数据分析的工作趋势:自然语言处理用于工作趋势分析
美妆时尚界的数据趋势:自然语言处理在工作趋势分析中的应用
由Mahantesh Pattadkal & Andrea De Mauro撰写
数据分析近年来取得了显著增长,这得益于数据在关键决策过程中的利用方式的进步。由于这些发展,数据的收集、存储和分析也取得了显著进展。此外,对数据分析人才的需求也急剧增加,将就业市场转变为对具备必要技能和经验的个人来说是一个竞争激烈的场所。
数据驱动技术的快速扩张相应地导致了对“数据工程师”等专门角色的需求增加。这种需求的激增不仅仅限于数据工程本身,还包括数据科学家和数据分析师等相关职位。
我们认识到这些职业的重要性,我们的博客系列旨在从在线招聘网站收集真实世界的数据,对其进行分析,以了解这些工作的需求性质,以及每个类别内所需要的多样化技能。
在本博客中,我们介绍了一个基于浏览器的“数据分析职位趋势”应用程序,用于可视化和分析数据分析市场的工作趋势。通过从在线招聘机构抓取数据,它使用自然语言处理技术来识别工作岗位所需的关键技能。图1显示了数据应用程序的快照,探索数据分析工作市场的趋势。

在实施方面,我们采用了低代码数据科学平台:KNIME Analytics Platform。这是一个基于可视化编程的开源免费数据科学平台,提供了广泛的功能,从纯ETL操作和广泛的数据源连接器用于数据融合到包括深度学习在内的机器学习算法。
