在边缘人工智能应用中最大化性能
最大化性能在边缘人工智能应用中的应用
随着人工智能从云端向边缘迁移,我们看到这项技术在各种用例中的应用不断扩大,范围从异常检测到智能购物、监控、机器人和工厂自动化等应用。因此,没有一种通用的解决方案。但随着摄像头设备的快速增长,人工智能最广泛地被采用于分析实时视频数据,以自动化视频监控,提高安全性,改善运营效率,并提供更好的客户体验,从而在其行业中获得竞争优势。为了更好地支持视频分析,您必须了解优化边缘人工智能部署中系统性能的策略。
优化人工智能系统性能的策略包括
- 选择适合的计算引擎以满足或超过所需的性能水平。对于人工智能应用程序,这些计算引擎必须执行整个视觉流水线的功能(即视频预处理和后处理,神经网络推理)。
可能需要专用的人工智能加速器,无论是离散的还是集成到SoC中(与在CPU或GPU上运行人工智能推理相对)。
- 理解吞吐量和延迟之间的区别;其中吞吐量是系统可以处理数据的速率,延迟测量数据在系统中的处理延迟,并且通常与实时响应能力相关。例如,一个系统可以以每秒100帧(吞吐量)生成图像数据,但一个图像在系统中需要100毫秒(延迟)。
- 考虑未来轻松扩展人工智能性能以适应不断增长的需求、变化的要求和不断发展的技术(例如增强功能和准确性的更先进的人工智能模型)。您可以使用模块格式的人工智能加速器或额外的人工智能加速器芯片来实现性能扩展。
理解可变的人工智能性能需求
实际的性能需求取决于具体的应用。通常,对于视频分析,系统必须以每秒30-60帧及1080p或4k的分辨率处理来自摄像头的数据流。启用人工智能的摄像头将处理单个流;边缘设备将同时处理多个流。在任何情况下,边缘人工智能系统必须支持预处理功能,将摄像头的传感器数据转换为与人工智能推理部分的输入要求相匹配的格式(图1)。
预处理功能接收原始数据,并执行调整尺寸、归一化和颜色空间转换等任务,然后将输入发送到运行在人工智能加速器上的模型。预处理可以使用高效的图像处理库,如OpenCV,以减少预处理时间。后处理涉及分析推断的输出。它使用诸如非最大抑制(NMS解释大多数目标检测模型的输出)和图像显示等任务生成可操作的见解,例如边界框、类别标签或置信度分数。

人工智能模型推理可能面临额外的挑战,即每帧处理多个神经网络模型,这取决于应用程序的能力。计算机视觉应用通常涉及多个需要多个模型的人工智能任务的流水线。此外,一个模型的输出通常是下一个模型的输入。换句话说,应用程序中的模型通常彼此依赖并且必须按顺序执行。要执行的模型集合可能不是静态的,并且甚至可能根据每帧的基础动态变化。
