逐步解释核密度估计器
核密度估计器解释
直观推导KDE公式
介绍
为了对数据分布有所了解,我们绘制概率密度函数(PDF)。当数据很好地适配常见的密度函数,如正态分布、泊松分布、几何分布等时,我们会感到满意。然后,可以使用最大似然方法将密度函数拟合到数据上。

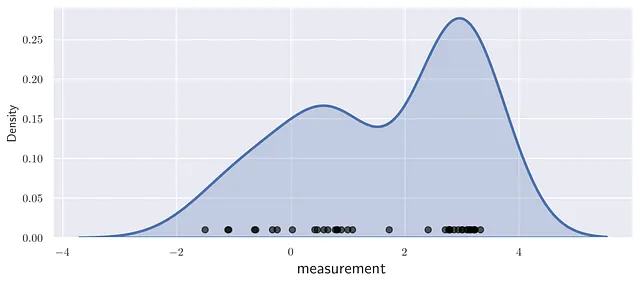
不幸的是,数据分布有时太不规则,不像任何通常的PDF。在这种情况下,核密度估计(KDE)提供了数据分布的合理和视觉上令人愉悦的表示。
- Google DeepMind研究人员介绍了SynJax:一种用于JAX结构化概率分布的深度学习库
- AI模型功能强大,但它们是否符合生物学原理?
- 亚马逊购物如何使用亚马逊Rekognition内容审核来审查产品评论中的有害图像
我会引导您通过以直观的方式构建KDE的步骤,而不是依赖严格的数学推导。
核函数
<p理解KDE的关键是将其视为由构建块组成的函数,类似于不同的物体由乐高积木组成。KDE的独特特点是它只使用一种类型的积木,称为核函数(”一种积木统治它们所有”)。这个积木的关键特性是能够进行平移和拉伸/收缩。每个数据点都被赋予一个积木,而KDE是所有积木的总和。
KDE是由一种被称为核函数的构建块组成的复合函数。
核函数分别对每个数据点进行评估,然后将这些部分结果求和以形成KDE。
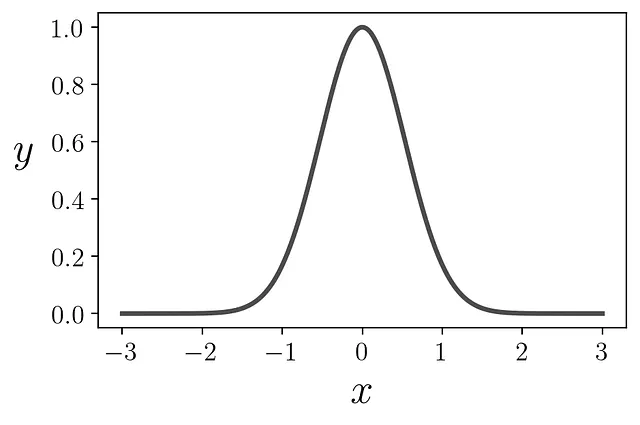
<p构建KDE的第一步是只关注一个数据点。如果要为单个数据点创建PDF,您会怎么做?首先,令x = 0。最合乎逻辑的方法是使用一个在该点上精确峰值并随距离衰减的PDF。函数
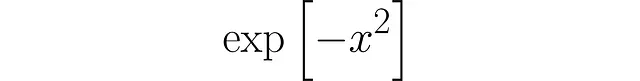
<p将起到作用。
<p然而,由于PDF应在曲线下有一个单位面积,我们必须对结果进行重新缩放。因此,函数必须除以2π的平方根,并乘以√2的因子进行拉伸(3Blue1Brown提供了这些因子的出色推导):

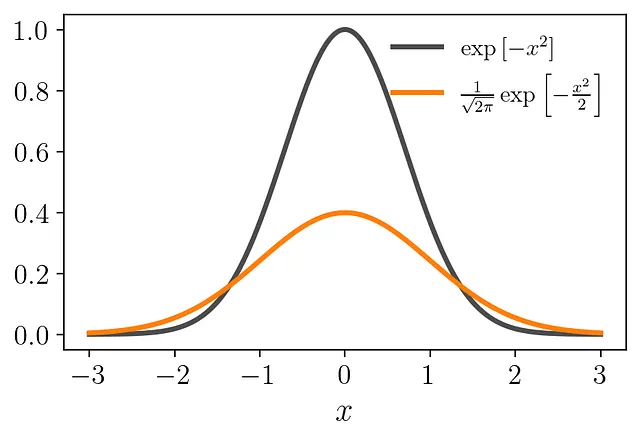
<p最终,我们得到了我们的乐高积木,称为核函数,它是一个有效的PDF:

<p该核函数等价于均值为零、方差为单位的高斯分布。
<p让我们玩一会儿。我们将从学习如何沿x轴平移它开始。
<p取一个单独的数据点xᵢ – 属于我们数据集X的第i个点。通过减去参数来实现平移:
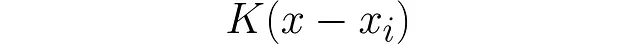
要使曲线更宽或更窄,我们只需在参数中添加一个常数h(所谓的核带宽)。通常将其作为分母引入:
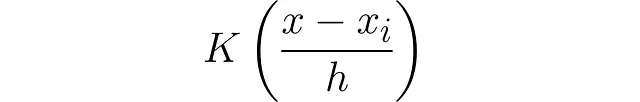
然而,核函数下的面积会乘以h。因此,我们必须通过除以h将其恢复为单位面积:

您可以选择任何h值。以下是它的工作原理示例。
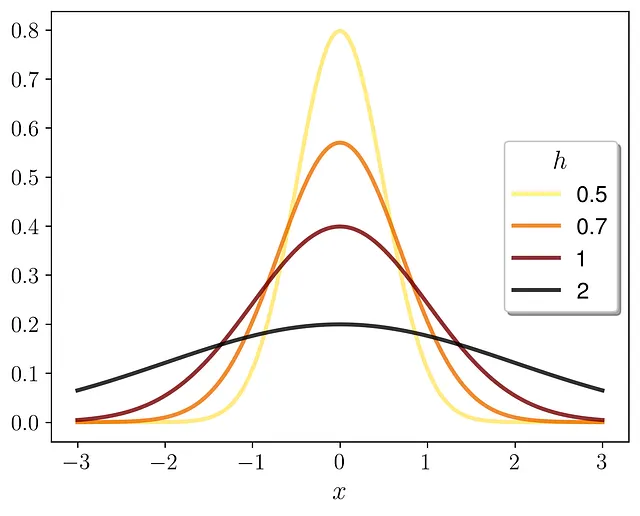
h越大,PDF越宽。h越小,PDF越窄。
核密度估计
考虑一些虚拟数据以查看如何将该方法扩展到多个点。