应用程序的一系列工作流程可以免费从KNIME社区中心的“数据分析职位趋势”下载。这个基于浏览器的实例可以在“数据分析职位趋势”进行评估。
“数据分析职位趋势”应用程序
本应用程序由图2中显示的四个工作流程生成,按照以下步骤顺序执行:
- 进行数据收集的网络抓取
- 自然语言处理和数据清洗
- 主题建模
- 分析职位角色技能的归因
这些工作流程在KNIME社区中心 – “数据分析职位趋势”公共空间上可用。

- “01_网络数据抓取”工作流程遍历在线职位发布,并将文本信息提取到结构化格式
- “02_NLP解析和清洗”工作流程执行必要的清洗步骤,然后将长文本解析为较短的句子
- “03_主题建模和数据应用探索”使用清洗后的数据构建主题模型,并在数据应用中可视化其结果
- “04_职位技能归因”工作流程基于LDA结果评估不同职位角色(如数据科学家、数据工程师和数据分析师)的技能关联。
网络抓取数据收集
为了对就业市场所需的技能有最新的了解,我们选择分析来自在线招聘机构的网络抓取职位。考虑到区域差异和语言的多样性,我们重点关注美国的职位发布。这确保了大量职位发布是用英语呈现的。我们还关注了2023年2月至2023年4月的职位发布。
在图3中,KNIME工作流“01_网络爬虫用于数据收集”通过搜索工作中介网站的URL列表进行爬取。
