塑造自信的追求:你能相信一个黑匣子吗?
打造自信追求你能相信一件化妆品吗?

大型语言模型(LLMs)如GPT-4和LLaMA2已经进入了“数据标注”讨论。LLMs已经取得了长足的进步,现在可以对数据进行标注,并承担起人类历史上进行的任务。尽管用LLM获得数据标签非常快速且相对便宜,但仍然存在一个重大问题,即这些模型是终极的黑匣子。所以令人困扰的问题是:我们应该对LLM生成的标签有多少信任?在今天的文章中,我们将解决这个难题,建立一些基本准则,以评估我们对LLM标记数据的信心。
背景
下面所呈现的结果来自Toloka进行的一个使用流行模型和土耳其数据集的实验。这不是一个科学报告,而是对问题可能的解决方法和一些如何确定哪种方法最适合您的应用程序的建议的简要概述。
重要问题
在我们深入细节之前,让我们先来看看一个重要的问题:我们何时才能相信由LLM生成的标签,何时应保持怀疑态度?了解这一点可以帮助我们进行自动数据标注,并在其他应用任务中也是有用的,比如客户支持、内容生成等等。
目前的现状
那么,人们现在是如何解决这个问题的呢?有些人直接要求模型输出一个置信度分数,有些人查看模型在多次运行中答案的一致性,而其他人则检查模型的对数概率。但是这些方法中是否有可靠的方法?让我们来看看。
经验法则
什么使一个“好”的置信度测量方式?一个简单的经验法则是置信度分数与标签的准确性之间应该存在正相关关系。换句话说,较高的置信度分数应表示正确的可能性较高。您可以使用校准图来可视化这种关系,其中X轴和Y轴分别表示置信度和准确性。
实验及其结果
方法1:自信
自信方法涉及直接询问模型关于其自信的程度。猜猜怎么样?结果还不错!虽然我们测试的LLMs在非英文数据集方面存在问题,但自报自家的自信度与实际准确性之间的相关性非常明显,这意味着模型很清楚自己的局限性。对于GPT-3.5和GPT-4,我们在这方面得到了类似的结果。