# 数据集x = [1.33, 0.3, 0.97, 1.1, 0.1, 1.4, 0.4]# 带宽h = 0.3对于第一个数据点,我们只需使用:
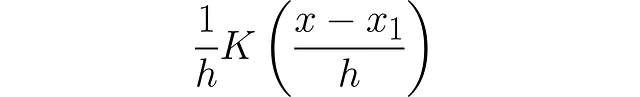

我们可以对第二个数据点做同样的操作:
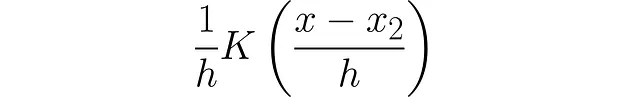
为了得到前两个点的单个PDF,我们必须将这两个单独的PDF组合起来:
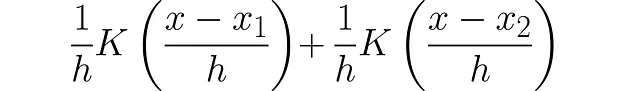
因为我们添加了两个面积为单位的PDF,曲线下的面积变为2。为了将其恢复为1,我们将其除以2:
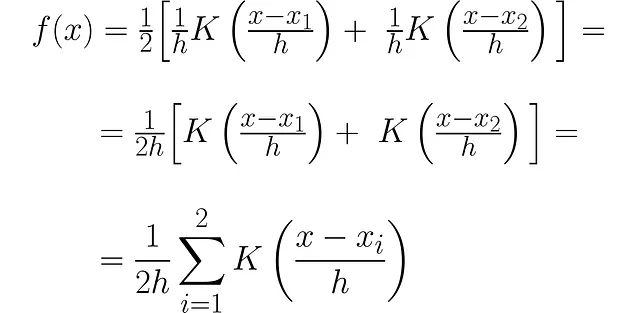
尽管函数f的完整签名可以用于精度:
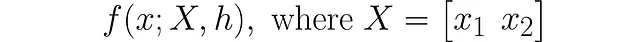
但我们将只使用f(x)以使符号清晰。
这是两个数据点的工作原理:
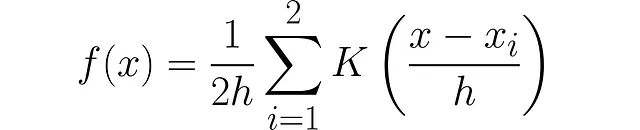
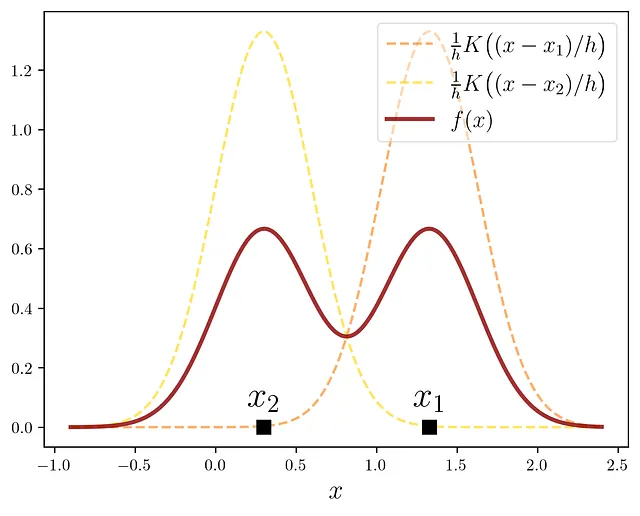
最后一步是考虑n个数据点
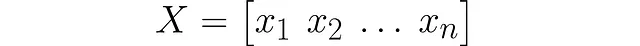
核密度估计是:
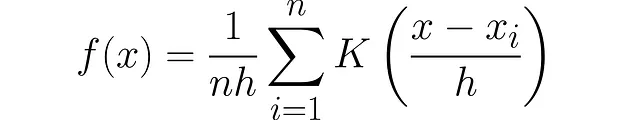
让我们用我们重新发现的KDE玩一玩。
import numpy as npimport matplotlib as plt# 核函数def K(x): return np.exp(-x**2/2)/np.sqrt(2*np.pi)# 虚拟数据集dataset = np.array([1.33, 0.3, 0.97, 1.1, 0.1, 1.4, 0.4])# 用于绘制KDE的x值范围x_range = np.linspace(dataset.min()-0.3, dataset.max()+0.3, num=600)# 用于实验的带宽值H = [0.3, 0.1, 0.03]n_samples = dataset.size# 不同带宽值的线属性color_list = ['goldenrod', 'black', 'maroon']alpha_list = [0.8, 1, 0.8]width_list = [1.7,2.5,1.7]plt.figure(figsize=(10,4))# 遍历带宽值for h, color, alpha, width in zip(H, color_list, alpha_list, width_list): total_sum = 0 # 遍历数据点 for i, xi in enumerate(dataset): total_sum += K((x_range - xi) / h) plt.annotate(r'$x_{}$'.format(i+1), xy=[xi, 