为了提取与数据分析相关的工作岗位,我们使用了包括“大数据”、“数据科学”、“商业智能”、“数据挖掘”、“机器学习”和“数据分析”在内的六个关键词进行搜索。搜索关键词存储在Excel文件中,并通过Excel Reader节点读取。
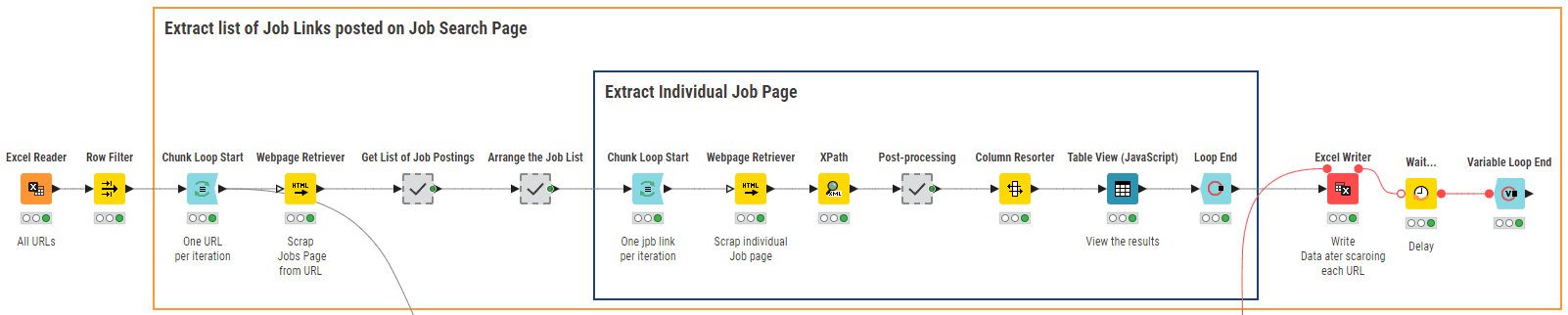
这个工作流程的核心节点是Webpage Retriever节点。该节点被使用了两次。第一次(外部循环),节点根据提供的关键词爬取该网站,并生成相关的工作岗位在过去24小时内发布的美国的URL列表。第二次(内部循环),节点从每个工作岗位的URL中检索文本内容。在Webpage Retriever节点后的XPath节点解析提取的文本,以获取所需的信息,如职位名称、要求的资格、工作描述、薪资和公司评级。最后,结果被写入一个本地文件以进行进一步的分析。图4展示了2023年2月爬取的工作岗位样本。

NLP解析和数据清洗
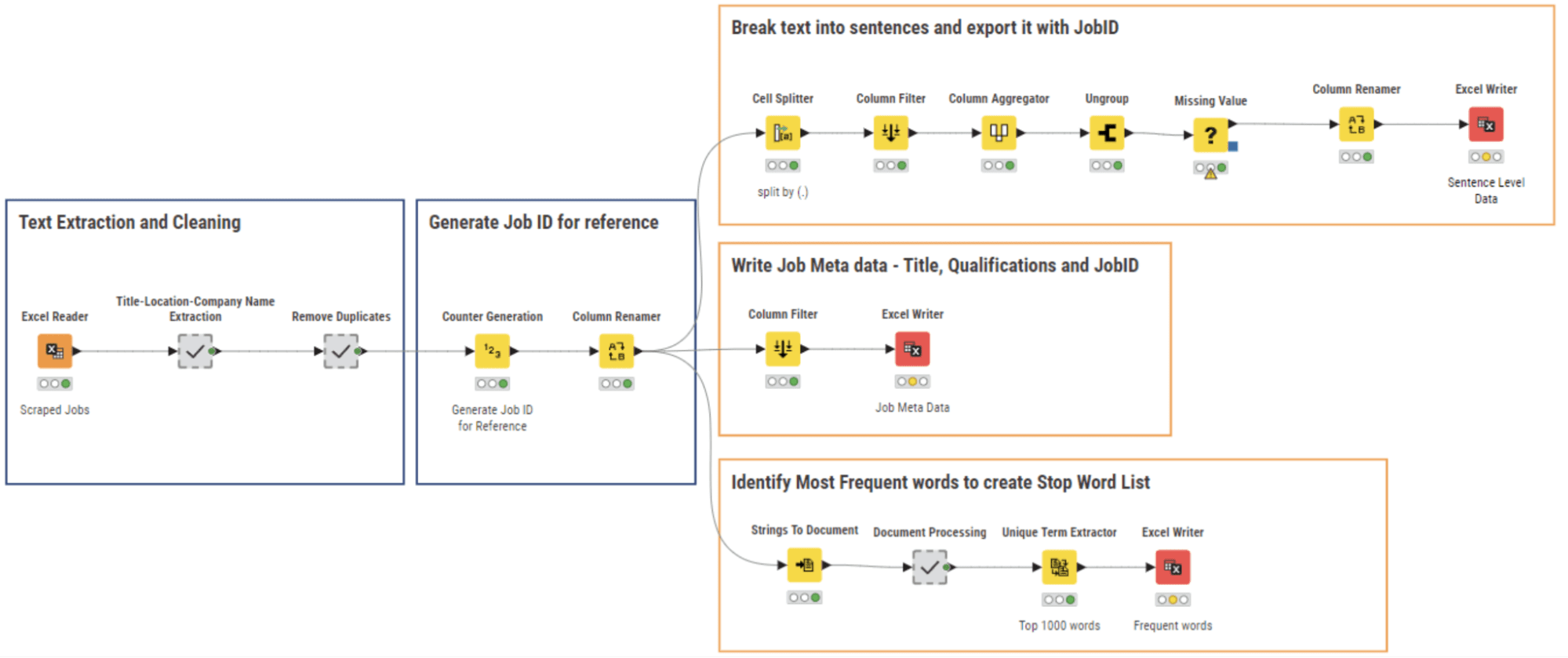
像所有刚刚收集的数据一样,我们的网络爬虫结果需要进行清洗。我们使用02_NLP解析和清洗工作流程(图5)进行NLP解析和数据清洗,并将相关的数据文件写入。
从爬取的数据中,多个字段已被保存为字符串值的连接。在这里,我们使用一系列的字符串操作节点在元节点“标题-地点-公司名称提取”中提取了各个部分,然后删除了不必要的列并清除了重复行。