运行多个模型动态的挑战要求外部人工智能加速器具有足够大的内存来存储这些模型。通常,集成在SoC中的人工智能加速器由于在SoC中分享的内存子系统和其他资源所施加的限制,无法管理多模型负载。
例如,基于运动预测的目标跟踪依靠连续的检测来确定矢量,该矢量用于在未来位置识别跟踪的对象。这种方法的有效性受到限制,因为它缺乏真正的重新识别能力。通过运动预测,由于遗漏的检测、遮挡或离开视野(即使是暂时的),可以丢失对象的跟踪。一旦丢失,就无法重新关联对象的跟踪。添加重新识别可以解决这个限制,但需要视觉外观嵌入(即图像指纹)。外观嵌入需要第二个网络通过处理第一个网络检测到的边界框内部包含的图像来生成一个特征向量。此嵌入可用于重新识别对象,无论时间或空间如何。由于必须为在视野范围内检测到的每个对象生成嵌入,处理要求随着场景变得更繁忙而增加。带有重新识别的目标跟踪需要在执行高准确性/高分辨率/高帧率检测之间进行慎重考虑,并保留足够的余量以支持嵌入的可扩展性。解决处理要求的一种方法是使用专用的人工智能加速器。如前所述,SoC的人工智能引擎可能会因为缺乏共享内存资源而受到限制。模型优化也可以用于降低处理要求,但可能会影响性能和/或准确性。
不要将系统级开销限制在AI性能上
在智能摄像机或边缘设备中,集成SoC(即主机处理器)获取视频帧并执行前述的预处理步骤。这些功能可以由SoC的CPU核心或GPU(如果有的话)执行,但也可以由SoC中的专用硬件加速器执行(例如,图像信号处理器)。完成这些预处理步骤后,集成到SoC中的AI加速器可以直接访问来自系统内存的量化输入,或者在离散AI加速器的情况下,输入随后通过USB或PCIe接口进行推理。
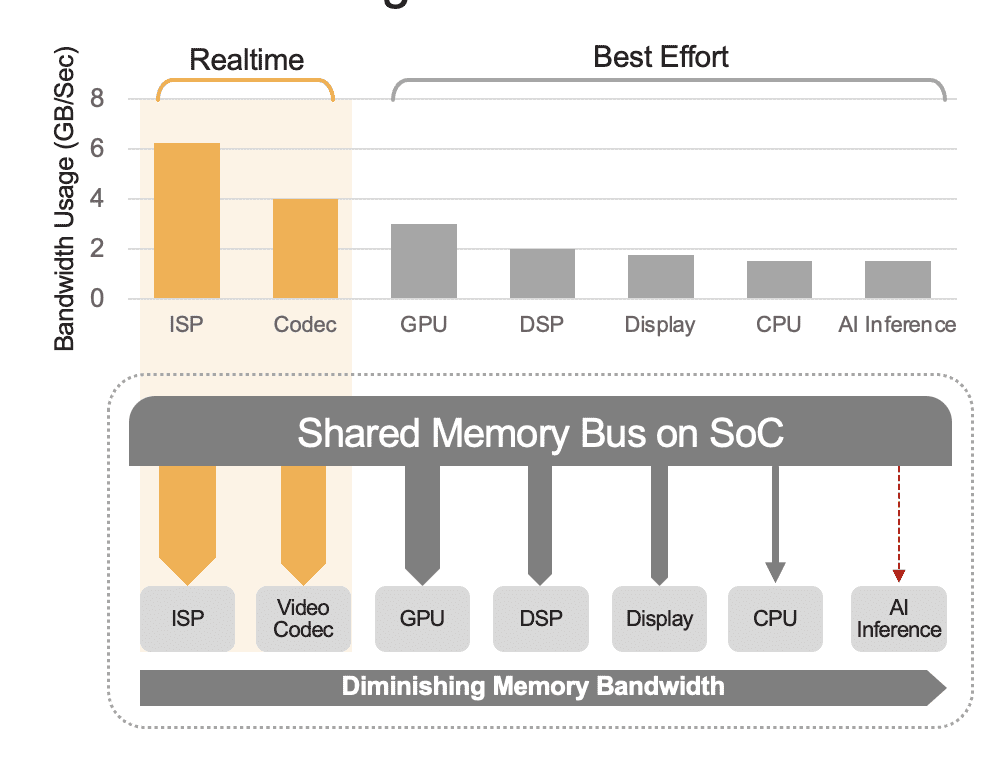
集成SoC可以包含一系列计算单元,包括CPU、GPU、AI加速器、视觉处理器、视频编码器/解码器、图像信号处理器(ISP)等。这些计算单元都共享同一内存总线,因此可以访问相同的内存。此外,CPU和GPU可能还必须在推理中发挥作用,而这些单元将忙于运行部署系统中的其他任务。这就是我们所说的系统级开销(图2)。
许多开发人员错误地评估了SoC中内置AI加速器的性能,而没有考虑到系统级开销对总体性能的影响。举个例子,考虑在一个集成了50 TOPS AI加速器的SoC上运行YOLO基准测试,可能会获得100个推理/秒(IPS)的基准结果。但在一个所有其他计算单元都处于活动状态的部署系统中,那50 TOPS可能会降低到约12 TOPS,并且整体性能只会产生25个IPS,假设有一个慷慨的25%利用率因子。如果平台持续处理视频流,系统开销总是一个因素。或者,使用离散的AI加速器(例如Kinara Ara-1、Hailo-8、Intel Myriad X),系统级利用率可能高于90%,因为一旦主机SoC启动推理功能并传输AI模型的输入数据,加速器将自主运行,利用其专用内存来访问模型权重和参数。