0.13], horizontalalignment='center', fontsize=18, ) y_range = total_sum/(h*n_samples) plt.plot(x_range, y_range, color=color, alpha=alpha, linewidth=width, label=f'{h}') plt.plot(dataset, np.zeros_like(dataset) , 's', markersize=8, color='black') plt.xlabel('$x$', fontsize=22)plt.ylabel('$f(x)$', fontsize=22, rotation='horizontal', labelpad=20)plt.legend(fontsize=14, shadow=True, title='$h$', title_fontsize=16)plt.show()
这里我们使用了高斯核函数,但是我鼓励你尝试其他核函数。关于常见核函数家族的综述,请参阅这篇论文。然而,当数据集足够大时,核函数的类型对最终输出没有显著影响。
使用Python库进行KDE
seaborn库使用KDE来提供数据分布的美观可视化。
import seaborn as snssns.set()fig, ax = plt.subplots(figsize=(10,4))sns.kdeplot(ax=ax, data=dataset, bw_adjust=0.3, linewidth=2.5, fill=True)# 绘制数据点ax.plot(dataset, np.zeros_like(dataset) + 0.05, 's', markersize=8, color='black')for i, xi in enumerate(dataset): plt.annotate(r'$x_{}$'.format(i+1), xy=[xi, 0.1], horizontalalignment='center', fontsize=18, )plt.show()
Scikit learn提供了KernelDensity函数来完成类似的工作。
from sklearn.neighbors import KernelDensitydataset = np.array([1.33, 0.3, 0.97, 1.1, 0.1, 1.4, 0.4])# KernelDensity需要二维数组dataset = dataset[:, np.newaxis]# 将KDE拟合到数据集kde = KernelDensity(kernel='gaussian', bandwidth=0.1).fit(dataset)# 绘制KDE的x值范围x_range = np.linspace(dataset.min()-0.3, dataset.max()+0.3, num=600)# 计算每个样本的对数似然度log_density = kde.score_samples(x_range[:, np.newaxis])plt.figure(figsize=(10,4))# 