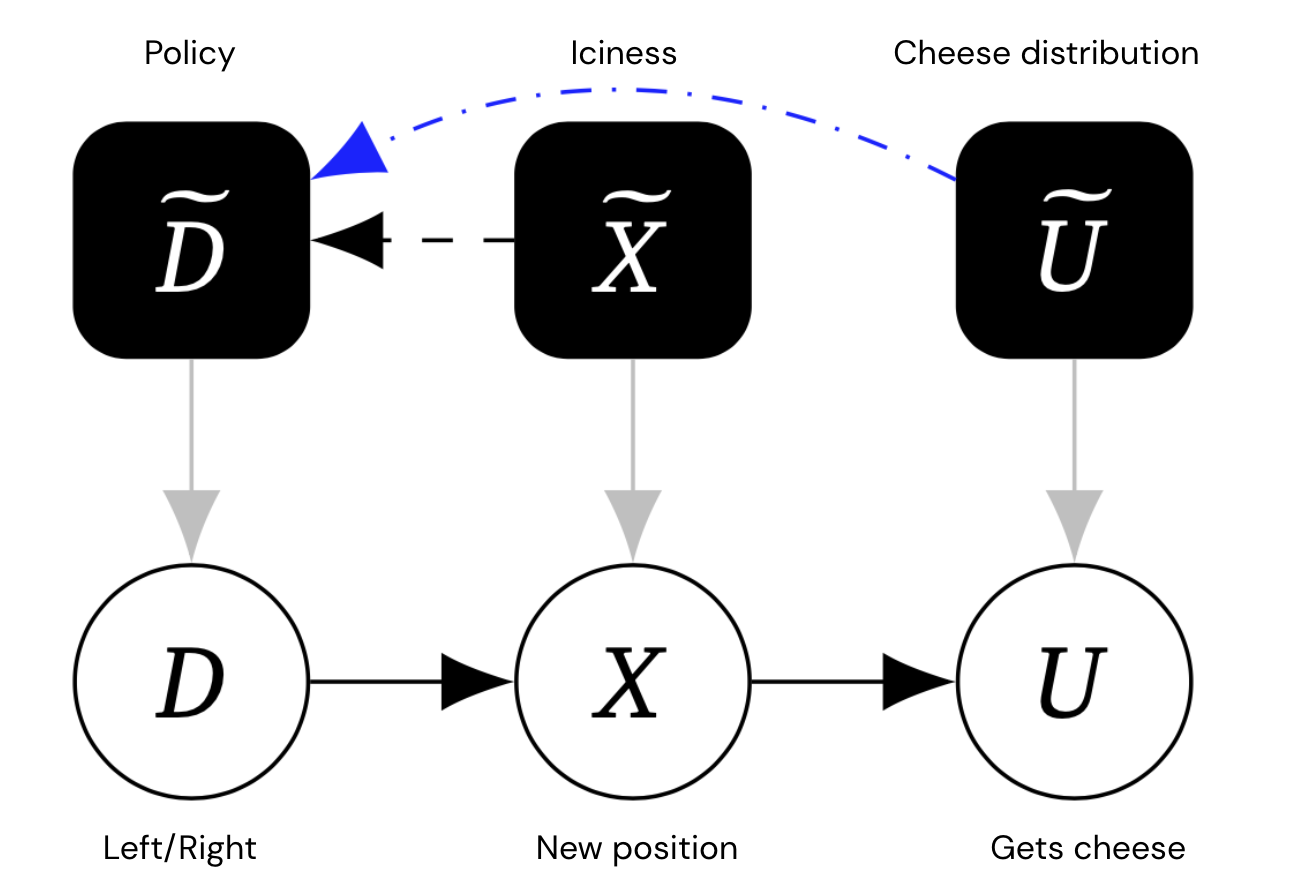
机制之间的边表示直接因果影响。蓝色边是特殊的终端边,大致上,机制边A~ → B~仍然存在,即使对象级变量A被改变,使其没有出边。
在上面的例子中,由于U没有孩子,它的机制边必须是终端边。但是,机制边X~ → D~不是终端边,因为如果我们切断X与其子节点U的联系,则鼠标将不再适应其决策(因为其位置不会影响它是否得到奶酪)。
发现代理因果关系
通过对干预实验进行推理,可以从中发现因果图。特别地,可以通过实验对A进行干预,并检查B是否有响应,即使所有其他变量保持固定。
我们的第一个算法使用这种技术来发现机械化因果图:
我们的第二个算法将这个机械化因果图转换为一个博弈图:
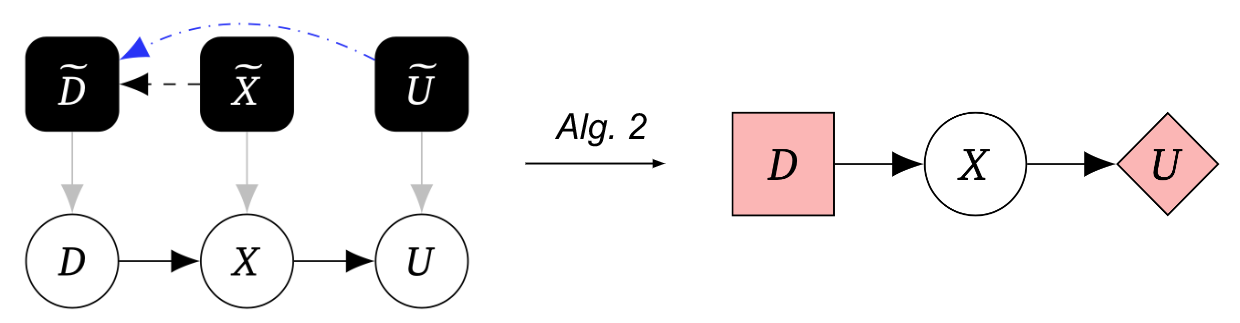
综上,通过算法1和算法2,我们可以从因果实验中发现代理,用CIDs表示它们。