边缘视频分析需要低延迟
到目前为止,我们已经从每秒帧数和TOPS的角度讨论了AI的性能。但低延迟是交付系统实时响应能力的另一个重要要求。例如,在游戏中,低延迟对于无缝流畅的游戏体验至关重要,特别是在动作控制游戏和虚拟现实(VR)系统中。在自动驾驶系统中,低延迟对于实时对象检测、行人识别、车道检测和交通标志识别至关重要,以避免危及安全。自动驾驶系统通常要求从检测到实际操作的端到端延迟不超过150毫秒。同样,在制造业中,低延迟对于实时缺陷检测、异常识别和机器人引导依赖低延迟视频分析以确保高效运行和最小化生产停机时间。
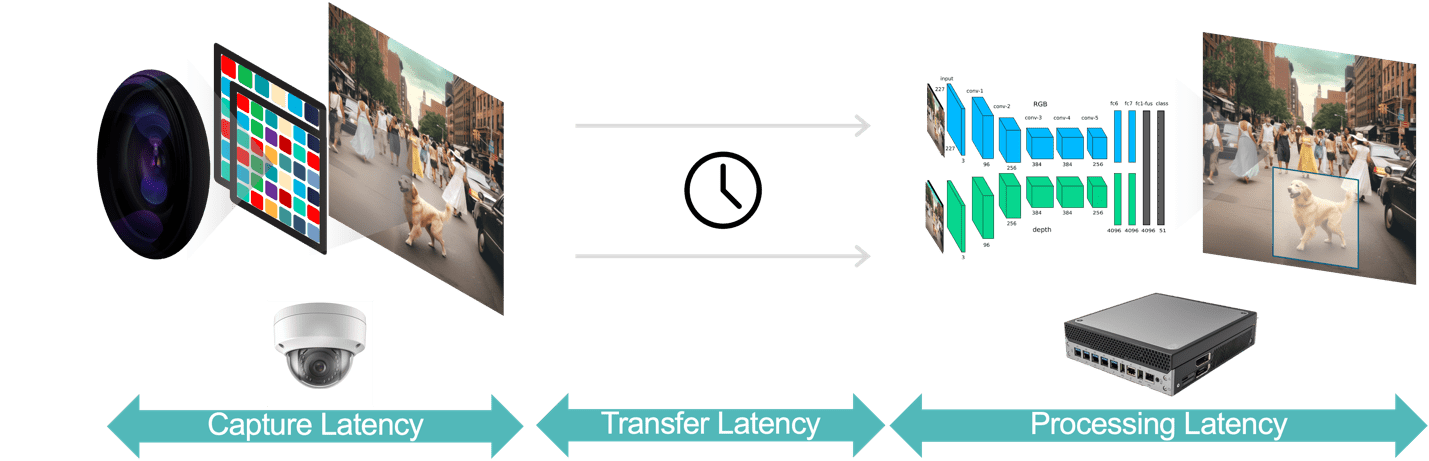
总的来说,视频分析应用中有三个延迟组成部分(图3):
- 数据捕获延迟是摄像机传感器捕获视频帧到帧可供分析系统处理的时间。您可以通过选择具有快速传感器和低延迟处理器的摄像机、选择最佳帧速率以及使用高效的视频压缩格式来优化此延迟。
- 数据传输延迟是捕获和压缩的视频数据从摄像机传输到边缘设备或本地服务器的时间。这包括在每个终点发生的网络处理延迟。
- 数据处理延迟是指边缘设备执行视频处理任务(例如帧解压缩和分析算法,如基于运动预测的物体跟踪、人脸识别)所需的时间。正如前面所指出的,对于必须针对每个视频帧运行多个AI模型的应用程序,处理延迟尤为重要。
使用专为最小化芯片内和计算与各级内存层次之间数据移动的架构的AI加速器可以优化数据处理延迟。此外,为了提高延迟和系统级效率,该架构必须支持模型之间的零(或接近零)切换时间,以更好地支持我们前面讨论的多模型应用程序。性能和延迟的另一个因素与算法灵活性有关。换句话说,某些架构仅针对特定的AI模型具有最佳行为,但随着AI环境的迅速变化,新的更高性能和更高准确性的模型似乎每天都在出现。因此,选择一个没有对模型拓扑、运算符和大小施加实际限制的边缘AI处理器。
在最大化边缘AI设备性能方面,需要考虑许多因素,包括性能和延迟要求以及系统开销。成功的策略应考虑使用外部AI加速器,以克服SoC的AI引擎在内存和性能方面的限制。 C.H. Chee 是一位杰出的产品营销和管理高管,他在半导体行业推广产品和解决方案方面拥有丰富的经验,重点关注基于视觉的AI、连接性和多个市场的视频接口。作为一名企业家,Chee共同创办了两家视频半导体初创公司,并被一家上市半导体公司收购。Chee领导产品营销团队,喜欢与专注于取得出色成果的小团队合作。





