7个掌握数据清洗和预处理技术的步骤
7步数据清洗和预处理技术
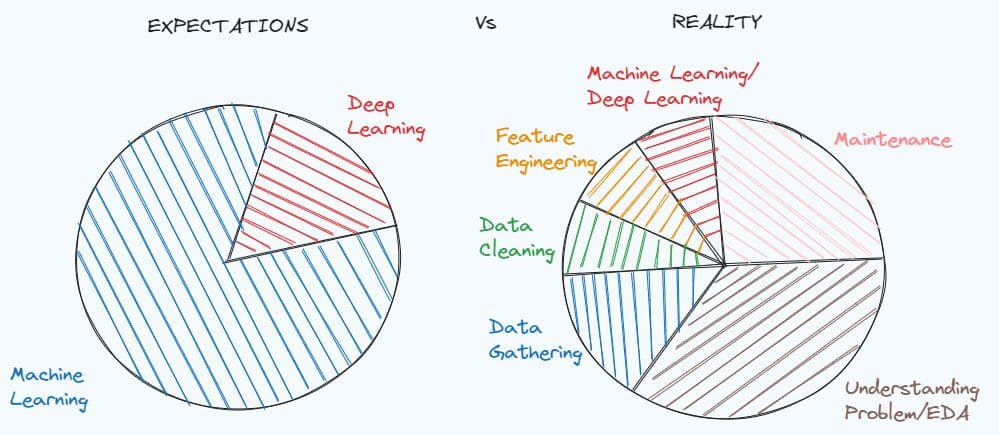
掌握数据清洗和预处理技术对于解决许多数据科学项目至关重要。一个简单的示例就是通过一个关于学习数据科学之前的学生的期望与数据科学家工作的现实进行比较。
在我们真正有实际经验之前,我们倾向于理想化工作职位,但现实总是与我们的期望不同。在处理现实世界的问题时,数据没有文档记录,数据集非常脏乱。首先,您需要深入研究问题,了解您缺少的线索和可以提取的信息。
在了解问题之后,您需要为机器学习模型准备数据集,因为初始数据永远不够。在本文中,我将展示七个可以帮助您进行数据预处理和清洗的步骤。
- 使用OpenAI和Langchain的语言电子邮件撰写器Web应用程序
- “认识 Med-Flamingo:一种独特的基础模型,能够进行针对医学领域的多模态上下文学习”
- 2023年销售和营销的顶级预测分析工具
步骤1:探索性数据分析
数据科学项目的第一步是探索性分析,它有助于理解问题并在后续步骤中做出决策。很容易忽略这一步骤,但这是最糟糕的错误,因为后来您将花费很多时间来找出模型出错或表现不如预期的原因。
根据我作为数据科学家的经验,我将探索性分析分为三个部分:
- 检查数据集的结构、统计数据、缺失值、重复值以及分类变量的唯一值
- 了解变量的含义和分布
- 研究变量之间的关系
要分析数据集的组织方式,可以使用以下Pandas方法:
df.head()
df.info()
df.isnull().sum()
df.duplicated().sum()
df.describe([x*0.1 for x in range(10)])
for c in list(df):
print(df[c].value_counts())
在尝试理解变量时,将分析分为两个进一步的部分很有用:数值特征和分类特征。首先,我们可以关注可以通过直方图和箱线图可视化的数值特征。然后,轮到分类变量了。如果是二元问题,最好先查看是否平衡。然后,我们可以使用条形图关注剩余的分类变量。最后,我们可以检查每对数值变量之间的相关性。其他有用的数据可视化方法包括散点图和箱线图,用于观察数值变量和分类变量之间的关系。
步骤2:处理缺失值
在第一步中,我们已经调查了每个变量中是否存在缺失值。如果存在缺失值,我们需要了解如何处理这个问题。最简单的方法是删除包含NaN值的变量或行,但我们更愿意避免这样做,因为我们可能会丢失有助于解决问题的有用信息。
如果我们处理的是数值变量,有几种方法可以填充它。最常用的方法是使用该特征的均值/中位数填充缺失值:
df['age'].fillna(df['age'].mean())
df['age'].fillna(df['age'].median())
另一种方法是使用分组插补法替换空白值:
df['price'].fillna(df.group('type_building')['price'].transform('mean'),
inplace=True)
如果数值特征和分类特征之间存在强关系,这可能是更好的选择。
同样,我们可以使用该变量的众数填充分类变量的缺失值:
df['type_building'].fillna(df['type_building'].mode()[0])
步骤3:处理重复值和异常值
如果数据集中存在重复项,最好删除重复的行:
df = df.drop_duplicates()在决定如何处理重复值时很简单,但处理异常值可能会更具挑战性。您需要问自己“删除异常值还是不删除异常值?”
