将您的文件(包括PDF、txt和网页)转换为语音对话
转换文件为语音对话
创建网页和使用LLMs让您可以向文档(如PDF、TXT甚至网页)提问的完整指南。
目录
· 介绍· 它是如何工作的· 步骤(第一部分)👣· 休息:回顾(第一部分)🌪️· 步骤(第二部分)👣· 休息:回顾(第二部分)🌪️· 网页应用程序· 急于求成者(代码)· 结论· 参考文献
介绍
我们都必须阅读永恒的文档,以获取我们需要的两个句子。
您是否曾希望能从文档中提取引人注目的信息,而不至于在一片文字海洋中迷失方向?
别再寻找了!欢迎来到“使用LLM与文档对话”的项目。它就像从PDF、TXT文件或网页中恢复宝藏一样,而无需大脑劳累。而且不用担心,您不需要技术巫术学位来玩得开心。我们使用Streamlit创建了一个用户友好的界面,所以即使是您不懂技术的朋友——市场助理——也可以参与其中。
本文将深入探讨应用智能背后的理论和代码,揭示Web应用程序的工作原理。为了让您对我们将使用的技术有一个快速概述,请查看以下显示这四个主要工具的图像。

当然,您可以在我的GitHub存储库中找到代码,或者如果您想直接测试代码,可以转到“急于求成者(代码)”部分。
它是如何工作的
让我们透过“使用LLM与文档对话”的面纱来一窥其中的奥秘。这个项目就像一个有趣的二重奏:一个聪明的播放器(后端)和一个用户友好的网站(前端)。
- 聪明的阅读器:AI大脑像一位超级聪明的朋友一样阅读和理解文档,出色地处理PDF、TXT和网页内容。
- 用户友好的网站:用户友好的Web界面,用于配置和与模型交互。它由两个主要页面组成,每个页面都有特定的目的:第一步️⃣创建数据库和第二步️⃣请求文档。
我们项目的大致概述如下:
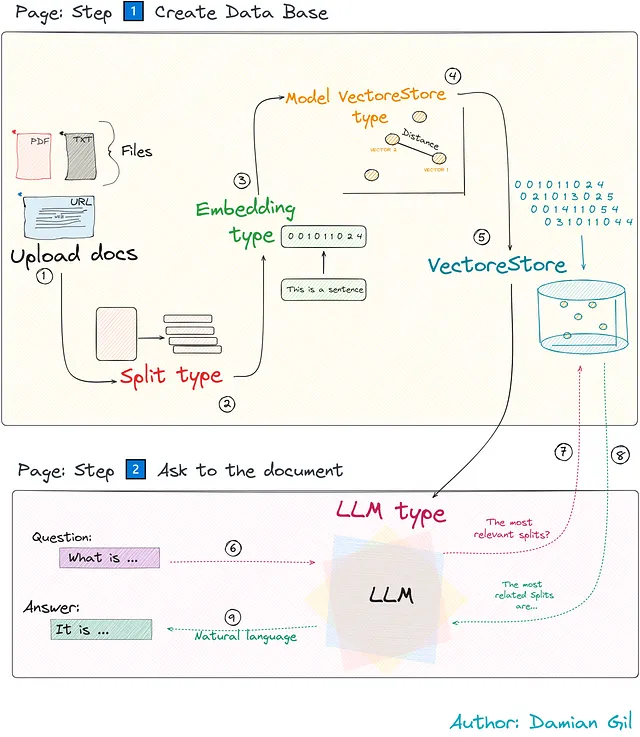
尽管看起来复杂,我们将简化每个关键步骤以使其正常运行。通过关注智能的运作方式,我们将了解它是如何工作的。这些步骤由Python TalkDocument类来支持,我们将用相应的代码演示每个步骤,使其栩栩如生。
步骤(第一部分)👣
准备好一起探索每一步,发现幕后的魔力!🚀🔍🎩
1- 导入 文件
这一步很明显,对吧?在这一步中,您决定提供什么类型的材料。无论是PDF,纯文本,网址,甚至原始字符串格式,都可以选择。
# 在__init__函数中,我已经注释掉了我们目前不感兴趣的变量。def __init__(self, HF_API_TOKEN, data_source_path=None, data_text=None, OPENAI_KEY=None) -> None: # 您可以输入文件的路径。 self.data_source_path = data_source_path # 您可以直接以字符串格式输入文件 self.data_text = data_text self.document = None # self.document_splited = None # self.embedding_model = None # self.embedding_type = None # self.OPENAI_KEY = OPENAI_KEY # self.HF_API_TOKEN = HF_API_TOKEN # self.db = None # self.llm = None # self.chain = None # self.repo_id = Nonedef get_document(self, data_source_type="TXT"):# DS_TYPE_LIST= ["WEB", "PDF", "TXT"] data_source_type = data_source_type if data_source_type.upper() in DS_TYPE_LIST else DS_TYPE_LIST[0] if data_source_type == "TXT": if self.data_text: self.document = self.data_text elif self.data_source_path: loader = dl.TextLoader(self.data_source_path) self.document = loader.load() elif data_source_type == "PDF": if self.data_text: self.document = self.data_text elif self.data_source_path: loader = dl.PyPDFLoader(self.data_source_path) self.document = loader.load() elif data_source_type == "WEB": loader = dl.WebBaseLoader(self.data_source_path) self.document = loader.load() return self.document根据您上传的文件类型,将使用不同的方法来读取文档。有趣的改进可以涉及自动格式检测的加入。
2- 分割类型
现在,您可能会想为什么存在“类型”一词?在应用程序中,您可以选择分割方法。但在深入探讨这个主题之前,让我们解释一下文档分割是什么。
可以这样理解:就像人类需要章节、段落和句子来组织信息一样(想象一本没有段落的书——是的!),机器也需要结构。我们需要将文档切割成几个较小的部分,以更好地理解它。这可以通过字符或标记来完成。
# SPLIT_TYPE_LIST = ["CHARACTER", "TOKEN"]def get_split(self, split_type="character", chunk_size=200, chunk_overlap=10): split_type = split_type.upper() if split_type.upper() in SPLIT_TYPE_LIST else SPLIT_TYPE_LIST[0] if self.document: if split_type == "CHARACTER": text_splitter = ts.RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) elif split_type == "TOKEN": text_splitter = ts.TokenTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) # 如果您输入的是字符串作为文档,我们将执行split_text。 