然后,我们为每个工作岗位文本分配了唯一的ID,并使用Cell Splitter节点将整个文档分割成句子。每个工作的元信息 – 职位、地点和公司 – 也被提取并与工作ID一起保存。
从所有文档中提取了出现频率前1000个单词的列表,以生成停用词列表,包括诸如“申请人”、“合作”、“就业”等等。这些词语出现在每个工作岗位中,因此对于下一步的NLP任务没有添加任何信息。
这个清洗阶段的结果是三个文件集:
– 包含文档句子的表格;
– 包含工作描述元数据的表格;
– 包含停用词列表的表格。
主题建模和结果探索
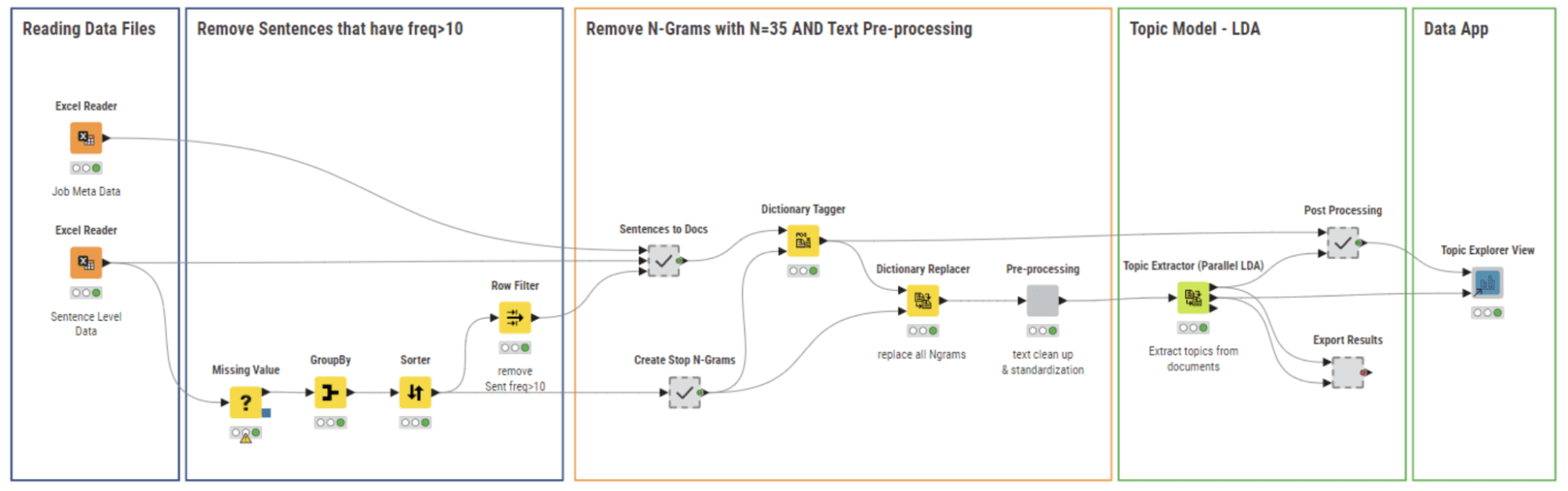
工作流程03_主题建模和探索数据应用(图6)使用前一个工作流程中的清洗数据文件。在这个阶段,我们的目标是:
- 检测和删除出现在许多工作岗位中的常见句子(停止短语)
- 执行标准文本处理步骤,准备数据进行主题建模
- 构建主题模型并可视化结果
我们在以下子部分中详细讨论上述任务。
3.1 用N-gram删除停用词短语
许多职位发布中包含公司政策或普通协议中常见的句子,比如“非歧视政策”或“非揭露协议”。图7提供了一个例子,职位发布1和2提到了“非歧视”政策。这些句子与我们的分析无关,因此需要从我们的文本语料库中删除。我们将它们称为“停用短语”,并使用两种方法来识别和过滤它们。
第一种方法很简单:我们计算语料库中每个句子的频率,并消除频率大于10的句子。
