揭示隐藏的模式:层次聚类简介
揭开隐藏的模式:层次聚类简介
当你熟悉无监督学习范式时,你会了解到聚类算法。
聚类的目标通常是理解给定未标记数据集中的模式。或者可以是找到数据集中的群组,并对其进行标记,以便我们可以在现在标记的数据集上执行监督学习。本文将介绍层次聚类的基础知识。
什么是层次聚类?
层次聚类算法旨在找到实例之间的相似性(由距离度量量化),并将它们分组成称为簇(clusters)的分段。
该算法的目标是找到这样的簇,使得一个簇中的数据点相互之间的相似性大于与其他簇中的数据点的相似性。
有两种常见的层次聚类算法,每种算法都有自己的方法:
- 凝聚式聚类
- 分割式聚类
凝聚式聚类
假设数据集中有n个不同的数据点。凝聚式聚类的工作原理如下:
- 从n个簇开始;每个数据点本身就是一个簇。
- 基于它们之间的相似性,将数据点合并成组。意思是相似的簇会根据距离进行合并。
- 重复步骤2,直到只剩下一个簇。
分割式聚类
与凝聚式聚类相反,分割式聚类试图执行以下操作:
- 所有n个数据点都在一个单独的簇中。
- 将这个单独的大簇划分为更小的群组。注意,凝聚式聚类中的数据点聚合基于相似性。但将它们分割为不同的簇基于不相似性;不同簇中的数据点之间是不相似的。
- 重复直到每个数据点本身都成为一个簇。
距离度量
如前所述,数据点之间的相似性是使用距离来量化的。常用的距离度量包括欧氏距离和曼哈顿距离。
对于特征空间中的任意两个数据点,它们之间的欧氏距离表示为:
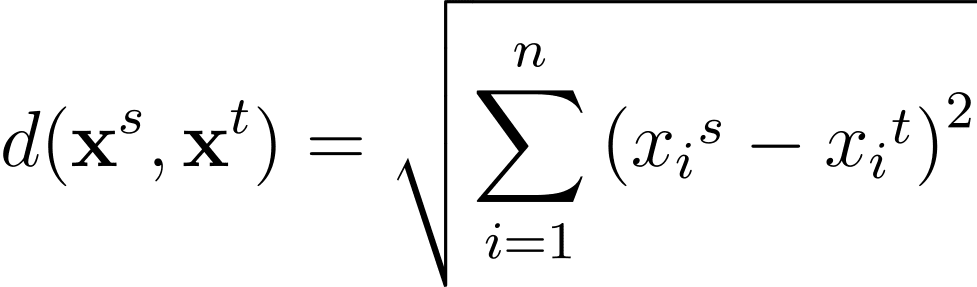
另一个常用的距离度量是曼哈顿距离,表示为:
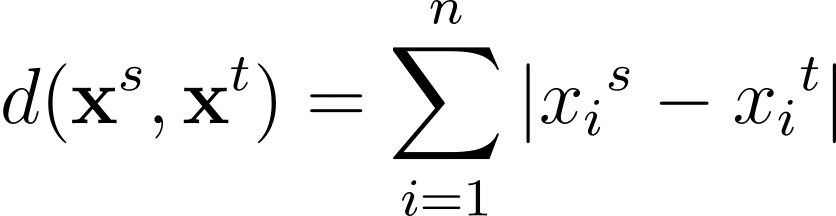
闵可夫斯基距离是这些距离度量在n维空间中的一个泛化形式,其中p>=1:
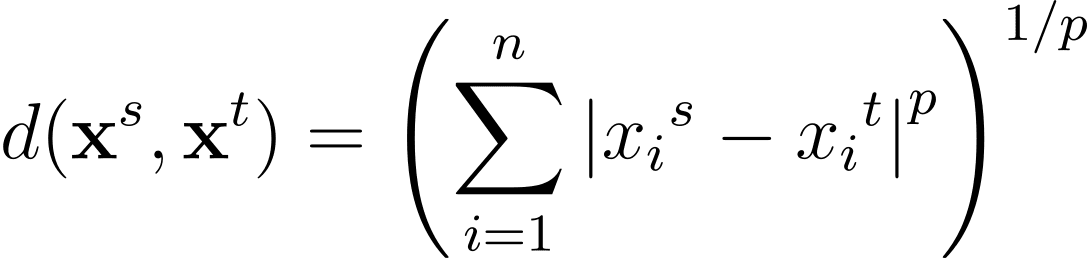
簇间距离:理解连接准则
使用距离度量,我们可以计算数据集中任意两个数据点之间的距离。但您还需要定义一个距离来确定在每一步中如何“如何”将簇组合在一起。
请记住,在凝聚式聚类的每一步中,我们选择最接近的两个群组进行合并。这由连接准则捕捉到。常用的连接准则包括:
- 单链接
- 完全链接
- 平均链接
- Ward链接
单链接
在单链接或单连接聚类中,两个群组/簇之间的距离被认为是这两个簇中所有数据点对之间的最小距离。
完全连接
在完全连接或完全连接聚类中,两个聚类之间的距离被选择为两个聚类中所有点对之间的最大距离。
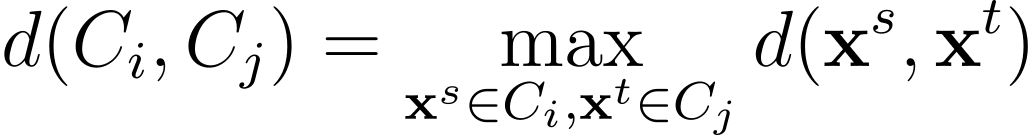
平均连接
有时会使用平均连接,它使用两个聚类中所有数据点之间距离的平均值。
Ward’s连接
Ward连接旨在减小合并的聚类内的方差:合并后聚类的方差应该最小化。这导致了更紧密和分离良好的聚类。
