Python水质EDA和饮用水分析
Python水质EDA和饮用水分析' can be condensed as 'Python水质EDA和饮用水分析
理解数据分析、可视化技术
能够提供足够的新鲜饮用水是一项核心要求。在气候变化讨论中,最大的挑战之一就是确保足够的淡水以供生存。水质是一个重要问题,影响着所有物种。地球上只有约百分之三的水是淡水。其中只有1.2%可以用作饮用水,其余的则储存在冰川、冰盖和永久冻土中,或深埋在地下。使用数据驱动的方法来评估影响水质的特征,可以极大地提高我们对水的饮用性的理解。
从其最基本的层面上看,水的饮用性与水的安全性有关。数据技术可以用来审查这一目标特征。其他问题也出现在我们目前的审查范围之外:
我们能够消耗所有类型的淡水吗?
世界上有多少百分比的淡水可以被获取?
随着海平面的上升,水位是否上升了?
在本文中,我们将使用一个小型水质数据集进行探索。通过使用pandas和numpy进行数据分析技术,我们将寻找隐藏的见解。在数据可视化方面,将使用matplotlib和seaborn库。将采用一系列探索性数据分析(EDA)技术,以进一步澄清数据质量。
每个数据可视化都旨在突出数据的不同特征。它们还将为用户提供模板,可应用于其他挑战。
数据集
对于这个分析,水质数据集来自Kaggle¹。
水质
饮用水饮用性
www.kaggle.com
使用Python代码的jupyter笔记本实例进行处理。
import sysprint(sys.version) # 显示安装的Python版本运行上述脚本后,将显示使用的Python版本为3.7.10。为了能够复制后面的结果,用户应确保在工作环境中使用Python 3。
理解数据
首先,我们需要了解我们正在处理的数据。由于文件格式是csv文件,将使用标准的pandas导入语句read_csv。
# 导入要审查的数据集作为DataFramedf = pd.read_csv("../input/water-potability/water_potability.csv")# 查看前五个观察值df.head()导入数据后,该代码将变量df赋值为来自pandas方法的DataFrame输出结果。
与任何你将处理的数据集一样,查看一些记录样本将帮助你获得舒适感。DataFrame具有大量与之关联的方法,pandas API是一个很好的资源。在API中,可以使用head方法。默认情况下,输出1.1显示DataFrame的前5行。为了显示更多的行,需要在括号内放入一个数字值。有两种替代方法可以对DataFrame进行采样,即i)sample(df.sample())从索引中选择随机行,或者ii)tail(df.tail())从索引中选择最后n行。
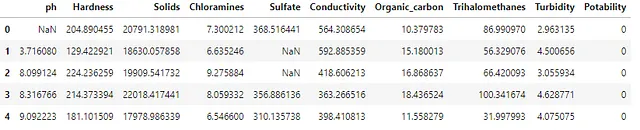
运行任何方法时,方法名后面需要加上括号,以便Python解释器生成结果。
显示DataFrame的内存可能是一个常见的任务,特别是当涉及到内存限制时。例如,导入的数据集可能比Python会话中可用的内存还要大。通过使用pandas库,可以在内存中创建一个DataFrame,因此用户在执行这些处理步骤时应了解可以使用多少内存。
# 显示DataFrame的信息-包含内存详细信息
df.info(memory_usage="deep")上面的代码可以用作显示输出1.2的方法。通过包含关键字memory_usage,Python解释器被强制进行更深入的搜索以了解下面显示的内存使用情况。默认选项将执行一般搜索以了解,因此如果需要对评估进行准确性,则确保应用上述关键字短语。
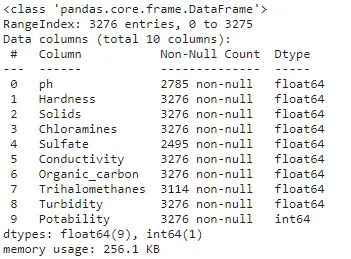
从输出1.2显示的结果中,可以显示一系列详细信息,包括列名和数据类型,还可以确认变量的类和非空值的数量。我们可以看到整个表中显示了3276行。然而,对于列Sulfate,只有2495个非空值。因此,可以审查一些缺失值以了解这些缺失条目与其他列是否存在模式。我们将在本文后面讨论一种数据可视化技术,它可以帮助进行模式识别。
在之前的导入语句之后,用户可以调整列的Dtype,如果默认选项不符合预期。上面的结果显示,对于十进制数,应用了float Dtype,整数显示为int。此外,为这些数值列包括了最大的字节内存类型,以提供潜在输入值的完全覆盖。许多时候,用户应该评估这些Dtypes是否持有正确范围的值,如果以后预期的是较小范围,则可以分配较小的字节值。应用这种逻辑将有助于增加DataFrame的内存效率,并在处理时提高性能。