第二种方法涉及到N-gram方法,其中N的值可以在20到40的范围内选择。我们选择一个N的值,并通过计算分类为停用短语的N-gram的数量来评估这些来自语料库的N-gram的相关性。我们在范围内为每个N的值重复这个过程。我们选择N=35作为识别最多停用短语的最佳N值。

我们使用这两种方法来删除“停用短语”,如图7所示的工作流程。首先,我们删除最常见的句子,然后我们创建N=35的N-gram,并在每个文档中使用Dictionary Tagger节点对它们进行标记,最后,我们使用Dictionary Replacer节点删除这些N-gram。
3.2 用文本预处理技术准备数据进行主题建模
在删除停用短语之后,我们进行标准的文本预处理以准备数据进行主题建模。
首先,我们从语料库中排除数值和字母数字值。然后,我们删除标点符号和常见的英文停用词。此外,我们使用之前创建的自定义停用词列表过滤掉特定于工作领域的停用词。最后,我们将所有字符转换为小写。
我们决定将重点放在携带重要意义的词语上,因此我们过滤掉只含有名词和动词的文档。这可以通过为文档中的每个词语分配词性标记来实现。我们使用POS Tagger节点来分配这些标记,并根据它们的值进行过滤,特别保留词性为名词和动词的词语。
最后,我们应用斯坦福词形还原算法,确保语料库准备好进行主题建模。所有这些预处理步骤由图6中的“预处理”组件执行。
3.3 建立主题模型并进行可视化
