逻辑回归:直觉与实现
逻辑回归:直觉与实现' (Logistic Regression Intuition and Implementation)
逻辑回归算法背后的数学原理及使用Numpy从零开始实现
介绍
逻辑回归是一种基本的二分类算法,可以学习两组不同数据属性之间的决策边界。在本文中,我们将理解分类模型背后的理论,并使用Python实现它。
直觉
数据集
逻辑回归是一种监督学习算法,因此我们有数据特征属性及其对应的标签。特征是独立变量,用X表示,并以一维数组表示。类别标签用y表示,只能是0或1。因此,逻辑回归是一种二分类算法。
如果数据有d个特征:
损失函数
与线性回归类似,我们为特征属性和偏置值分配了权重。
我们的目标是找到最优的权重和偏置值,以更好地拟合我们的数据。
每个特征属性都有一个权重值和一个偏置值。
我们随机初始化这些值,并使用梯度下降法对它们进行优化。在训练过程中,我们将权重和特征进行点积运算,并加上偏置项。
但由于我们的目标标签是0和1,我们使用一个非线性的Sigmoid函数,用g表示,将我们的值推到所需的范围内。
绘制的Sigmoid函数如下:
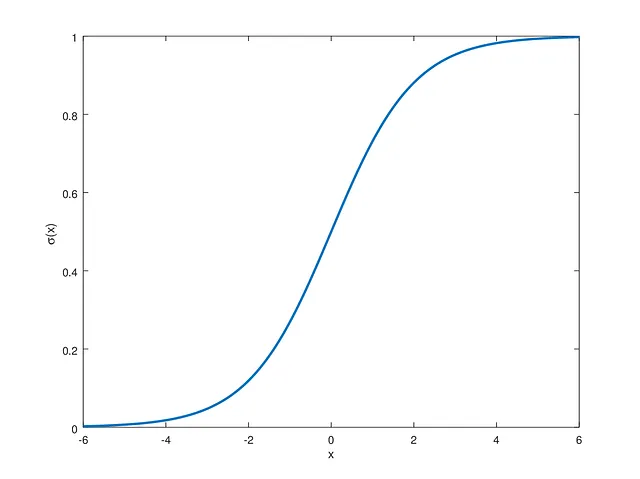
逻辑回归的目标是学习权重和偏置值,使得传递给Sigmoid函数的值对于正标签是正的,对于负标签是负的。
为了预测逻辑回归中的值,我们将我们的预测值传递给Sigmoid函数。因此,预测函数为:
现在我们从模型中获得了预测值后,我们可以将其与原始目标标签进行比较。使用二元交叉熵损失计算预测之间的误差。损失函数如下:
其中y是原始目标标签,p是在[0,1]之间的预测值。损失函数的目标是将预测值推向实际目标标签。如果标签为0且模型预测为0,则损失为0。类似地,如果预测和目标标签都为1,则损失为0。否则,模型试图收敛到这些值。
梯度下降
我们使用损失函数,并获得关于权重和偏置的导数。使用链式法则和数学推导,导数如下:
我们获得一个标量值,可以用来更新权重和偏置。
这样我们就可以根据损失梯度来更新值,在多次迭代后,我们逐渐接近权重和偏置的最优值。
在推理过程中,我们可以使用权重和偏置值来进行预测。
实现
我们利用上述提到的数学公式来编码逻辑回归模型,并将评估其在一些基准数据集上的性能。
首先,我们初始化类和参数。
class LogisticRegression(): def __init__( self, learning_rate:float=0.001, n_iters:int=10000 ) -> None: self.n_iters = n_iters self.lr = learning_rate self.weights = None self.bias = None我们需要优化的权重和偏置值,所以我们将它们初始化为对象属性。然而,我们不能在这里设置大小,因为它取决于训练时传递的数据。因此,我们暂时将它们设置为None。学习率和迭代次数是可以调整以提高性能的超参数。
训练
def fit( self, X : np.ndarray, y : np.ndarray ): n_samples, n_features = X.shape # 使用随机值初始化权重和偏置 # 权重矩阵的大小基于数据特征的数量 # 偏置是一个标量值 self.weights = np.random.rand(n_features) self.bias = 0 for iteration in range(self.n_iters): # 从模型中获取预测 linear_pred = np.dot(X, self.weights) + self.bias predictions = sigmoid(linear_pred) loss = predictions - y # 基于损失进行梯度下降 dw = (1 / n_samples) * np.dot(X.T, loss) db = (1 / n_samples) * np.sum(loss) # 更新模型参数 self.weights = self.weights - self.lr * dw self.bias = self.bias - self.lr * db训练函数初始化权重和偏置值。然后我们多次迭代遍历数据集,优化这些值以便使损失最小化。
根据上述方程,sigmoid函数的实现如下:
def sigmoid(x): return 1 / (1 + np.exp(-x))然后我们使用此函数生成预测:
linear_pred = np.dot(X, self.weights) + self.biaspredictions = sigmoid(linear_pred)我们计算这些值的损失并优化我们的权重:
