改进数据可视化:在Pandas中掌握基于时间的重新采样
提升数据可视化能力:掌握Pandas中基于时间的重新采样技巧

本全面的文章将讨论使用Python和Pandas库进行基于时间的数据可视化。如您所知,时间序列数据是洞察力的宝库,通过熟练的重新采样技术,您可以将原始时间数据转化为视觉上引人入胜的叙述。无论您是数据爱好者、科学家、分析师,还是对揭示基于时间的数据中隐藏故事感到好奇,本文章都可以帮助您拥有知识和工具来提升您的数据可视化技巧。因此,让我们开始讨论Pandas的重新采样技术,将数据转化为信息丰富、引人入胜的时间化瑰宝。
为什么进行数据重新采样?
在处理基于时间的数据可视化时,数据重新采样至关重要且非常有用。它允许您控制数据的细粒度,提取有意义的洞察力,并创建视觉上引人入胜的表达以更好地理解它。在下图中,您可以观察到根据需求,可以通过频率上采样或下采样时间序列数据。 
基本上,数据重新采样有两个主要目的:
- 细粒度调整:采集大数据可让您更改收集或聚合数据点的时间间隔。您可以仅获得关键信息,而不会获取噪音。这有助于剔除嘈杂的数据,将数据转化为更易于可视化的形式。
- 对齐:它还有助于将来自多个来源以不同时间间隔的数据对齐,确保在创建可视化或进行分析时的一致性。
例如,
假设您有某家公司的每日股票价格数据,您从股票交易所获得,且您希望在分析中不包含嘈杂的数据点的情况下可视化长期趋势。因此,您可以通过将这些每日数据重新采样到每月频率,并取每月的平均收盘价,从而减少可视化的数据量,并使您的分析能够提供更好的洞察力。
import pandas as pd# 样本每日股票价格数据data = {'Date': pd.date_range(start='2023-01-01', periods=365, freq='D'),'StockPrice': [100 + i + 10 * (i % 7) for i in range(365)]}df = pd.DataFrame(data)# 重新采样为每月频率monthly_data = df.resample('M', on='Date').mean()print(monthly_data.head())
在上述示例中,您已经观察到我们已经重新采样了每日数据,并计算了每月的平均收盘价,这样您就能够得到平滑、较少噪音的股票价格数据表示,从而更容易识别长期趋势和模式,以支持决策。
选择正确的重新采样频率
在处理时间序列数据时,重新采样的主要参数是频率,您必须正确选择以获得富有洞察力和实用性的可视化。基本上,粒度和清晰度之间存在权衡,粒度表示数据的详细程度,清晰度表示数据模式展示的好坏。
例如,
假设您拥有一年内每分钟记录的温度数据。如果您需要可视化年度温度趋势,使用分钟级数据会导致图表过于密集和混乱。另一方面,如果您将数据聚合为年度平均值,可能会丧失有价值的信息。
# 样本分钟级温度数据data = { 'Timestamp': pd.date_range(start='2023-01-01', periods=525600, freq='T'), 'Temperature': [20 + 10 * (i % 1440) / 1440 for i in range(525600)]}df = pd.DataFrame(data)# 重新采样到不同的频率daily_avg = df.resample('D', on='Timestamp').mean()monthly_avg = df.resample('M', on='Timestamp').mean()yearly_avg = df.resample('Y', on='Timestamp').mean()print(daily_avg.head())print(monthly_avg.head())print(yearly_avg.head())
在这个例子中,我们将按分钟为单位的温度数据重新采样为每日、每月和每年的平均值。根据您的分析或可视化目标,您可以选择最适合您目的的详细程度。每日平均值揭示了每日的温度模式,而年度平均值则提供了对年度趋势的高级概览。