如果您确定异常值只提供了噪声信息,则应删除异常值。例如,数据集中包含两个年龄为200岁的人,而年龄范围在0到90之间。在这种情况下,最好删除这两个数据点。
df = df[df.Age<=90]不幸的是,大多数情况下,删除异常值可能会导致丢失重要信息。最有效的方法是对数变换数值特征。
我在最近的经验中发现的另一种技术是剪辑方法。在这种技术中,您选择上限和下限,可以是0.1百分位数和0.9百分位数。特征值低于下限的值将被替换为下限值,而高于上限的变量值将被替换为上限值。
for c in columns_with_outliers:
transform= 'clipped_'+ c
lower_limit = df[c].quantile(0.10)
upper_limit = df[c].quantile(0.90)
df[transform] = df[c].clip(lower_limit, upper_limit, axis = 0)第四步:编码分类特征
下一步是将分类特征转换为数值特征。实际上,机器学习模型只能处理数字,而不能处理字符串。
在继续之前,您应该区分两种类型的分类变量:非序变量和序变量。
非序变量的示例包括性别、婚姻状况和工作类型。因此,如果变量不遵循顺序,则是非序变量,与序变量不同。序变量的示例可以是具有“童年”、“小学”、“中学”和“大学”的教育水平,以及具有“低收入”、“VoAGI”和“高收入”级别的收入。
当处理非序变量时,独热编码是考虑转换这些变量为数值的最流行技术。
在这种方法中,我们为每个分类特征的级别创建一个新的二进制变量。当级别的名称与级别的值相同时,每个二进制变量的值为1,否则为0。
from sklearn.preprocessing import OneHotEncoder
data_to_encode = df[cols_to_encode]
encoder = OneHotEncoder(dtype='int')
encoded_data = encoder.fit_transform(data_to_encode)
dummy_variables = encoder.get_feature_names_out(cols_to_encode)
encoded_df = pd.DataFrame(encoded_data.toarray(), columns=encoder.get_feature_names_out(cols_to_encode))
final_df = pd.concat([df.drop(cols_to_encode, axis=1), encoded_df], axis=1)当变量是序变量时,最常用的技术是序数编码,它将分类变量的唯一值转换为遵循顺序的整数。例如,收入的级别“低”、“VoAGI”和“高”分别编码为0、1和2。
from sklearn.preprocessing import OrdinalEncoder
data_to_encode = df[cols_to_encode]
encoder = OrdinalEncoder(dtype='int')
encoded_data = encoder.fit_transform(data_to_encode)
encoded_df = pd.DataFrame(encoded_data.toarray(), columns=["Income"])
final_df = pd.concat([df.drop(cols_to_encode, axis=1), encoded_df], axis=1)如果您想探索其他可能的编码技术,可以在此处查看。如果您对其他选择感兴趣,可以在这里查看。
第五步:将数据集分为训练集和测试集
现在是将数据集分为三个固定子集的时候了:通常选择使用60%的数据进行训练,20%进行验证,20%进行测试。随着数据量的增长,训练的百分比增加,验证和测试的百分比减少。
拥有三个子集很重要,因为训练集用于训练模型,而验证集和测试集可用于了解模型在新数据上的表现。
要拆分数据集,可以使用scikit-learn的train_test_split函数:
from sklearn.model_selection import train_test_split
X = final_df.drop(['y'],axis=1)
y = final_df['y']
train_idx, test_idx,_,_ = train_test_split(X.index,y,test_size=0.2,random_state=123)
train_idx, val_idx,_,_ = train_test_split(train_idx,y_train,test_size=0.2,random_state=123)
df_train = final_df[final_df.index.isin(train_idx)]
df_test = final_df[final_df.index.isin(test_idx)]
df_val = final_df[final_df.index.isin(val_idx)]
如果我们处理的是分类问题且类别不平衡,最好设置stratify参数,以确保训练集、验证集和测试集中的类别比例相同。
train_idx, test_idx,y_train,_ = train_test_split(X.index,y,test_size=0.2,stratify=y,random_state=123)