在我们的实施的最后阶段,我们使用图6中的Topic Extractor (Parallel LDA)节点应用隐含狄利克雷分布(LDA)算法来构建主题模型。LDA算法生成一定数量的主题(k),每个主题通过一定数量的关键词(m)进行描述。参数(k,m)必须定义。
顺便提一句,k和m不能太大,因为我们希望通过查看关键词(技能)及其相应权重来对主题(技能组)进行可视化和解释。我们探索了k在[1, 10]范围内的取值,并固定m的值为15。经过仔细分析,我们发现k=7可以得到最多样化和独特的主题,关键词之间有最小的重叠。因此,我们确定k=7为我们分析的最佳值。
通过交互式数据应用程序探索主题建模结果
为了使每个人都可以访问主题建模结果和自行尝试,我们将工作流程(如图6所示)部署为一个数据应用程序在KNIME Business Hub上,并公开访问。你可以在这里查看:数据分析工作趋势。
这个数据应用的视觉部分来自于 Francesco Tuscolano和 Paolo Tamagnini开发的Topic Explorer View组件,可以从KNIME社区中心免费下载,提供了许多关于主题和文档的交互式可视化。
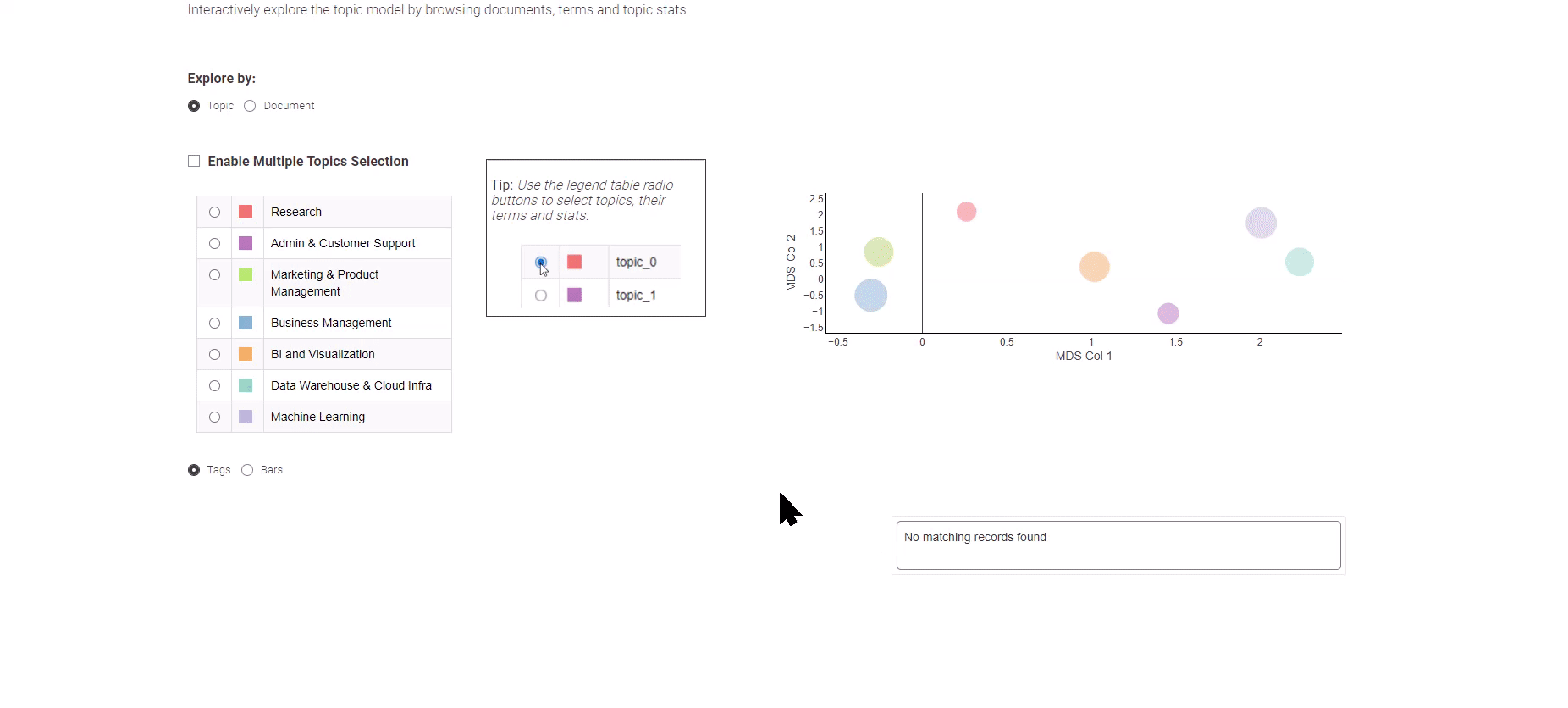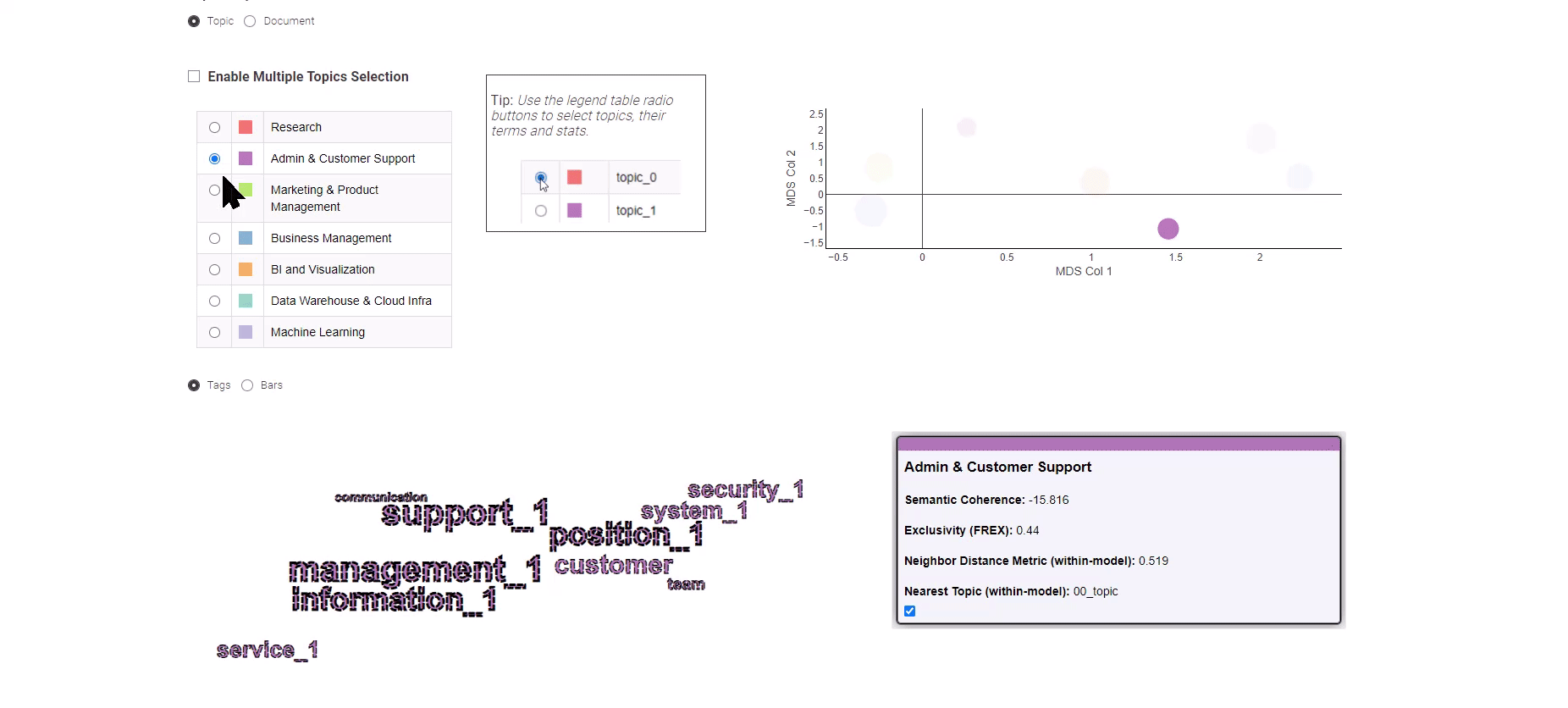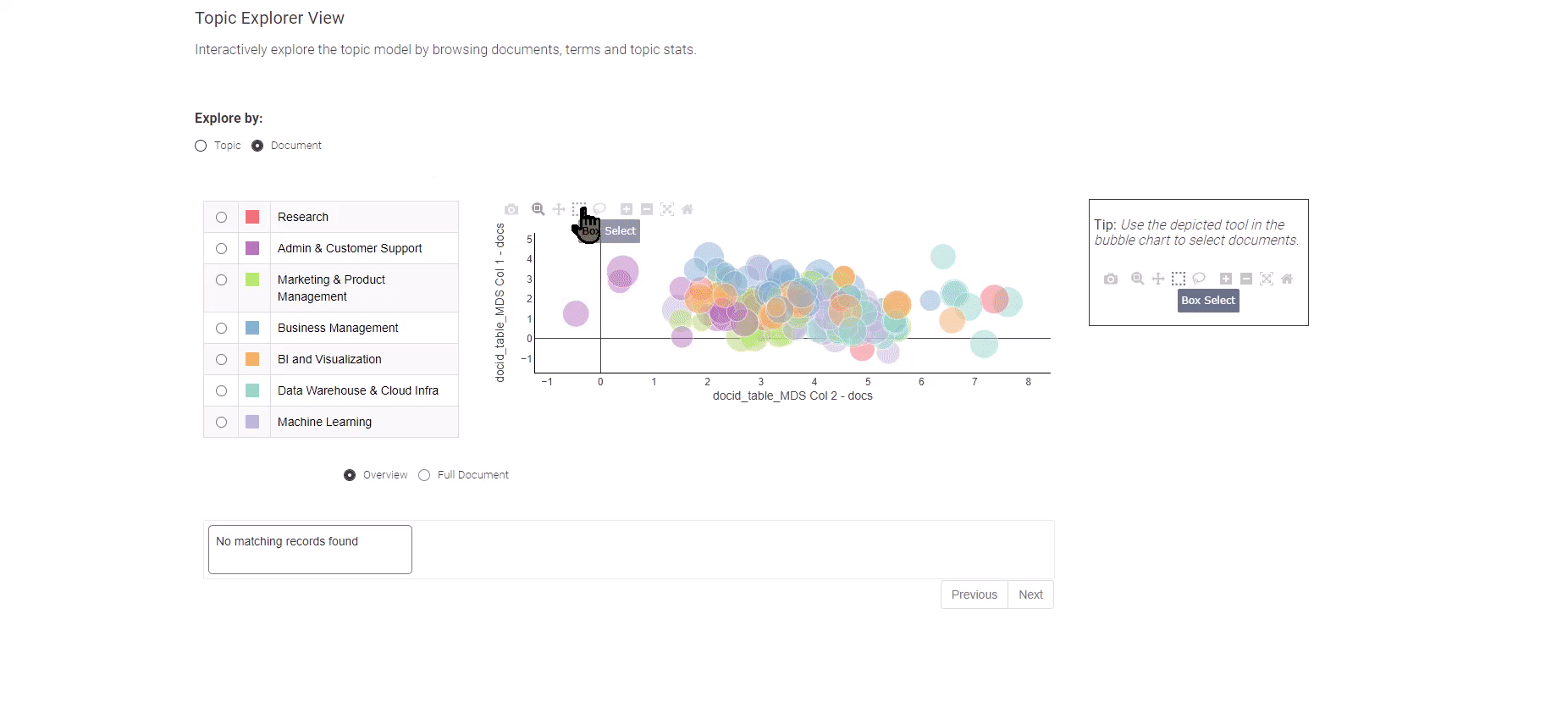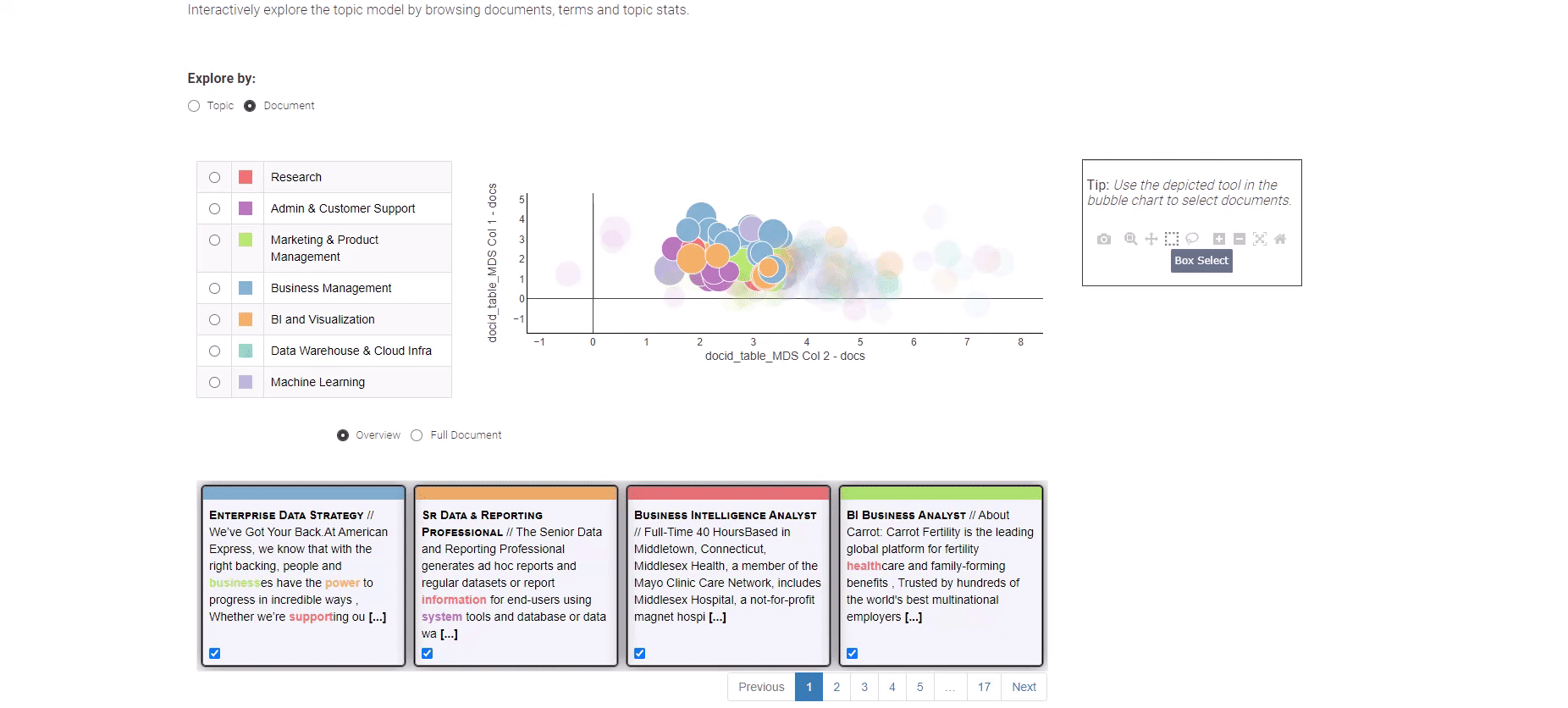 图8:用于探索主题建模结果的数据分析工作趋势