通过考虑合并聚类的均值之间总方差增加来计算两个聚类之间的距离。思想是测量合并聚类的方差相对于合并之前各个聚类的方差增加了多少。
当我们在Python中编码分层聚类时,我们也将使用Ward连接。
什么是树状图?
我们可以将聚类的结果可视化为树状图。它是一个帮助我们理解数据点及其后聚类如何根据算法的执行过程进行分组或合并的分层树状结构。
在分层树状结构中,叶子表示数据集中的实例或数据点。从y轴可以推断出发生合并或分组的相应距离。
由于连接类型决定了数据点如何被分组在一起,不同的连接准则会产生不同的树状图。
根据距离,我们可以使用树状图-在特定点上切割或分割它-得到所需的聚类数。
与一些聚类算法(例如K-Means聚类)不同,分层聚类不需要在先指定聚类数。然而,使用聚合聚类处理大型数据集可能会带来很高的计算开销。
使用SciPy在Python中进行分层聚类
接下来,我们将一步一步地对内置的葡萄酒数据集进行分层聚类。为此,我们将利用从SciPy导入的聚类包-scipy.cluster。
第1步-导入所需的库
首先,让我们从库scikit-learn和SciPy中导入所需的库和模块:
# importsimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.datasets import load_winefrom sklearn.preprocessing import MinMaxScalerfrom scipy.cluster.hierarchy import dendrogram, linkage
第2步-加载和预处理数据集