if self.data_text: try: self.document_splited = text_splitter.split_text(text=self.document) except Exception as error: print( error) # 如果您上传了文档,我们将执行split_documents。 elif self.data_source_path: try: self.document_splited = text_splitter.split_documents(documents=self.document) except Exception as error: print( error) return self.document_splited3- 嵌入类型
我们人类可以轻松理解文字和图片,但机器需要更多的指导。这一点在以下情况下变得明显:
- 将数据集中的分类变量转换为数字
- 神经网络中的图像管理。例如,在将图像输入神经网络模型之前,需要对其进行转换以成为数值张量。
从我们所见,数学模型有着数字的语言。这一现象在自然语言处理领域也有所体现,其中推广了词嵌入的概念。
本质上,我们在这一步骤中所做的是将上一阶段(文档块)的拆分转化为数值向量。
这种转换或编码是通过专门的算法完成的。需要注意的是,这个过程将句子转换为数字向量,并且这种编码不是随机的;它遵循一种结构化的方法。
这段代码非常简单:我们实例化负责集成的对象。需要注意的是,在这一点上,我们只是创建了一个集成对象。在接下来的步骤中,我们将进行实际的转换。
def get_embedding(self, embedding_type="HF", OPENAI_KEY=None): if not self.embedding_model: embedding_type = embedding_type.upper() if embedding_type.upper() in EMBEDDING_TYPE_LIST else EMBEDDING_TYPE_LIST[0] # 如果我们选择使用Hugging Face模型进行嵌入 if embedding_type == "HF": self.embedding_model = embeddings.HuggingFaceEmbeddings() # 如果我们选择使用OpenAI模型进行嵌入 elif embedding_type == "OPENAI": self.OPENAI_KEY = self.OPENAI_KEY if self.OPENAI_KEY else OPENAI_KEY if self.OPENAI_KEY: self.embedding_model = embeddings.OpenAIEmbeddings(openai_api_key=OPENAI_KEY) else: print("您需要提供一个OpenAI API密钥") # 对象 self.embedding_type = embedding_type return self.embedding_model小结:回顾(第一部分)🌪️
为了理解前三个步骤,我们来看以下例子:
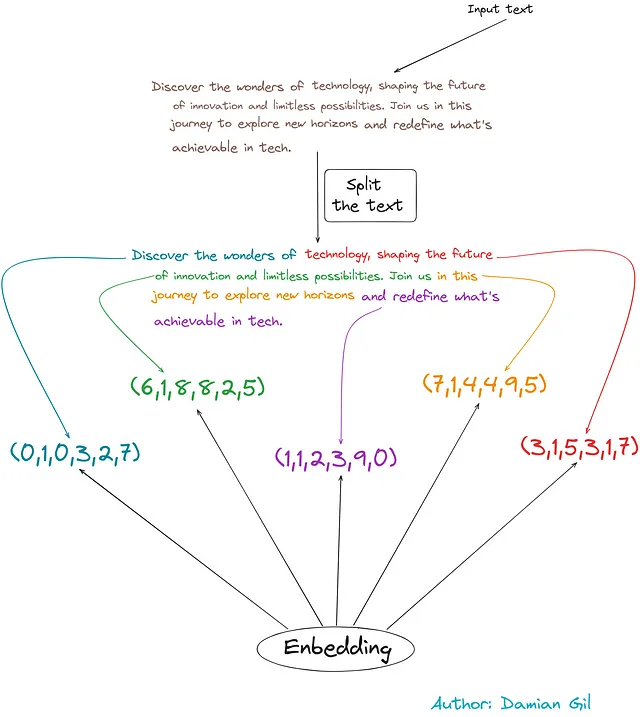
我们从一个输入文本开始。
- 我们根据字符数进行分布(在这个例子中大约有50个字符)。
- 我们进行集成,将文本片段转化为数字向量。
太棒了!🚀现在,让我们开始通过剩余的层级进行激动人心的旅程。系好安全带,因为我们即将揭开一些真正的技术魔法!🔥🔓