train_idx, val_idx,_,_ = train_test_split(train_idx,y_train,test_size=0.2,stratify=y_train,random_state=123)
这种分层交叉验证还有助于确保三个子集中目标变量的百分比相同,并提供更准确的模型性能。
步骤6:特征缩放
有些机器学习模型,如线性回归、逻辑回归、KNN、支持向量机和神经网络,需要对特征进行缩放。特征缩放只是将变量的值缩放到相同的范围,而不改变分布。
最常用的三种特征缩放技术是归一化、标准化和鲁棒缩放。
归一化,也称为最小-最大缩放,将变量的值映射到0和1之间的范围内。这可以通过将特征值减去最小值,然后除以最大值和最小值之间的差异来实现。
from sklearn.preprocessing import MinMaxScaler
sc=MinMaxScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
另一种常见的方法是标准化,它将列的值重新缩放以符合标准正态分布的特性,即均值为0,方差为1。
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
如果特征包含无法删除的异常值,则首选的方法是鲁棒缩放,它基于鲁棒统计量(中位数、第一四分位数和第三四分位数)重新缩放特征的值。通过从原始值中减去中位数,然后除以四分位距(特征的75th和25th四分位数之差)来获得重新缩放的值。
from sklearn.preprocessing import RobustScaler
sc=RobustScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
一般来说,最好基于训练集计算统计数据,然后将其用于同时对训练、验证和测试集进行缩放。这是因为我们假设只有训练数据,然后我们想在新数据上测试我们的模型,新数据应该有与训练集类似的分布。
步骤7:处理不平衡数据
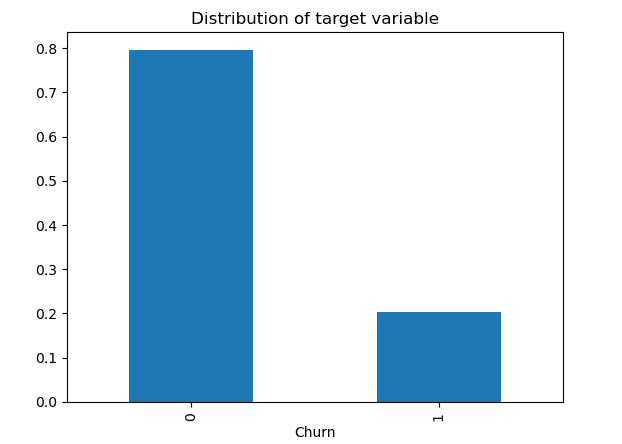
当我们在处理分类问题时,发现类别不平衡时,才需要包括这一步骤。
如果类别之间有轻微差异,例如类别1包含40%的观测值,类别2包含剩余的60%,我们不需要应用过采样或欠采样技术来改变其中一个类别的样本数量。我们可以避免只关注准确率,因为准确率只在数据集平衡时是一个很好的度量标准,我们应该只关心精确率、召回率和F1得分等评估指标。
但是可能出现正类别与负类别相比具有非常低的数据点比例(0.2与0.8)。机器学习可能在观测较少的类别上表现不佳,导致无法解决任务。
为了解决这个问题,有两种可能性:欠采样多数类别和过采样少数类别。欠采样是通过随机从多数类别中删除一些数据点来减少样本数量,而过采样是通过从较不频繁的类别中随机添加数据点来增加少数类别的观测数量。使用imblearn可以用几行代码平衡数据集:
# 欠采样
from imblearn.over_sampling import RandomUnderSampler,RandomOverSampler
undersample = RandomUnderSampler(sampling_strategy='majority')
X_train, y_train = undersample.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
# 过采样
oversample = RandomOverSampler(sampling_strategy='minority')
X_train, y_train = oversample.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
然而,有时候删除或复制一些观测并不能有效地提高模型性能。最好的方法是在少数类别中创建新的人工数据点。解决这个问题的一种技术是SMOTE,它以生成少数类别中的合成记录而闻名。与KNN类似,其思想是基于特定距离(如t)识别属于少数类别的观测的k个最近邻居。然后,在这些k个最近邻居之间的随机位置生成一个新点。此过程将继续创建新点,直到数据集完全平衡。
from imblearn.over_sampling import SMOTE
resampler = SMOTE(random_state=123)
X_train, y_train = resampler.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
我应该强调,这些方法只应用于重新采样训练集。我们希望我们的机器模型以强大的方式进行学习,然后我们可以将其应用于对新数据进行预测。
最后的想法
希望您发现本教程很有用。在没有了解所有这些技术的情况下,开始我们的第一个数据科学项目可能会很困难。您可以在此处找到我所有的代码。
当然,还有其他方法我没有在文章中涵盖,但我更倾向于关注最流行和已知的方法。您有其他建议吗?如果您有有见地的建议,请在评论中留言。
有用的资源:
- 探索性数据分析实用指南
- 哪些模型需要归一化数据?
- 不平衡分类的随机过采样和欠采样
Eugenia Anello目前是意大利帕多瓦大学信息工程系的研究助理。她的研究项目专注于连续学习与异常检测的结合。