通过选择最佳的重新采样频率,您可以平衡数据细节和可视化清晰度之间的关系,确保您的观众可以轻松地辨别出您想要传达的模式和见解。
聚合方法和技巧
在处理基于时间的数据时,了解各种聚合方法和技巧非常重要。这些方法使您能够有效地总结和分析数据,揭示时间相关信息的不同方面。标准的聚合方法包括计算总和、均值或应用自定义函数。 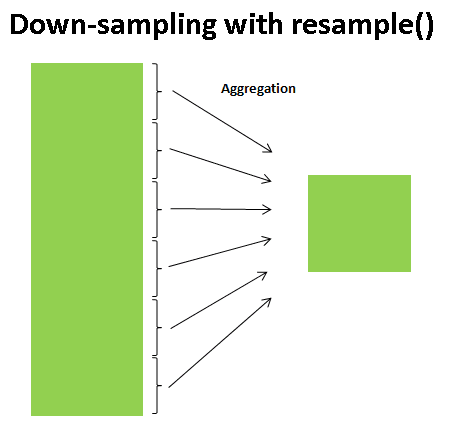
例如,
假设您有一个包含一年内零售店每日销售数据的数据集。您想要分析年度销售趋势。为此,您可以使用聚合方法计算每月和每年的总销售额。
# Sample daily sales datadata = {'Date': pd.date_range(start='2023-01-01', periods=365, freq='D'),'Sales': [1000 + i * 10 + 5 * (i % 30) for i in range(365)]}df = pd.DataFrame(data)# Calculate monthly and yearly sales with the aggregation methodmonthly_totals = df.resample('M', on='Date').sum()yearly_totals = df.resample('Y', on='Date').sum()print(monthly_totals.head())print(yearly_totals.head())
在这个例子中,我们使用sum()聚合方法将每日销售数据重新采样为每月和每年的总销售额。通过这样做,您可以在不同粒度级别上分析销售趋势。月度总额提供了季节性变化的见解,而年度总额则提供了一年中的总体业绩概述。
根据您具体的分析要求,您还可以使用其他聚合方法,如计算均值和中位数,或根据数据分布应用自定义函数,这取决于问题的意义。这些方法使您能够从基于时间的数据中提取有价值的见解,通过总结数据以符合您的分析或可视化目标。
处理缺失数据
处理缺失数据是处理时间序列的关键部分,确保您的可视化和分析在处理数据间隙时仍然准确和有信息性。
例如,
想象一下,您正在处理一个历史温度数据集,但由于设备故障或数据收集错误,某些天的温度读数缺失。您必须处理这些缺失值以创建有意义的可视化并保持数据的完整性。
# Sample temperature data with missing valuesdata = { 'Date': pd.date_range(start='2023-01-01', periods=365, freq='D'), 'Temperature': [25 + np.random.randn() * 5 if np.random.rand() > 0.2 else np.nan for _ in range(365)]}df = pd.DataFrame(data)# Forward-fill missing values (fill with the previous day's temperature)df['Temperature'].fillna(method='ffill', inplace=True)# Visualize the temperature dataimport matplotlib.pyplot as pltplt.figure(figsize=(12, 6))plt.plot(df['Date'], df['Temperature'], label='Temperature', color='blue')plt.title('Daily Temperature Over Time')plt.xlabel('Date')plt.ylabel('Temperature (°C)')plt.grid(True)plt.show()
输出: 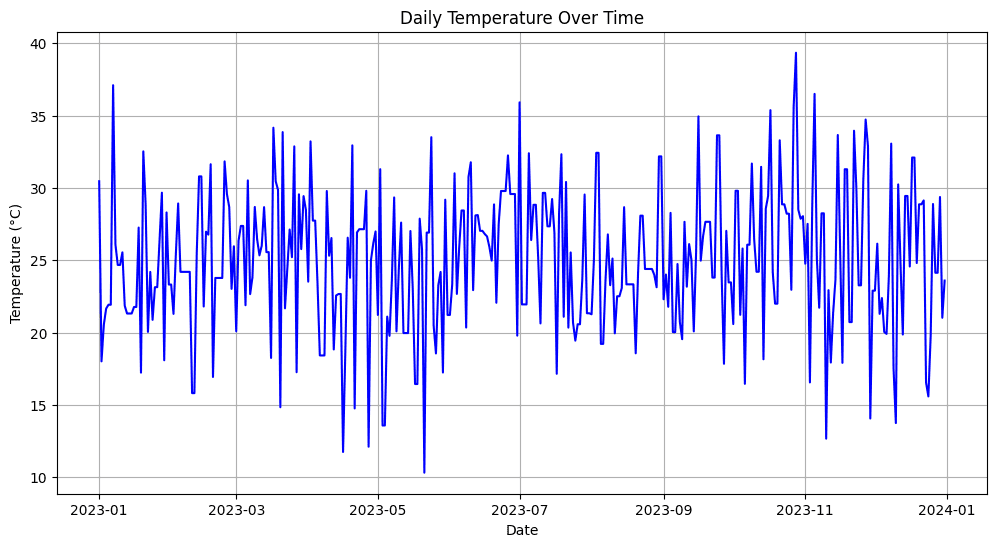