步骤(第二部分)👣
我们将继续看到后续的步骤。
4- 模型向量存储类型
现在我们已经将文本转化为代码(嵌入),我们需要一个地方来存储它们。这就是“向量存储库”的概念。它就像这些代码的智能图书馆,方便我们在提问时快速找到和检索相似的代码。
把它想象成一个整洁的存储空间,让您能够快速找到您所需的内容!
这种数据库的创建由专门为此目的设计的算法管理,例如FAISS(Facebook AI Similarity Search)。还有其他选择,目前,此类支持CHROMA和SVM。
这一步和下一步共享代码。在这一步中,您选择要创建的向量存储库类型,而下一步是实际的创建过程。
5. 模型向量存储(创建)
这种类型的数据库处理两个主要方面:
- 向量存储:它存储由集成生成的向量。
- 相似度计算:它计算向量之间的相似度。
那么,这些向量之间的相似度到底是什么,为什么它很重要呢?
嗯,还记得我提到过集成不是随机的吗?它被设计成具有相似含义的单词或短语具有相似的向量。这样,我们可以计算向量之间的距离(例如使用欧几里得距离),从而得到它们的“相似度”的度量。
为了通过一个例子来可视化这个过程,想象我们有三个句子。
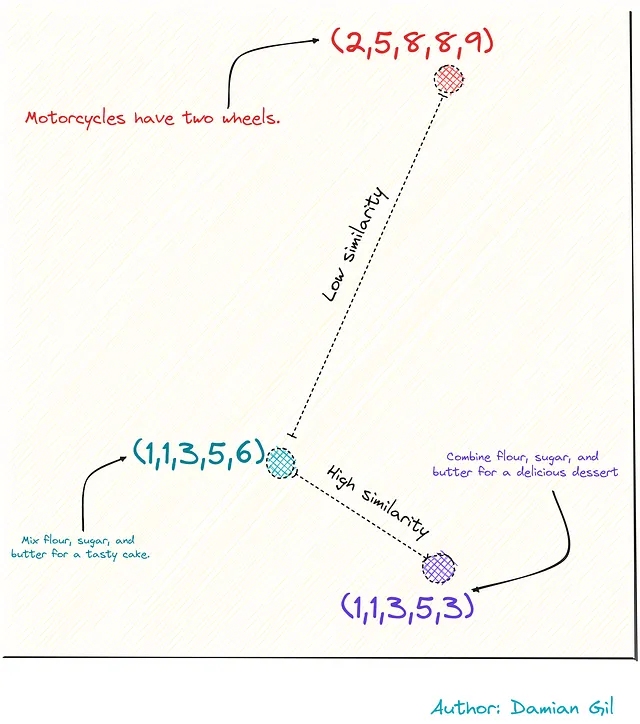
其中两个与食谱有关,而第三个与摩托车有关。通过将它们表示为向量(借助集成),我们可以计算这些点或句子之间的距离。这个距离作为它们相似性的度量。
从代码的角度来看,让我们看一下所需的要求:
- 文本分割
- 嵌入类型
- 向量存储模型
# VECTORSTORE_TYPE_LIST = ["FAISS", "CHROMA", "SVM"]def get_storage(self, vectorstore_type = "FAISS", embedding_type="HF", OPENAI_KEY=None): self.embedding_type = self.embedding_type if self.embedding_type else embedding_type vectorstore_type = vectorstore_type.upper() if vectorstore_type.upper() in VECTORSTORE_TYPE_LIST else VECTORSTORE_TYPE_LIST[0] # 这里我们调用执行嵌入的算法 # 并创建对象 self.get_embedding(embedding_type=self.embedding_type, OPENAI_KEY=OPENAI_KEY) # 这里我们选择要使用的向量存储类型 if vectorstore_type == "FAISS": model_vectorstore = vs.FAISS elif vectorstore_type == "CHROMA": model_vectorstore = vs.Chroma elif vectorstore_type == "SVM": model_vectorstore = retrievers.SVMRetriever # 这里我们创建向量存储。在这种情况下, # 文档来自原始文本。 if self.data_text: try: self.db = model_vectorstore.from_texts(self.document_splited, self.embedding_model) except Exception as error: print( error) # 这里我们创建向量存储。