info方法上面显示的一个特征是DataFrame的结构,可以通过许多其他方法进行审查。这样的元数据可以让程序员审查行数和列数的基本组成部分。
# DataFrame的形状-显示元组(#行数,#列数)
print(df.shape)
# 查找DataFrame中的行数
print(len(df))
# 从形状元组中提取信息
print(f'行数:{df.shape[0]} \n列数:{df.shape[1]}')在Python中调用shape等属性时,不需要括号。属性是可以由类和对象都访问的数据结果。之前我们审查了一个方法,它是包含在类中的函数。要进一步了解Python类语句的工作原理的细节,需要进行深入研究。但是,我们可以继续使用已使用的代码,并显示输出1.3显示了一些值。
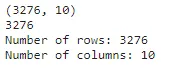
第一行显示的是形状输出,它是由带有两个值的括号表示的元组。从上面显示的代码中,我们可以访问该元组内的相对位置,以显示第一个和第二个位置的值。由于Python使用0索引约定,通过在方括号内应用0,将返回第一个值。我们可以看到该元组包含了第一位置的行数,其次是第二位置的列数。要查找行数的另一种方法是使用函数len,它显示了DataFrame的长度。
汇总统计
在这一部分中,我们开始查看DataFrame列的汇总细节。简单的describe方法可用于对数值列进行高级数据分析。由于我们的DataFrame只包含数值列,所以所有的汇总属性都会被生成。当存在字符和数值列的混合时,必须包含其他关键字参数以显示相关的输出。
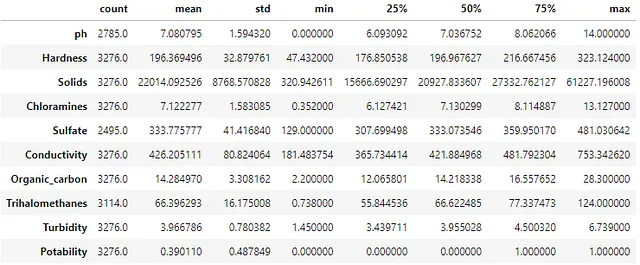
# 查看每个变量的高级汇总细节
df.describe()输出1.4显示了每列的默认汇总值。计数值可以解释为非空值的计数。如果总数小于DataFrame中的行总数,则显示包含缺失值的列。对于每个变量,我们可以看到一系列的值。我们可以使用四个时刻方法来了解i)均值、ii)方差、iii)偏度和iv)峰度,基于显示的数据。
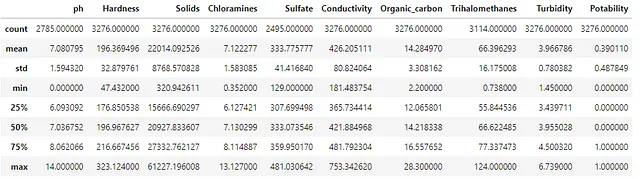
在审查摘要详细信息时,了解特征属性的外部见解也是至关重要的。我们根据经验知道,pH值应该在0和14之间。如果一个值落在这个范围之外,那么特征值就需要被审查和纠正。对于用于评估水质的数据,具有接近7的平均值和中位数(由第50个百分位数显示)适用于水的中性属性。
如果数据框中有更多的特征,则前一个代码块的输出可能难以解释。输出可以水平分散到更宽的范围,而无需滚动即可显示。
# 转置摘要详细信息 - 便于审查较多的特征df.desribe().T能够转置输出是一种有用的方法。在上面的代码块中,链接T方法生成了下面的输出1.5。现在,用户更容易审查在行索引中显示的列名称,而摘要指标则显示为列标题。这个对describe方法的小调整在具有较多列的情况下非常有效。
为了更详细地了解describe方法,我们可以使用jupyter笔记本的魔术函数问号来解释docstring。
# 在jupyter中使用魔术函数显示docstringdf.describe?这将帮助用户使用这种方法审查任何方法的默认参数值(关键字和位置)。

输出1.6提供了用户审查方法的内部工作原理。每个参数的默认值范围以及定义有助于应用该方法。有一系列可以增加程序员生产力的jupyter魔术函数可用。
缺失值
如前所述,从元数据和摘要统计数据中可以看出数据框中存在一些缺失值。为了确认这一点,我们可以应用下面的代码块。
# 按列检查缺失值df.isnull().sum()该代码链接了第一个isnull方法和sum方法,以创建每列的缺失值数量。isnull评估会检查列中的非空值。sum方法用于执行计数。输出1.7显示了三列中显示的缺失值。

了解具有缺失值的行总数是一个很好的起点。但是,最好还是审查各列中缺失值的比例。
# 按列计算缺失值比例def isnull_prop(df): total_rows = df.shape[0] missing_val_dict = {} for col in df.columns: missing_val_dict[col] = [df[col].isnull().sum(), (df[col].isnull().sum() / total_rows)] return missing_val_dict# 应用缺失值方法null_dict = isnull_prop(df)print(null_dict.items())创建isnull_prop用户定义函数使我们能够为每个列创建一个值的字典。使用这个函数,我们已经生成了上面的计数值,并使用shape属性来了解缺失值的百分比。
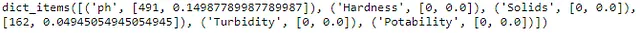