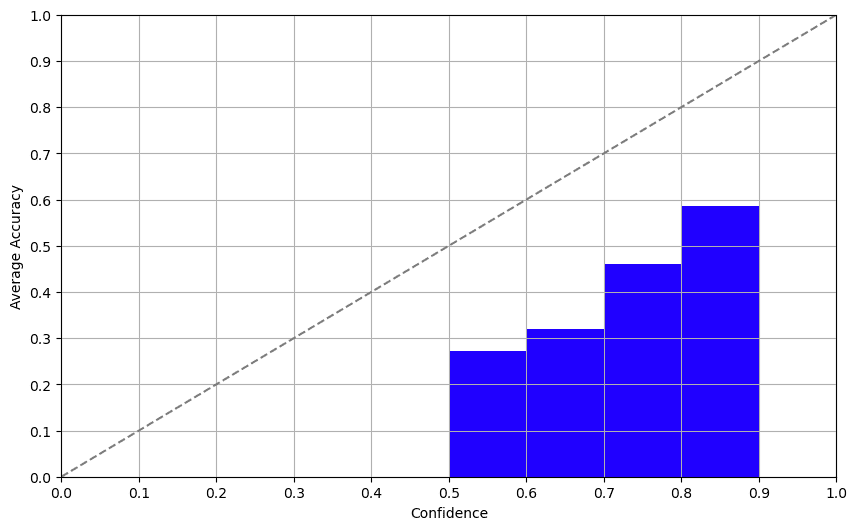
方法2:一致性
设置高温度(~0.7-1.0),多次标记同样的项目,并分析回答的一致性,更多细节请参阅这篇论文。我们用GPT-3.5尝试过这个方法,结果糟糕透了。我们让模型多次回答同一个问题,结果一直是不稳定的。这种方法就像向“8号球”询问人生建议一样靠不住,不应该信任。
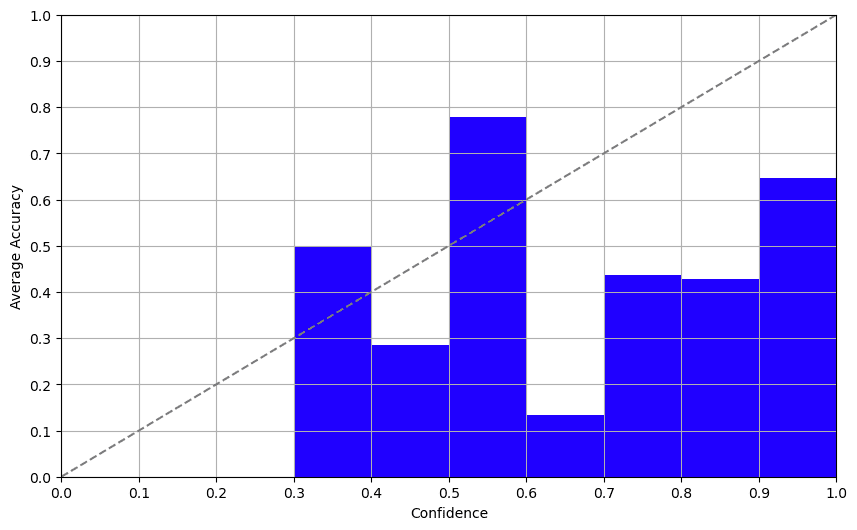
方法3:对数概率
对数概率带来了惊喜。Davinci-003返回完成模式下令牌的对数概率。通过检查这个输出,我们得到了一个令人惊讶的可信度分数,与准确性之间的相关性很好。这种方法提供了一种可靠的可信度分数确定方法。
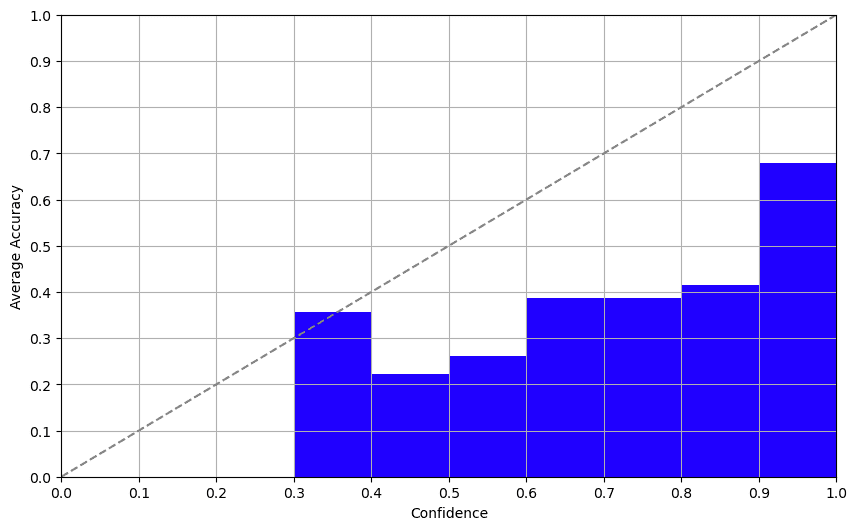
重点
那么,我们学到了什么?毫不掩饰地说:
- 自信:有用,但要小心处理。偏见被广泛报道。
- 一致性:不要试图坚持一致。除非你喜欢混乱。
- 对数概率:如果模型允许你访问它们,那是一个出人意料地好的选择。
令人兴奋的是,即使在没有对模型进行微调的情况下,对数概率似乎也相当稳健,尽管这篇论文报道该方法过于自信。还有进一步探索的空间。
未来方向
一个逻辑上的下一步可能是找到一个黄金公式,将这三种方法的最佳部分结合起来,或者探索新的方法。所以,如果你准备迎接挑战,这可能是你的下一个周末项目!
总结
好了,机器学习爱好者和新手们,就到这里吧。记住,无论你是在进行数据标注还是构建下一个大型对话代理 – 理解模型的置信度是关键。不要一味相信这些置信度得分,一定要做好你的功课!
希望你觉得这篇文章有启发。下次见,继续研究数字,质疑这些模型吧。 Ivan Yamshchikov是维尔茨堡-施韦因富特应用科学技术大学的语义数据处理和认知计算教授。他还领导Toloka AI的数据倡导团队。他的研究兴趣包括计算创造力、语义数据处理和生成模型。