在这种情况下, # 文档来自类似pdf txt的文档 elif self.data_source_path: try: self.db = model_vectorstore.from_documents(self.document_splited, self.embedding_model) except Exception as error: print( error) return self.db为了说明这一步发生了什么,我们可以看到下面的图像。它展示了编码文本片段如何存储在向量存储中,从而使我们能够计算向量/点之间的距离/相似性。
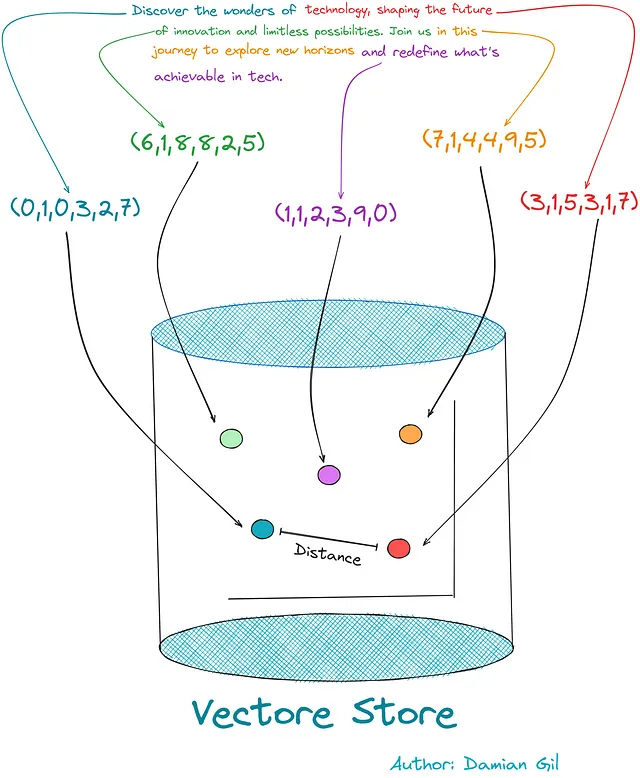
小结:回顾(第二部分)🌪️
太棒了!我们现在有一个能够存储我们的文档并计算加密文本块之间相似性的数据库。想象一种情况,我们想要对外部句子进行编码并将其存储在我们的向量存储中。这样,我们就可以计算新向量与文档分割之间的距离。(请注意,这里应使用相同的集成来创建向量存储。)我们可以通过以下图像来可视化这一过程。
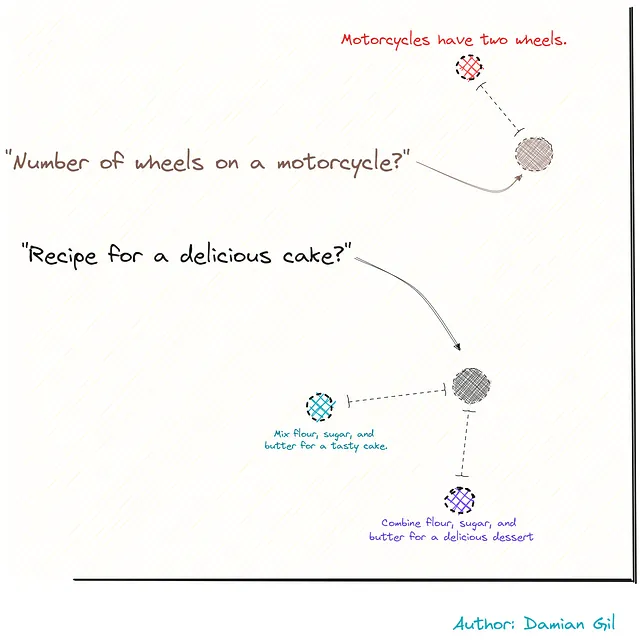
记住之前的图片…我们有两个问题,并且我们使用集成将它们转化为数字。然后我们测量距离,并找到与我们的问题最接近的句子。 这些句子就像完美的组合!就像瞬间找到最好的拼图一样!🚀🧩🔍
6- 问题
记住我们的目标是提出一个关于文档的问题并获得答案。在这一步中,我们收集用户提供的问题作为输入。
7 & 8- 相关分割
这是我们将问题插入向量存储库的地方,将其嵌入以将句子转换为数字向量。然后,我们计算我们的问题与文档的各个部分之间的距离,确定哪些部分最接近我们的问题。代码如下:
# 根据我们构建的向量存储类型,我们将使用特定的函数。它们都会返回# 最相关分割的列表。def get_search(self, question, with_score=False): relevant_docs = None if self.db and "SVM" not in str(type(self.db)): if with_score: relevant_docs = self.db.similarity_search_with_relevance_scores(question) else: relevant_docs = self.db.similarity_search(question) elif self.db: relevant_docs = self.db.get_relevant_documents(question) return relevant_docs使用下面的代码试一试。学习如何以一个由4个项目组成的列表回答。当我们查看内部时,实际上是你输入的文档的不同部分。就像这个应用程序会为你呈现出最适合你问题的4个拼图一样!🧩💬
9- 响应(自然语言)
太棒了,现在我们有了与问题最相关的文本。但是我们不能只是将这些部分交给用户并终止它。我们需要对他们的问题给出简明扼要的答案。这就是我们的语言模型(LLM)发挥作用的地方!有许多LLM的风味。在代码中,我们将“flan-alpaca-large”设置为默认值。不要犹豫,选择最触动你的那个人吧!🚀🎉
