深入泳池:揭开CNN池化层的魔力
深度探索池化层:揭秘CNN的神奇魔力
动机
池化层在所有最先进的深度学习模型中都是常见的CNN结构。它们在计算机视觉任务中广泛应用,包括分类、分割、目标检测、自编码器等等;简单地说就是在我们找到卷积层的地方使用。
在本文中,我们将深入研究使池化层工作的数学,并学习何时使用不同类型的池化层。我们还将弄清楚每种类型的特殊之处以及它们彼此之间的区别。
为什么要使用池化层
池化层提供了各种好处,使其成为CNN结构的常见选择。它们在管理空间维度方面发挥着关键作用,并且使模型能够从数据集中学习不同的特征。
以下是在模型中使用池化层的一些优点:
- 降维
所有的池化操作都从完整的卷积输出网格中选择一个子样本值。这会降低输出的维度,从而减少后续层的参数和计算量,这是卷积结构相对于全连接模型的重要优势。
- 平移不变性
池化层使机器学习模型对输入的微小变化(如旋转、平移或增强)不变。这使得模型适用于基本的计算机视觉任务,使其能够识别相似的图像模式。
现在,让我们来看看实践中常用的各种池化方法。
常见例子
为了便于比较,让我们使用一个简单的二维矩阵,并应用相同参数的不同技术。
池化层继承了卷积层的相同术语,保留了核大小、步幅和填充的概念。
因此,我们在这里定义一个有四行四列的二维矩阵。为了使用池化,我们将使用大小为2的核和步幅2,没有填充。我们的矩阵如下所示。
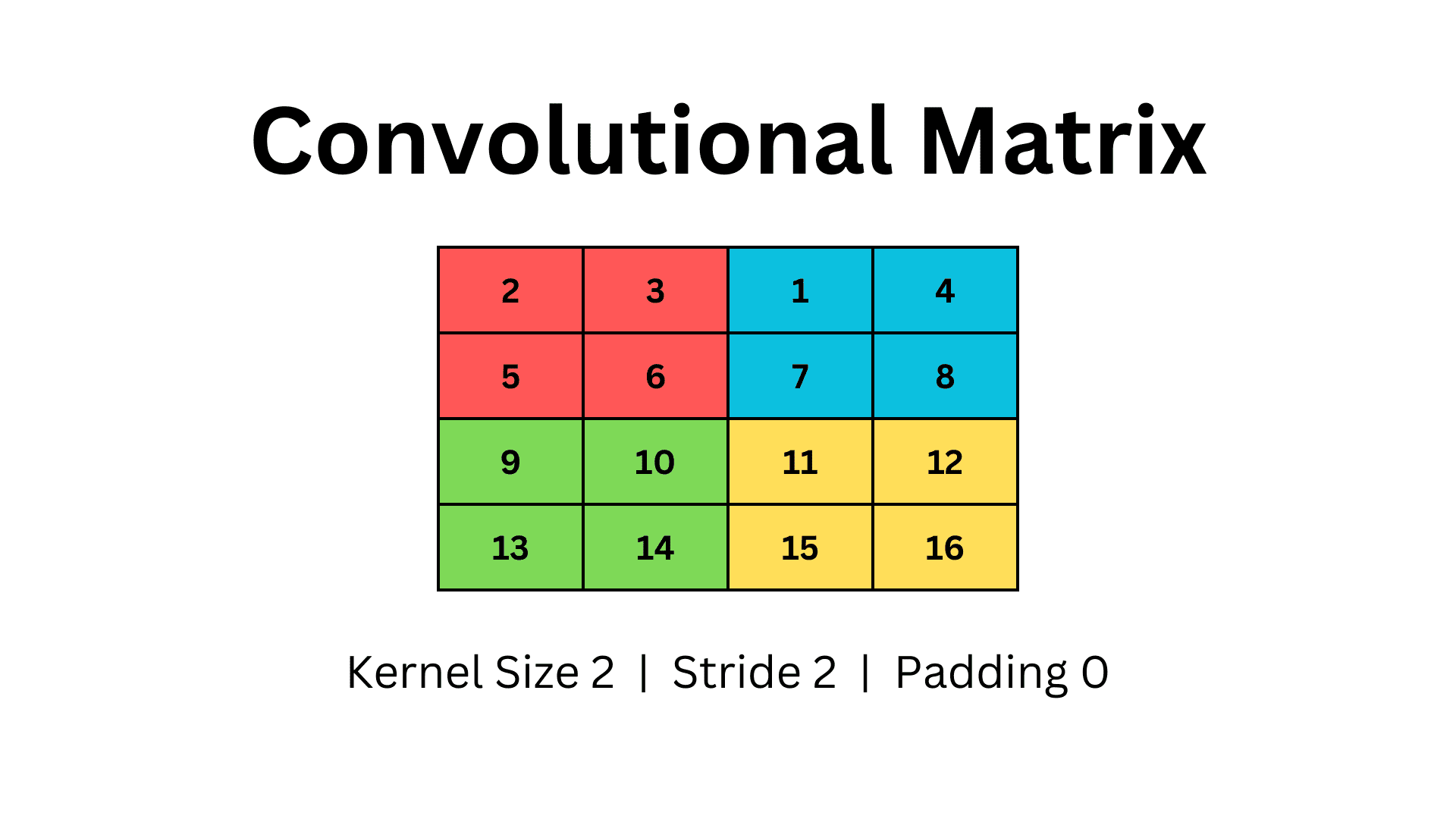
重要的是要注意,池化是基于每个通道应用的。因此,在特征图中的每个通道上重复相同的池化操作。这样,通道的数量保持不变,即使输入的特征图被降采样。
最大池化
我们迭代核对矩阵进行操作,并从每个窗口中选择最大值。在上面的例子中,我们使用大小为2×2的核,步幅2,迭代矩阵形成四个不同的窗口,用不同的颜色表示。
在最大池化中,我们只保留每个窗口中的最大值。这样可以降采样矩阵,我们得到一个较小的2×2网格作为我们的最大池化输出。