接下来,我们将葡萄酒数据集加载到pandas数据框中。它是一个简单的数据集,是scikit-learn的datasets的一部分,有助于探索分层聚类。
# Load the datasetdata = load_wine()X = data.data# Convert to DataFramewine_df = pd.DataFrame(X, columns=data.feature_names)
让我们检查数据框的前几行:
wine_df.head()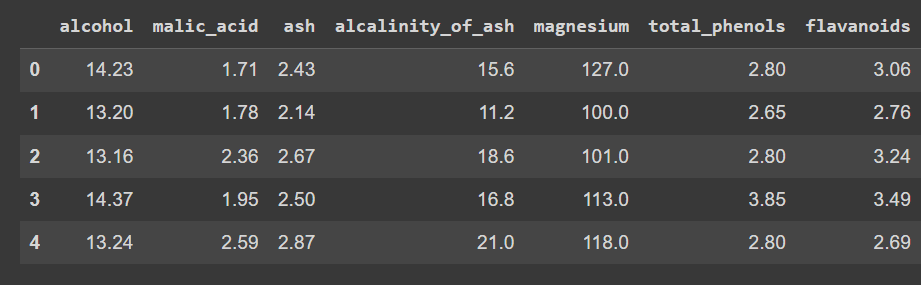 截断的wine_df.head()输出
截断的wine_df.head()输出
请注意,我们只加载了特征,而没有加载输出标签,这样我们就可以对数据集进行聚类,发现其中的群组。
让我们来检查数据框的形状:
print(wine_df.shape)数据集中有178条记录和14个特征:
输出 >>> (178, 14)由于数据集中包含分布在不同范围内的数字值,让我们对数据集进行预处理。我们将使用MinMaxScaler将每个特征转换为取值范围在[0, 1]之间的值。