这是计划:
- 我们恢复与问题相关的最重要的部分(分割)。
- 我们准备一个提示,其中包括问题、我们希望得到的答案以及这些文本元素。
- 我们将这个提示传递给我们的智能语言模型(LLM)。他知道问题和这些元素中包含的信息,并给我们提供自然的答案。️
这最后一部分在下面的图片中显示:🖼️
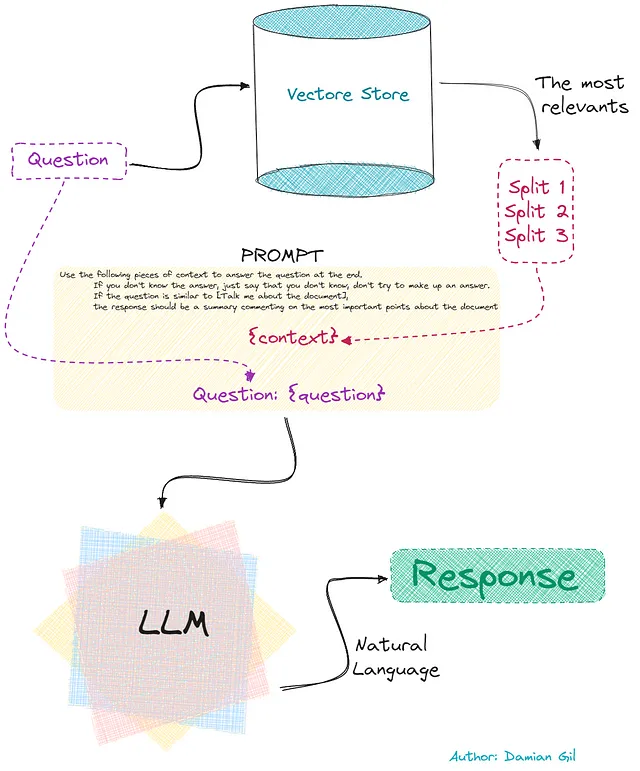
确实,这个确切的流程就是代码中执行的流程。你会注意到代码中还有一个额外的步骤涉及创建一个“提示”。的确,我们可以得出一个最终答案,即由LLM找到的答案的组合。为简单起见,让我们用最简单的方式来做:“stuff”。这意味着答案是LLM找到的第一个解决方案。在这里,你不会迷失在理论中!🌟
def do_question(self, question, repo_id="declare-lab/flan-alpaca-large", chain_type="stuff", relevant_docs=None, with_score=False, temperature=0, max_length=300): # 我们获取与问题最相关的分割。 relevant_docs = self.get_search(question, with_score=with_score) # 我们定义要使用的LLM, # 我们必须引入repo id,因为我们使用huggingface。 self.repo_id = self.repo_id if self.repo_id is not None else repo_id chain_type = chain_type.lower() if chain_type.lower() in CHAIN_TYPE_LIST else CHAIN_TYPE_LIST[0] # 这个检查是必要的,因为我们可以多次调用该函数, # 但每次调用都创建一个LLM是没有意义的。 # 所以它检查类中是否已经存在一个LLM # 或者repo_id(LLM的类型)是否已经改变。 if (self.repo_id != repo_id ) or (self.llm is None): self.repo_id = repo_id # 我们创建LLM。 self.llm = HuggingFaceHub(repo_id=self.repo_id,huggingfacehub_api_token=self.HF_API_TOKEN, model_kwargs= {"temperature":temperature, "max_length": max_length}) # 我们创建提示 prompt_template = """使用以下上下文片段回答最后的问题。 如果你不知道答案,只要说你不知道,不要试图编造一个答案。 如果问题类似于[告诉我关于文档的内容], 响应应该是对文档的最重要要点的评论 {context} 问题:{question} """ PROMPT = PromptTemplate( template=prompt_template, input_variables=["context", "question"] ) # 我们创建链,chain_type= "stuff"。 