图8:用于探索主题建模结果的数据分析工作趋势
如图8所示,这个数据应用提供了两种不同的视图选择:主题视图和文档视图。
“主题”视图使用多维缩放算法将主题以二维图形方式展示,有效地揭示它们之间的语义关系。在左侧面板上,您可以方便地选择一个感兴趣的主题,并显示其对应的关键字。
如果想要深入探索个别工作职位,只需选择“文档”视图。文档视图以简洁的方式展示了所有文档在两个维度上的情况。您可以使用方框选择方法来定位重要的文档,并在底部提供所选文档的概览。
使用NLP探索数据分析工作市场
我们在这里提供了“数据分析工作趋势”应用程序的摘要。该应用程序用于探索数据科学领域中最新的技能需求和工作角色。在本博客中,我们将重点关注美国的英语职位描述,时间范围是2023年2月至4月。
为了了解工作趋势并提供回顾,“数据分析工作趋势”会爬取工作代理网站,提取在线职位发布的文本,进行一系列的NLP任务来提取主题和关键字,并通过主题和文档来展示结果,以识别数据中的模式。
该应用程序由一套四个KNIME工作流程组成,按顺序运行以进行网络抓取、数据处理、主题建模,然后进行交互式可视化,用户可以发现工作趋势。
我们将工作流程部署在KNIME Business Hub上,并公开发布,以便每个人都可以访问。您可以在以下网址查看:数据分析工作趋势。