在数据点上标注标签for i, xi in enumerate(dataset): plt.annotate(r'$x_{}$'.format(i+1), xy=[xi, 0.07], horizontalalignment='center', fontsize=18)# 绘制KDE曲线plt.plot(x_range, np.exp(log_density), color='gray', linewidth=2.5)# 绘制代表数据点的盒子plt.plot(dataset, np.zeros_like(dataset) , 's', markersize=8, color='black') plt.xlabel('$x$', fontsize=22)plt.ylabel('$f(x)$', fontsize=22, rotation='horizontal', labelpad=24)plt.show()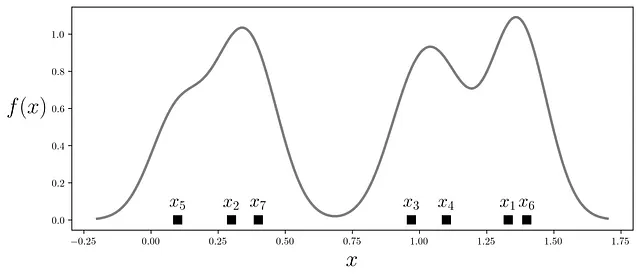
Scikit learn解决方案的优势在于可以将其用作生成模型来生成合成数据样本。
# 从模型中生成随机样本synthetic_data = kde.sample(100)plt.figure(figsize=(10,4))# 绘制KDE曲线plt.plot(x_range, np.exp(log_density), color='gray', linewidth=2.5)# 绘制代表数据点的盒子plt.plot(synthetic_data, np.zeros_like(synthetic_data) , 's', markersize=6, color='black', alpha=0.5) plt.xlabel('$x$', fontsize=22)plt.ylabel('$f(x)$', fontsize=22, rotation='horizontal', labelpad=24)plt.show()
结论
总之,KDE使我们能够从任何数据中创建出具有视觉吸引力的概率密度函数,而无需对底层过程做出任何假设。
KDE的显著特点:
- 这是由一种称为核函数的单一类型构建块组成的函数;
- 这是非参数估计,这意味着其功能形式由数据点确定;
- 生成的PDF的形状受到核带宽h值的影响;
- 为了拟合数据集,不需要优化技术。
对于多维数据的KDE应用是简单的。但这是另一个故事的主题。
除非另有说明,所有图片均为作者所创作。
参考资料
[1] S. Węglarczyk,核密度估计及其应用(2018),ITM web of conferences, vol. 23, EDP Sciences。
[2] Y. Soh, Y. Hae, A. Mehmood, R. H. Ashraf, I. Kim: 各种函数在核密度估计中的性能评估 (2013),Open Journal of Applied Sciences, vol. 3, pp. 58-64。