self.chain = self.chain if self.chain is not None else load_qa_chain(self.llm, chain_type=chain_type, prompt = PROMPT) # 我们使用提示向LLM查询 # 我们检查是否已经定义了一个链, # 如果不存在,则创建一个 response = self.chain({"input_documents": relevant_docs, "question": question}, return_only_outputs=True) return response你已经完成了对我们网页应用程序的工作原理的理解,真棒!如果你在这里,就来五个!现在,让我们深入文章的最后一部分,探索网页应用程序的页面。🎉🕵️♂️
网页应用程序
这个界面是为那些没有技术知识的人设计的,所以你可以充分利用这项技术而没有任何问题。🚀👩💻
使用这个网站非常简单而强大。基本上,用户只需要提供文档。如果你还没有准备好从其他参数中受益,在下一步中,你可以开始提问。🌟🤖
让我们来看看以下步骤:
- 提供文档或网页链接。通过页面Step 1️⃣ 创建数据库。
- 设置配置(可选)。通过页面Step 1️⃣ 创建数据库。
- 提问并获得答案!📚🔍🚀 通过页面Step 2️⃣ 提问文档。
1. 提供文档或网页链接。
在这一步中,您通过将文档上传到网站来添加文档。请记住,如果您没有将Face Hugging API密钥设置为环境变量,”home”选项卡会要求您输入它。📂🔑
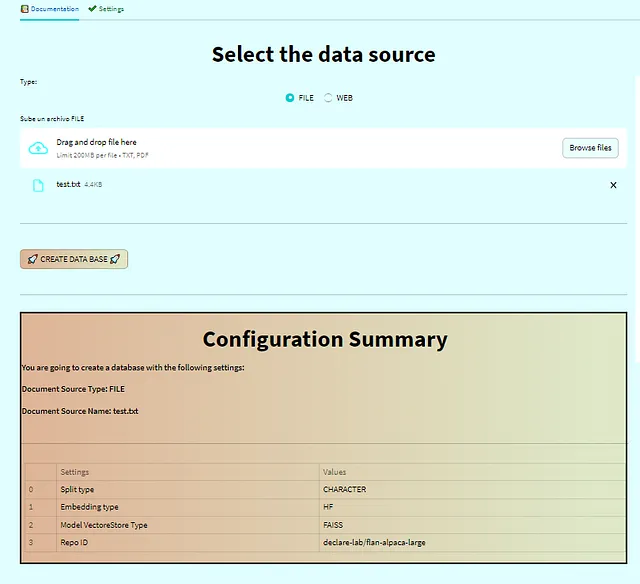
一旦您附加了文档并设置了您的偏好,您的配置摘要表将显示出来。然后“创建数据库”按钮解锁。当您点击该按钮时,将创建数据库或向量存储,并将您重定向到问题部分。📑🔒🚀
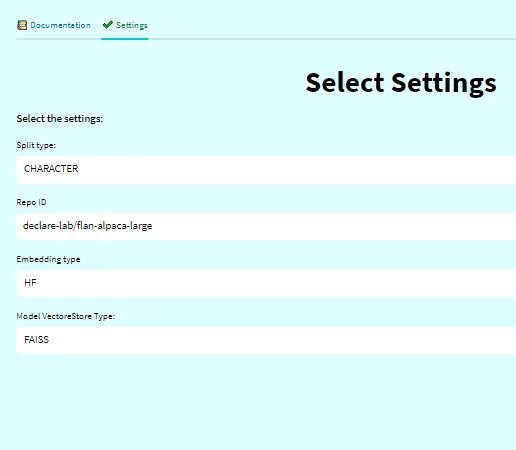
2. 设置配置(可选)。
如前所述,我们可以根据自己的喜好配置向量存储。有不同的方法来拆分文档、嵌入等。该选项卡允许您根据自己的喜好进行自定义设置。它还提供了快速设置的默认配置。⚙️🛠️
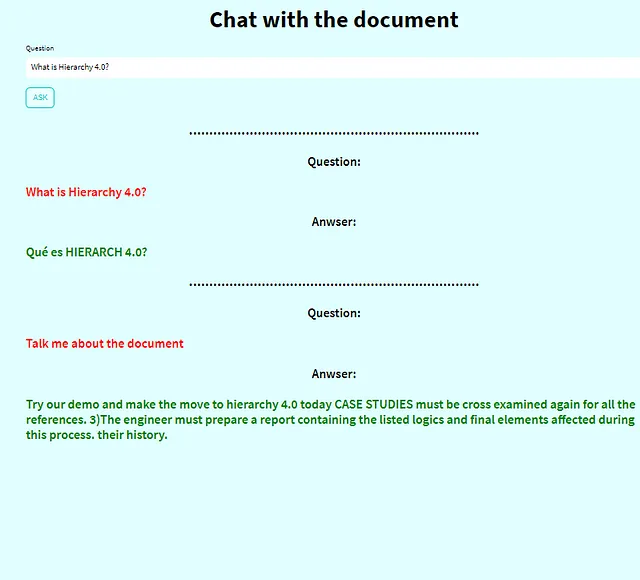
3. 提问并获得答案!
在这一点上,您可以开始提出您想要的所有查询。现在是时候尽情享受和与工具互动了!🤗🔍💬
对于急于开始的人(代码)
对于那些渴望深入学习的人,您可以直接获取TalkDocument类,并将其粘贴到Jupyter笔记本中进行操作。您可能需要安装一些依赖项,但我相信这对您来说不会是个挑战。祝您在探索和实验中玩得开心!快乐编程!🚀📚😄
在代码中玩耍的TalkDocument类(作者提供的代码)
结论
恭喜您在这个激动人心的旅程中走到了这一步!我们深入探讨了这个网页应用程序背后的智能工作原理。从上传文档到获取答案,您已经涵盖了很多内容!如果您感到灵感涌动,代码可以在我的GitHub代码库中找到。欢迎协作并通过LinkedIn联系我提出任何问题或建议!祝您用这个强大的工具探索和实验时玩得开心!
如果您愿意,您可以查看我的GitHub
damiangilgonzalez1995 – 概述
热衷于数据,我从物理学转向数据科学。曾在Telefonica、HP工作,现任CTO…
github.com
参考资料
- Langchain文档
- Hugging Face文档
- Facebook AI相似性搜索(Faiss)简介
- Steamlit文档