# 使用MinMaxScaler对特征进行缩放scaler = MinMaxScaler()X_scaled = scaler.fit_transform(X)步骤3 – 进行层次聚类并绘制树状图
让我们计算连接矩阵、进行聚类并绘制树状图。我们可以使用层次聚类模块中的linkage函数基于Ward’s linkage(将method设置为’ward’)来计算连接矩阵。
如前所述,Ward’s linkage最小化每个聚类内的方差。然后,我们绘制树状图来可视化层次聚类过程。
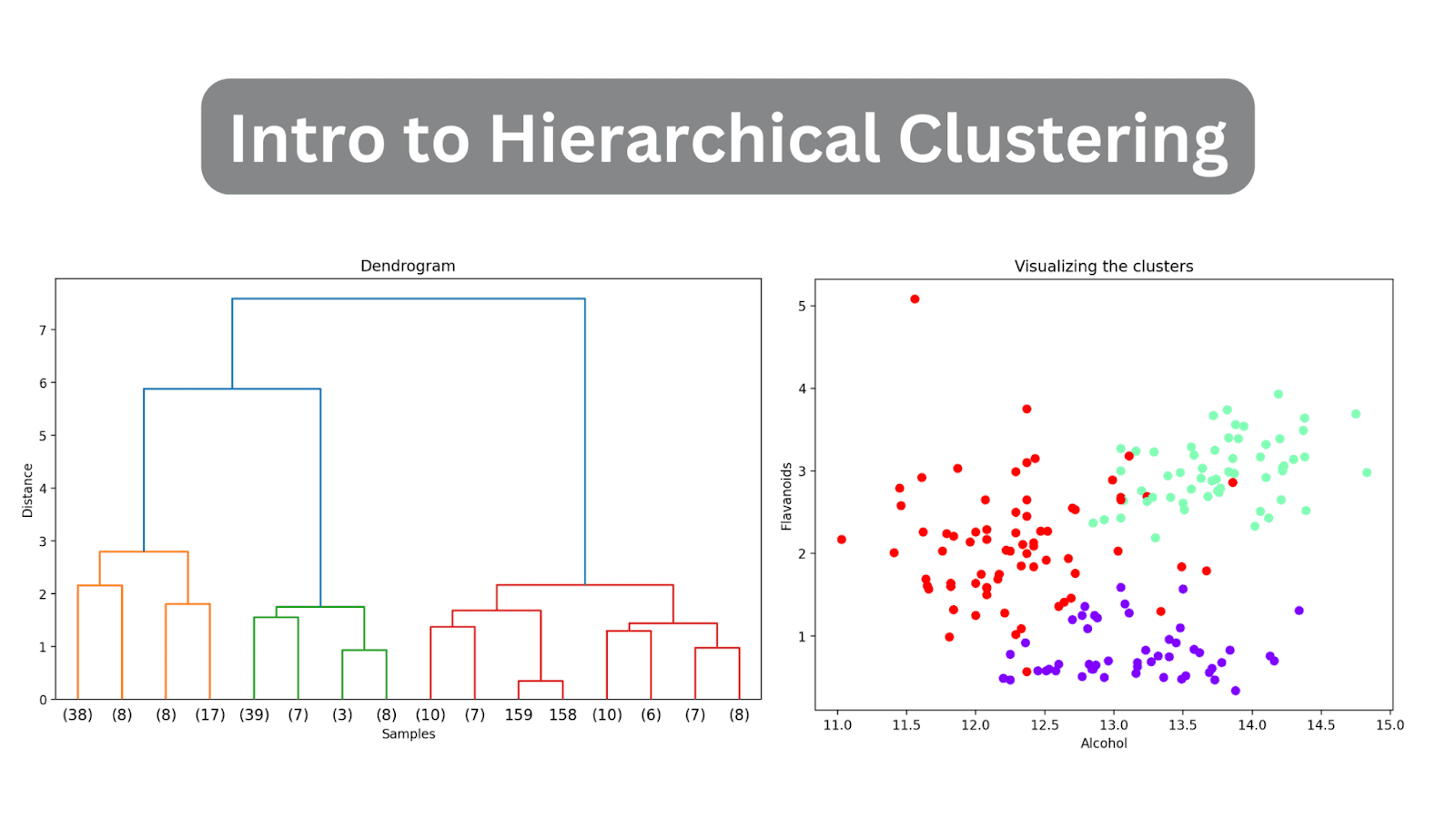
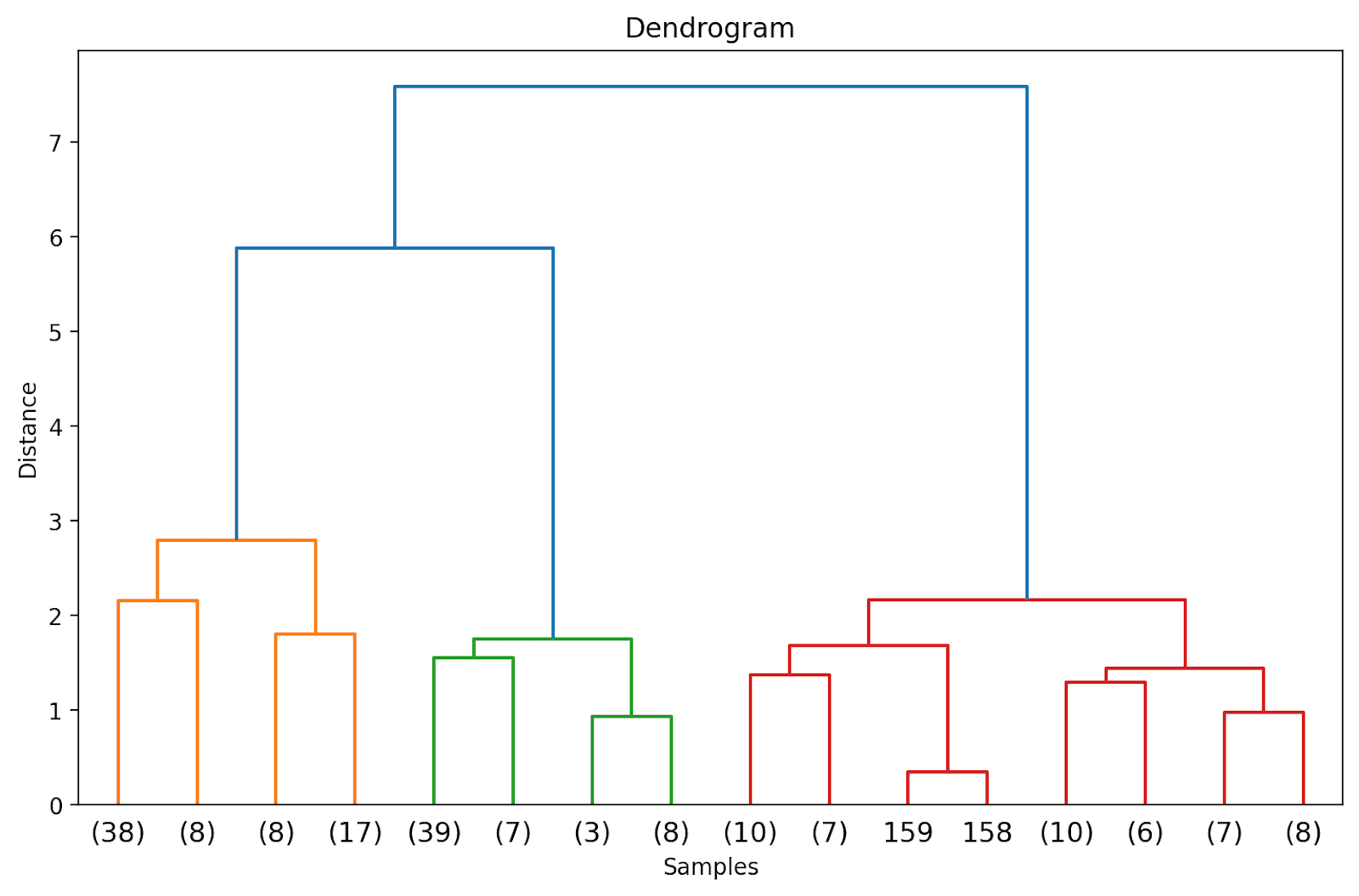
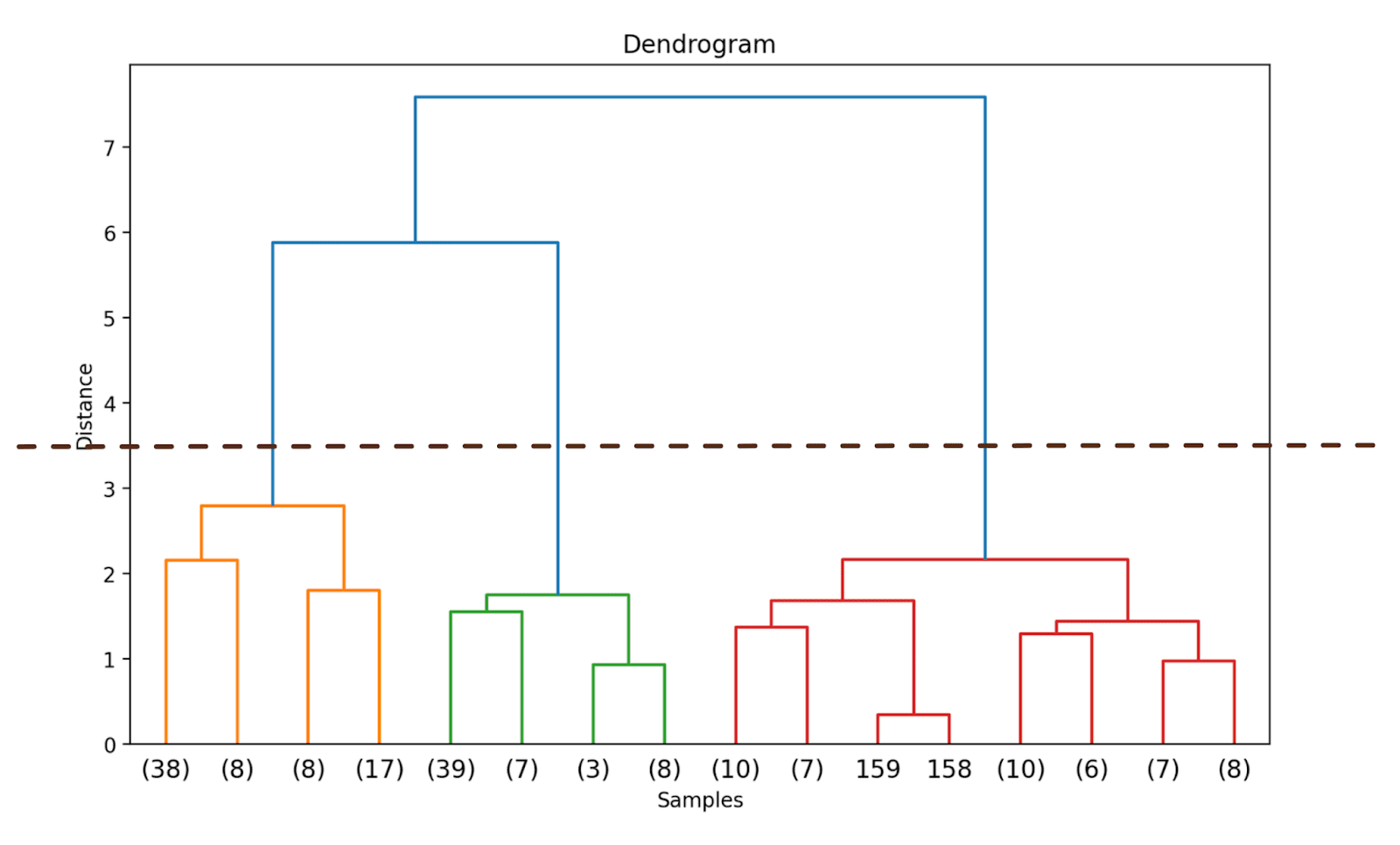
# 计算连接矩阵linked = linkage(X_scaled, method='ward')# 绘制树状图plt.figure(figsize=(10, 6), dpi=200)dendrogram(linked, orientation='top', distance_sort='descending', show_leaf_counts=True)plt.title('树状图')plt.xlabel('样本')plt.ylabel('距离')plt.show()因为我们还没有截断树状图,所以我们可以看到如何将178个数据点组合成一个单一的聚类。尽管这似乎很难解释,但我们仍然可以看到有三个不同的聚类。
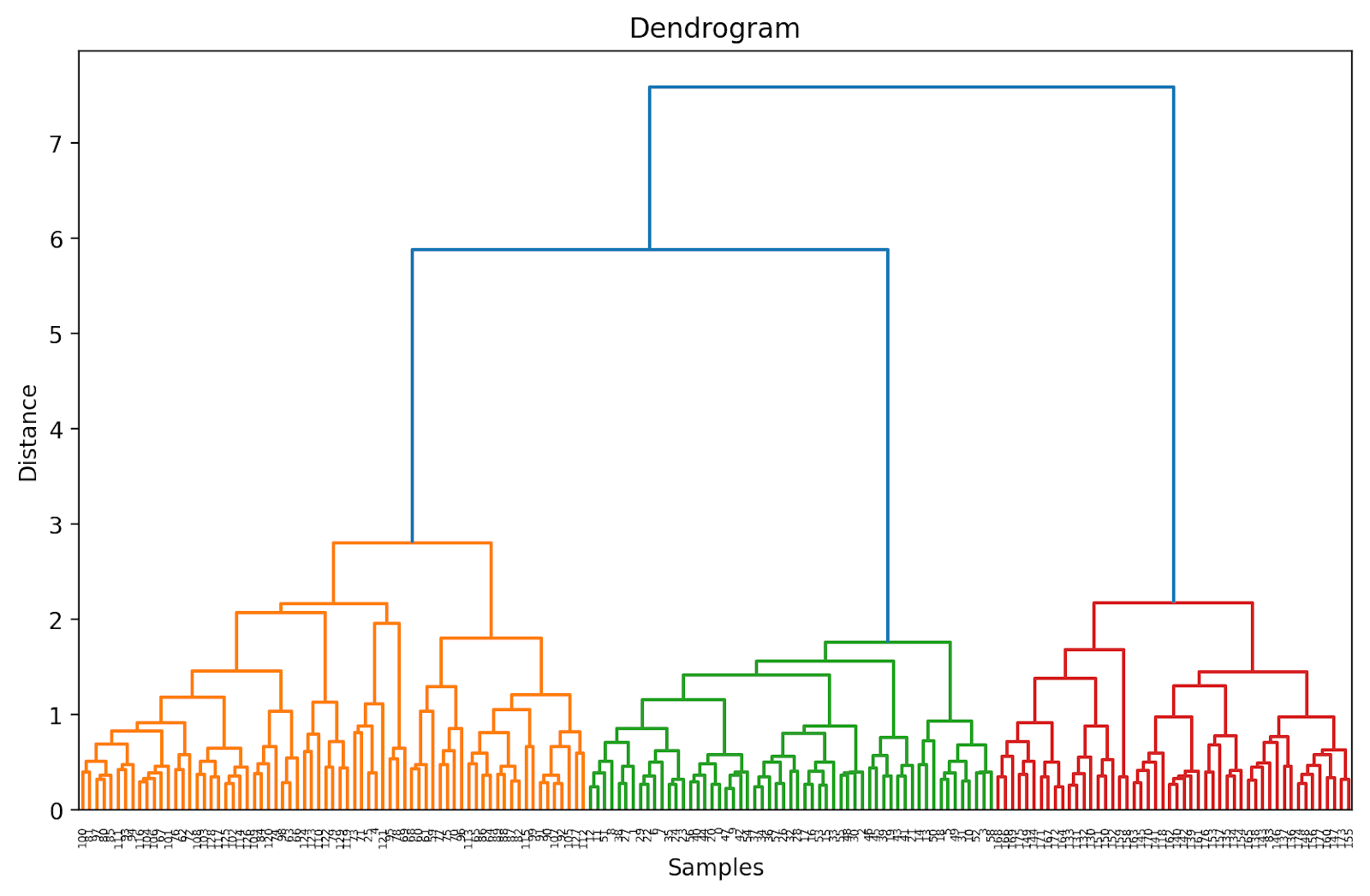