图1.8显示了一个难以可视化的输出。为了确保我们不会错过最终的信息,可以生成一个DataFrame。
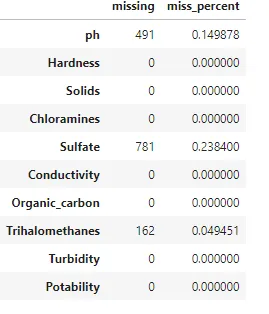
# 创建缺失值信息的DataFramedf_missing = pd.DataFrame.from_dict(null_dict, orient="index", columns=['missing', 'miss_percent'])df_missing将字典变量应用于pandas DataFrame方法会更容易理解每列的差异。图1.9现在包括miss_percent列。现在我们可以应用一个阈值来评估缺失值的百分比是否在我们预期的范围内以使用该列。如果该值过高,例如硫酸盐值大于20%,可以设置一个用户定义的控制,以突出显示该列需要在将来的使用中要么被排除,要么进行更详细的审查。
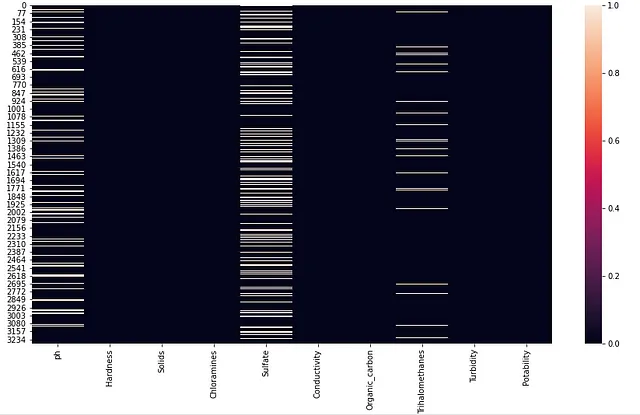
另一种审查缺失值是否存在任何模式的方法是使用seaborn数据可视化库的heatmap方法。
# 使用heatmap显示缺失值以了解任何模式plt.figure(figsize=(15,8))sns.heatmap(df.isnull());应用上面的代码块将生成输出1.10。此可视化提供了进一步的上下文,以查看是否有多行对于所有三个变量都有缺失值。可能的情况是,在原始数据集中填充数据的用户一直显示缺失值。有了这个洞察力,我们可以产生基于数据的见解,以便更有效地减少缺失值的数量。
理解pH变量分布
最后一个评估是对我们已有外部知识的变量进行审查。使用seaborn库,我们可以生成pH变量的直方图。
# 设置直方图,均值和中位数sns.displot(df["ph"], kde=False)plt.axvline(x=df.ph.mean(), linewidth=3, color='g', label="mean", alpha=0.5)plt.axvline(x=df.ph.median(), linewidth=3, color='y', label="median", alpha=0.5)# 设置标题、图例和标签plt.xlabel("ph")plt.ylabel("Count")plt.title("ph的分布", size=14)plt.legend(["mean", "median"]);print(f'平均pH值 {df.ph.mean()} \n 中位数pH值 {df.ph.median()} \n 最小pH值 {df.ph.min()} \n 最大pH值 {df.ph.max()}')类似于之前的打印语句,f字符串语句允许我们添加均值、中位数、最小值和最大值,以便更容易地查看分布。
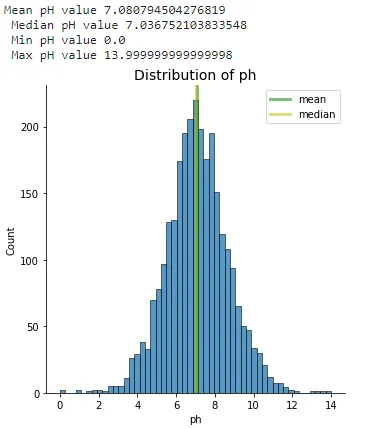
图1.11显示了大多数pH值接近中间值。由于分布类似于正态分布,我们可以利用这个洞察力在向外部用户呈现细节时提供帮助。
结论
在本文中,我们旨在回顾EDA评估的早期阶段。首先,我们对导入的数据的元数据进行了初步审查,以展示早期的洞察力。通过深入研究总结统计数据,我们能够着重关注缺失值。最后,我们能够审查pH变量的直方图,以确保该变量符合外部预期。
接下来的文章将继续这一旅程,并试图开发旨在预测水质的模型。我们将使用分类机器学习技术提供基准模型。
请留下您的评论,非常感谢您的阅读!
您可以通过LinkedIn与我交流关于数据的一切。我还分享了其他故事:
在SQL中声明变量
确保关键变量在SQL代码的开头声明,可以帮助自动重复使用代码。
towardsdatascience.com
高级SQL操作
审查更高级的SQL操作,以从爱尔兰天气数据集中提取其他数据洞察。
towardsdatascience.com
开发SQL表
只有创建和开发SQL表,我们才能了解如何最好地利用可用的内存。
towardsdatascience.com
Python中的自然语言处理入门
开始进入自然语言处理领域的旅程
towardsdatascience.com
[1]:Kaggle数据集水质,来源于https://www.kaggle.com/datasets/adityakadiwal/water-potability,根据https://creativecommons.org/publicdomain/zero/1.0/的许可协议