loss = predictions - y # 基于损失进行梯度下降dw = (1 / n_samples) * np.dot(X.T, loss)db = (1 / n_samples) * np.sum(loss)# 更新模型参数self.weights = self.weights - self.lr * dwself.bias = self.bias - self.lr * db推理
def predict( self, X : np.ndarray, threshold:float=0.5 ): linear_pred = np.dot(X, self.weights) + self.bias predictions = sigmoid(linear_pred) # 转换为0或1标签 y_pred = [0 if y <= threshold else 1 for y in predictions] return y_pred一旦我们在训练过程中拟合了我们的数据,我们可以使用学到的权重和偏置来进行类似的预测。模型的输出范围是[0, 1],根据sigmoid函数确定。然后我们可以使用阈值值例如0.5,所有超过此概率的值被标记为正标签,所有低于此阈值的值被标记为负标签。
完整代码
import numpy as npdef sigmoid(x): return 1 / (1 + np.exp(-x))class LogisticRegression(): def __init__( self, learning_rate:float=0.001, n_iters:int=10000 ) -> None: self.n_iters = n_iters self.lr = learning_rate self.weights = None self.bias = None def fit( self, X : np.ndarray, y : np.ndarray ): n_samples, n_features = X.shape # 使用随机值初始化权重和偏置 # 权重矩阵的大小基于数据特征的数量 # 偏置是一个标量值 self.weights = np.random.rand(n_features) self.bias = 0 for iteration in range(self.n_iters): # 从模型中获取预测 linear_pred = np.dot(X, self.weights) + self.bias predictions = sigmoid(linear_pred) loss = predictions - y # 基于损失进行梯度下降 dw = (1 / n_samples) * np.dot(X.T, loss) db = (1 / n_samples) * np.sum(loss) # 更新模型参数 self.weights = self.weights - self.lr * dw self.bias = self.bias - self.lr * db def predict( self, X : np.ndarray, threshold:float=0.5 ): linear_pred = np.dot(X, self.weights) + self.bias predictions = sigmoid(linear_pred) # 转换为0或1标签 y_pred = [0 if y <= threshold else 1 for y in predictions] return y_pred评估
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from sklearn.metrics import accuracy_score
from model import LogisticRegression
if __name__ == "__main__":
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
score = accuracy_score(y_pred, y_test)
print(score)我们可以使用上述脚本来测试我们的逻辑回归模型。我们使用Scikit-Learn中的乳腺癌数据集进行训练。然后,我们可以将我们的预测结果与原始标签进行比较。
仔细调整一些超参数后,我的准确率得分超过了90%。
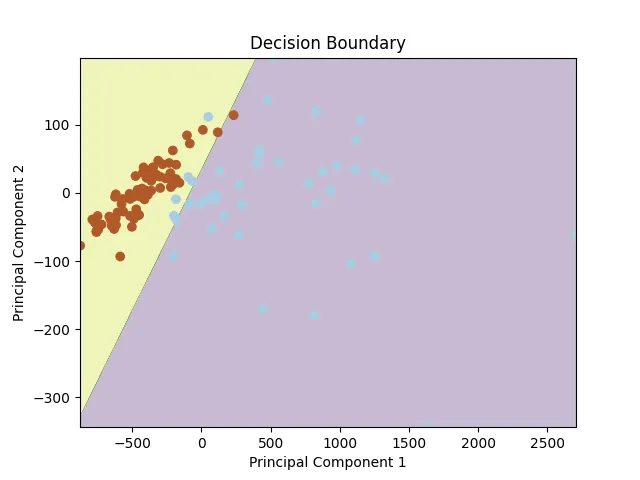
我们可以使用不同的降维技术,如主成分分析(PCA),来可视化决策边界。将特征降维到二维后,我们得到了以下决策边界。
结论
总之,本文探讨了逻辑回归的数学直觉,并展示了使用NumPy的实现方法。逻辑回归是一种有价值的分类算法,利用sigmoid函数和梯度下降方法为二分类问题找到最优决策边界。
有关代码和实现,请参考此GitHub仓库。关注我以获取更多关于深度学习架构和研究进展的文章。