截断树状图以便更易于理解
实际上,我们可以可视化一个截断版本的树状图,这样更易于解释和理解。
要截断树状图,我们可以将truncate_mode设置为’level’,p = 3。
# 计算连接矩阵linked = linkage(X_scaled, method='ward')# 绘制树状图plt.figure(figsize=(10, 6), dpi=200)dendrogram(linked, orientation='top', distance_sort='descending', truncate_mode='level', p=3, show_leaf_counts=True)plt.title('树状图')plt.xlabel('样本')plt.ylabel('距离')plt.show()这样做将截断树状图,只包括那些在最终合并之前3层内的聚类。
在上面的树状图中,你可以看到一些数据点如158和159都是单独表示的。而其他一些数据点都被放在括号中;这些不是单独的数据点,而是一个聚类中的数据点个数。(k)表示具有k个样本的聚类。
步骤4 – 确定最佳聚类数量
树状图帮助我们选择最佳聚类数量。
我们可以观察沿着y轴的距离何时急剧增加,选择在那一点截断树状图,并将距离作为阈值来形成聚类。
对于这个例子,最佳聚类数量为3。
第5步 – 形成聚类
一旦我们确定了最佳聚类数,我们可以使用相应的纵坐标上的距离(阈值距离)。这确保在阈值距离之上,聚类不再合并。我们选择一个threshold_distance为3.5(从树状图中推断得出)。
然后我们使用fcluster,将criterion设置为“distance”来获取所有数据点的聚类分配:
from scipy.cluster.hierarchy import fcluster# 根据树状图选择一个阈值距离threshold_distance = 3.5 # 切割树状图以获取聚类标签cluster_labels = fcluster(linked, threshold_distance, criterion='distance')# 将聚类标签分配给DataFramewine_df['cluster'] = cluster_labels
现在您应该能够看到所有数据点的聚类标签(其中之一为{1, 2, 3}):
print(wine_df['cluster'])
输出 >>>0 21 22 23 24 3 ..173 1174 1175 1176 1177 1Name: cluster, Length: 178, dtype: int32
第6步 – 可视化聚类
现在每个数据点都被分配到一个聚类中,您可以可视化一部分特征及其聚类分配。这是两个特征的散点图以及它们的聚类映射:
plt.figure(figsize=(8, 6))scatter = plt.scatter(wine_df['alcohol'], wine_df['flavanoids'], c=wine_df['cluster'], cmap='rainbow')plt.xlabel('酒精')plt.ylabel('黄酮类化合物')plt.title('可视化聚类')# 添加图例legend_labels = [f'聚类{i + 1}' for i in range(n_clusters)]plt.legend(handles=scatter.legend_elements()[0], labels=legend_labels)plt.show() 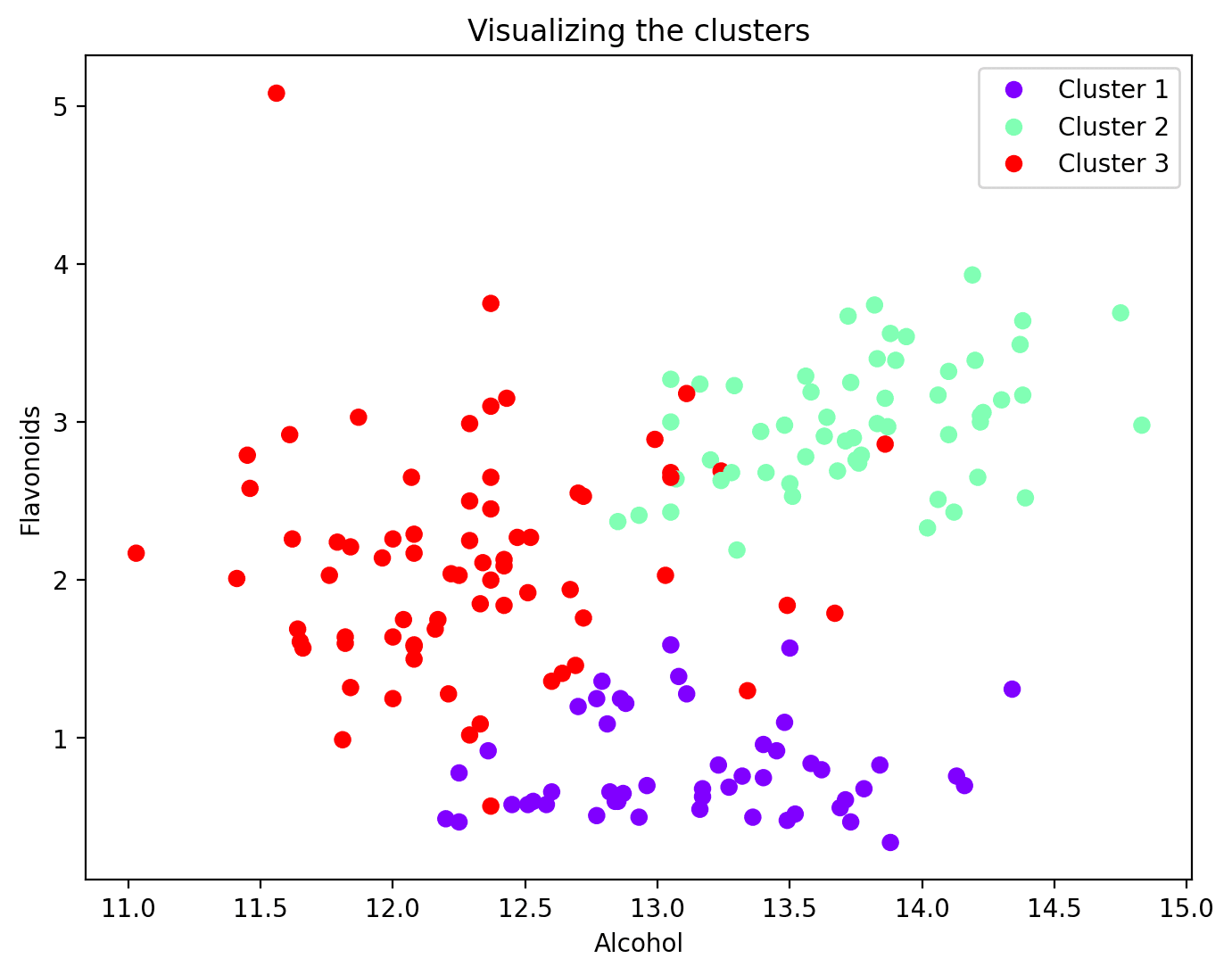
总结
就这样!在本教程中,我们使用SciPy执行层次聚类,以便更详细地介绍其中的步骤。另外,您还可以使用scikit-learn的聚类模块中的AgglomerativeClustering类。愉快地编码聚类!
参考资料
[1] 机器学习简介
[2] 统计学习简介 Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉领域工作。她感兴趣和熟悉的领域包括DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过撰写教程、指南、观点文章等,向开发者社区学习和分享她的知识。