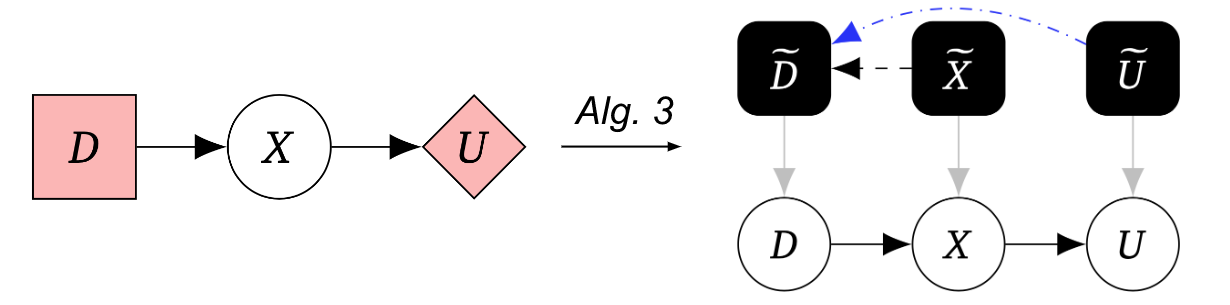
我们的第三个算法将游戏图转换为机械化因果图,使我们能够在某些附加假设下在游戏和机械化因果图之间进行转换:
更好的安全工具来建模AI代理
我们提出了代理人的第一个正式的因果定义。基于因果发现,我们的关键见解是,代理人是系统,它们根据其行为对世界产生影响的变化来适应自己的行为。事实上,我们的算法1和算法2描述了一个精确的实验过程,可以帮助评估一个系统是否包含代理人。
对AI系统的因果建模的兴趣正在迅速增长,我们的研究将这种建模基于因果发现实验。我们的论文通过改善几个示例AI系统的安全分析,展示了我们方法的潜力,并显示因果性是发现系统中是否存在代理人的有用框架 – 这是评估来自AGI的风险的一个关键问题。
想要了解更多吗?请查看我们的论文。欢迎提供反馈和评论。
.jpg)