最大池化的优点
- 保留高激活值
当应用于卷积层的激活输出时,我们实际上只捕获较高的激活值。在需要较高激活的任务(如目标检测)中非常有用。实际上,我们对矩阵进行了降采样,但我们仍然可以保留数据中关键的信息。
- 保留主要特征
最大值通常表示数据中的重要特征。当我们保留这些值时,我们保留了模型认为重要的信息。
- 对噪声的抗干扰能力
因为我们的决策是基于窗口中的一个值,所以可以忽略其他值的小变化,使其更加抗噪声。
缺点
- 可能丢失信息
基于最大值进行决策会忽略窗口中的其他激活值。丢弃这样的信息可能会导致有价值的信息丢失,在后续层中无法恢复。
- 对微小偏移不敏感
在最大池化中,非最大值的微小变化将被忽略。这种对微小变化的不敏感性可能会导致问题,并且可能会造成结果的偏倚。
- 对高噪声敏感
尽管小的值变化将被忽略,但单个激活值中的高噪声或错误可能会导致选择一个异常值。这可能会显著改变最大池化的结果,导致结果的退化。
平均池化
在平均池化中,我们同样迭代窗口。然而,我们考虑窗口中的所有值,取平均值,然后将其作为结果输出。

平均池化的优势
- 保留空间信息
理论上,我们保留了窗口中所有值的一些信息,以捕捉激活值的中心趋势。实际上,我们损失了较少的信息,并且可以保留更多卷积激活值的空间信息。
- 对异常值鲁棒
对所有值进行平均使得这种方法相对于最大池化更具有鲁棒性,因为单个极端值无法显著改变池化层的结果。
- 过渡更平滑
当取值的平均值时,我们得到的输出之间的过渡不那么尖锐。这提供了我们数据的广义表示,允许降低后续层之间的对比度。
缺点
- 无法捕捉显著特征
当应用平均池化层时,窗口中的所有值都被平等对待。这无法捕捉到卷积层的主要特征,这对于某些问题领域可能会造成问题。
- 减少特征图之间的差异化
当所有值都被平均时,我们只能捕捉到区域之间的共同特征。因此,我们可能会失去图像中某些特征和模式之间的区别,对于目标检测等任务来说这肯定是个问题。
全局平均池化
全局池化与普通池化层不同。它没有窗口、核大小或步长的概念。我们将整个矩阵视为整体,并考虑网格中的所有值。在上述示例的背景下,我们取4×4矩阵中所有值的平均值,得到一个单值作为我们的结果。

何时使用
全局平均池化允许简单而强大的CNN架构。通过使用全局池化,我们可以实现适用于任何大小的输入图像的通用模型。全局池化层直接用于密集层之前。
卷积层根据核迭代和步长对每个图像进行下采样。但是,将相同的卷积应用于不同大小的图像将导致不同形状的输出。所有图像都按相同的比例进行下采样,因此较大的图像将具有较大的输出形状。当将其传递给用于分类的密集层时,大小不匹配可能导致运行时异常。
在没有超参数或模型架构的修改的情况下,实现适用于所有图像形状的模型可能很困难。使用全局平均池化可以缓解这个问题。
当在密集层之前应用全局池化时,所有输入尺寸将被减少为1×1的大小。因此,输入为(5,5)或(50,50)的图像将被下采样为大小为1×1的图像。然后它们可以被压平并发送到密集层,而不必担心大小不匹配问题。
要点
我们讨论了一些基本的池化方法以及适用的场景。选择适合我们具体任务的方法非常重要。
需要明确的是,池化层中没有可学习的参数。 它们只是执行基本数学运算的滑动窗口。池化层不可训练,但可以加速卷积神经网络架构,实现更快的计算和学习输入特征的鲁棒性。 Muhammad Arham是一位从事计算机视觉和自然语言处理的深度学习工程师。他曾负责部署和优化多个生成型人工智能应用程序,这些应用程序在Vyro.AI的全球榜单上位居前列。他对于构建和优化智能系统的机器学习模型充满兴趣,并坚信不断改进。





