Google的Symbol Tuning是一种新的微调技术,它在LLMs中进行上下文学习
Google的Symbol Tuning是一种新的微调技术,它在LLMs中进行上下文学习' 'Google's Symbol Tuning is a new fine-tuning technique used in LLMs for contextual learning.
这种新方法可以成为新的微调技术的基础。

我最近开始了一份以人工智能为重点的教育通讯,已经有超过160,000名订阅者。TheSequence是一个没有夸大其词、没有新闻等内容的面向机器学习的通讯,每次阅读只需5分钟。其目标是让你与机器学习项目、研究论文和概念保持最新。请订阅以下以尝试:
TheSequence | Jesus Rodriguez | Substack
机器学习、人工智能和数据发展的最佳信息源
thesequence.substack.com
多亏了规模化语言模型,机器学习经历了一次革命性的飞跃,通过上下文学习能够完成具有挑战性的推理任务。然而,一个长期存在的问题是:语言模型对提示变化显示出敏感性,表明缺乏稳健的推理能力。这些模型通常需要大量的提示工程或教学措辞,甚至表现出异常行为,例如尽管暴露于错误标签,任务性能仍然不变。在他们的最新研究中,谷歌揭示了人类智能的一个基本特征:仅凭几个示例就能通过推理学习新任务的能力。
谷歌的突破性论文,题为“符号调节改善语言模型中的上下文学习”,介绍了一种创新的微调方法,称为符号调节。这种技术突出了输入-标签映射,显著提高了Flan-PaLM模型在各种情景下的上下文学习能力。

符号调节
谷歌研究引入了一种强大的微调技术,称为“符号调节”,以解决传统的指导调节方法的局限性。虽然指导调节可以提高模型性能和上下文理解能力,但它也存在一个缺点:模型可能不会受到示例的影响,因为任务通过指导和自然语言标签重复定义。例如,在情感分析任务中,模型可以简单地依赖提供的指令,而不考虑示例。
符号调节在以前未见过的上下文学习任务中表现尤为出色,优于传统方法,因为传统方法中的提示缺乏指导或自然语言标签。此外,通过符号调节调整的模型在算法推理任务中表现出卓越的能力。
最显著的结果是在上下文中处理翻转标签时的显著改进。这个成果突显了模型利用上下文信息的卓越能力,甚至超过了现有知识。
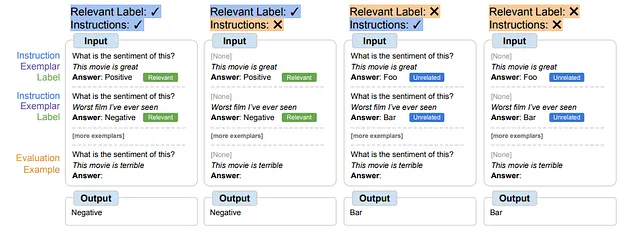
符号调节通过在没有指导的示例上微调模型,并用语义无关的标签(如“Foo”,“Bar”等)替换自然语言标签,提供了一种解决方案。在这种设置下,没有参考上下文示例的任务变得模棱两可。推理这些示例对于成功至关重要。因此,符号调节模型在需要在上下文示例和其标签之间进行细腻推理的任务上表现出更好的性能。
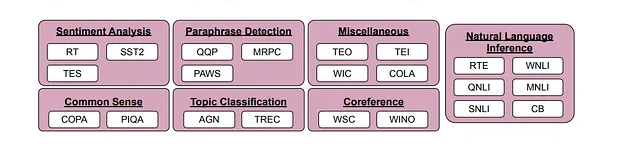
为了评估符号调节的有效性,研究人员使用了22个公开可用的自然语言处理(NLP)数据集,包括分类类型任务,考虑到离散标签。标签被重新映射为从约30,000个任意标签中随机选择的标签,这些标签属于三个类别:整数、字符组合和单词。

实验涉及对Flan-PaLM模型进行符号调节,具体包括Flan-PaLM-8B、Flan-PaLM-62B和Flan-PaLM-540B。此外,还测试了Flan-cont-PaLM-62B(简称62B-c),它代表了规模为1.3万亿个标记(token)的Flan-PaLM-62B,而不是通常的7800亿个标记。
符号调整过程需要模型通过上下文示例进行推理,以有效地执行任务,因为提示设计为防止仅从相关标签或指令中学习。符号调整的模型在需要上下文示例和标签之间进行复杂推理的环境中表现出色。为了探索这些环境,定义了四种上下文学习场景,根据学习任务中输入和标签之间所需的推理水平进行变化(取决于指令/相关标签的可用性)。
结果显示,在具有相关自然语言标签的环境中,62B及以上的模型在所有设置中都有性能改进(增长范围从+0.8%到+4.2%),而在没有此类标签的环境中,有显著的性能提升(增长范围从+5.5%到+15.5%)。值得注意的是,当相关标签不可用时,符号调整的Flan-PaLM-8B的性能超过了Flan-PaLM-62B,并且符号调整的Flan-PaLM-62B的性能优于Flan-PaLM-540B。这表明符号调整使较小的模型能够在这些任务上达到较大模型的性能,从而显著降低推断计算要求(节约约10倍的计算资源)。

总体而言,符号调整在上下文学习任务中显示出显著的改进,特别是对于不明确的提示。该技术在推理任务中也表现出更强的性能,并且能够更好地使用上下文信息来覆盖先前的知识。总的来说,符号调整可以成为最有趣的微调技术之一。