在上面的例子中,您可以看到首先我们模拟了缺失的温度值(大约20%的数据),然后使用向前填充(ffill)方法填补了这些间隙,这意味着缺失的值被替换为前一天的温度。
因此,处理缺失数据确保您的可视化准确地表示时间序列中的基本趋势和模式,防止间隙扭曲您的见解或误导您的观众。根据数据的性质和研究问题,可以采用各种策略,例如插值或向后填充。
可视化趋势和模式
在pandas中进行数据重新采样可以让你可视化顺序或基于时间的数据的趋势和模式,这进一步帮助你收集洞察并有效地向他人传达结果。结果,你可以找到清晰和信息丰富的数据可视化呈现来突出不同的组成部分,包括趋势、季节性和不规则模式(可能是数据中的噪音)
例如,
假设你有一个包含过去几年网站每日访问量数据的数据集。你的目标是可视化随后几年的总体流量趋势,识别任何季节性模式,并发现流量的不规则峰值或低谷。
# 示例每日网站访问量数据集data = {'Date': pd.date_range(start='2019-01-01', periods=1095, freq='D'),'Visitors': [500 + 10 * ((i % 365) - 180) + 50 * (i % 30) for i in range(1095)]}df = pd.DataFrame(data)# 创建一个折线图来可视化趋势plt.figure(figsize=(12, 6))plt.plot(df['Date'], df['Visitors'], label='每日访问量', color='blue')plt.title('随时间变化的网站流量')plt.xlabel('日期')plt.ylabel('访客数')plt.grid(True)# 添加季节性分解图from statsmodels.tsa.seasonal import seasonal_decomposeresult = seasonal_decompose(df['Visitors'], model='additive', freq=365)result.plot()plt.show()输出: 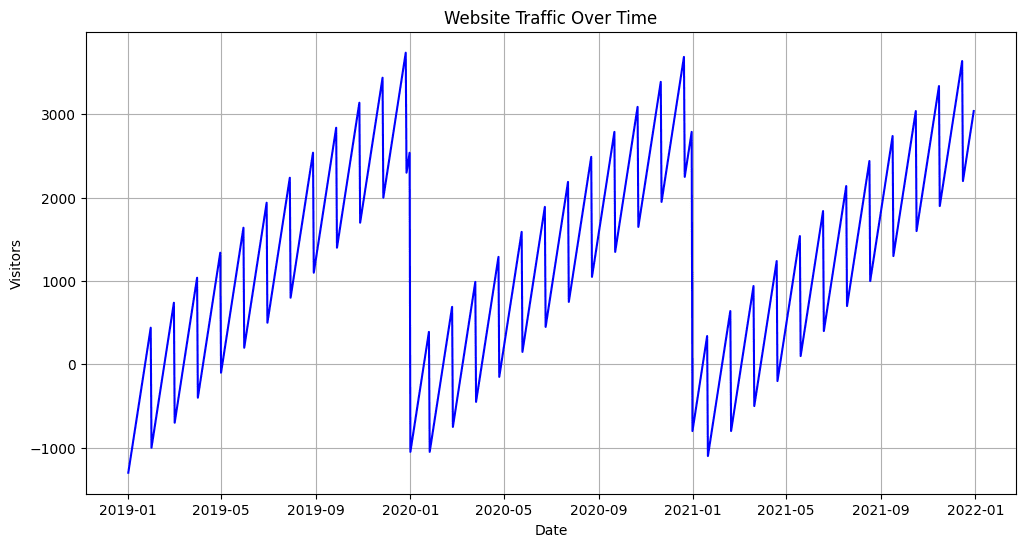
在上述示例中,我们首先创建了一个折线图,以便可视化随时间变化的每日网站访问量趋势。这个图描述了数据集中的整体增长和任何不规则模式。此外,为了将数据分解为不同的组成部分,我们使用了statsmodels库中的季节性分解技术,包括趋势、季节性和残差组成部分。
通过这种方式,你可以有效地传达网站的流量趋势、季节性和异常情况给利益相关者,这增强了你从基于时间的数据中获取重要见解并将其转化为数据驱动决策的能力。
总结
Colab笔记本链接: https://colab.research.google.com/drive/19oM7NMdzRgQrEDfRsGhMavSvcHx79VDK#scrollTo=nHg3oSjPfS-Y
在本文中,我们讨论了Python中的基于时间的数据重新采样。所以,为了总结我们的会话,让我们概括一下本文中涉及的重要点:
- 基于时间的数据重新采样是一种强大的技术,用于转换和总结时间序列数据,以获得更好的决策见解。
- 谨慎选择重新采样频率对于在数据可视化中平衡细粒度和清晰度至关重要。
- 聚合方法如求和、平均值和自定义函数有助于揭示基于时间的数据的不同方面。
- 有效的可视化技术有助于识别趋势、季节性和不规则模式,为找到的研究结果提供清晰的沟通。
- 金融、天气预报和社交媒体分析等实际应用案例展示了基于时间的数据重新采样的广泛影响。
Aryan Garg是一名电气工程学士学位的学生,目前正在大学本科的最后一年。他对Web开发和机器学习领域感兴趣。他追求了这个兴趣,并渴望在这些方向上做更多的工作。