完整的工作流程集可从KNIME社区中心免费下载,以便根据其他职位市场领域的需求进行更改和适应。只需更改Excel文件中的搜索关键字列表、网站和搜索的时间范围即可。
那么结果如何呢?在今天的数据科学职位市场上,哪些技能和专业角色最受追捧?在我们的下一篇博客文章中,我们将带您深入探索这个主题模型的结果。我们将密切审视工作角色和技能之间的有趣相互作用,并获得有关数据科学职位市场的有价值的见解。请继续关注我们令人激动的探索!
资源
- 数据分析工作需求和在线课程的系统性综述 by A. Mauro et al.
Mahantesh Pattadkal在数据科学项目和产品咨询方面拥有超过6年的经验。他拥有数据科学硕士学位,他在深度学习、自然语言处理和可解释机器学习方面拥有专业知识。此外,他还积极参与KNIME社区,与他人合作进行基于数据科学的项目。
Andrea De Mauro拥有超过15年在跨国公司(如宝洁和沃达丰)建立业务分析和数据科学团队的经验。除了在公司的角色外,他还喜欢在意大利和瑞士的几所大学教授市场分析和应用机器学习。通过他的研究和写作,他探索了数据和人工智能的商业和社会影响,并确信更广泛的分析素养将使世界变得更好。他最新的书籍是由Packt出版的《轻松掌握数据分析》。他出现在CDO杂志2022年全球“40岁以下40人”名单中。






