文档理解的进展
Progress in Document Understanding
Posted by Sandeep Tata, Software Engineer, Google Research, Athena Team
近年来,自动处理复杂业务文件并将其转化为结构化对象的系统取得了快速进展。能够自动从文件中提取数据(例如收据、保险报价和财务报表)的系统有潜力通过避免容易出错的手工工作来显著提高业务工作流程的效率。基于Transformer架构的最近模型在准确性方面取得了令人瞩目的进展。较大的模型,如PaLM 2,也被用于进一步简化这些业务工作流程。然而,学术文献中使用的数据集未能捕捉到真实世界用例中的挑战。因此,学术基准报告了强大的模型准确性,但这些模型在复杂的真实世界应用中表现不佳。
在 KDD 2023上发布的“VRDU: 用于视觉丰富文档理解的基准”中,我们宣布发布了新的视觉丰富文档理解(VRDU)数据集,旨在弥合这一差距,并帮助研究人员更好地跟踪文档理解任务的进展。我们列出了一个好的文档理解基准的五个要求,这些要求基于文档理解模型经常使用的真实世界文件的种类。然后,我们描述了目前由研究界使用的大多数数据集未能满足这些要求中的一个或多个,而VRDU则满足了所有这些要求。我们很高兴宣布以创作共用许可证公开发布VRDU数据集和评估代码。
基准要求
首先,我们比较了在真实世界用例中的最先进模型准确性(例如FormNet和LayoutLMv2)与学术基准(例如FUNSD、CORD、SROIE)的结果。我们观察到,最先进的模型与学术基准结果不匹配,并且在真实世界中准确性明显较低。接下来,我们将经常使用文档理解模型的典型数据集与学术基准进行了比较,并确定了五个数据集要求,这些要求允许数据集更好地捕捉到真实世界应用的复杂性:
- 丰富的模式:在实践中,我们看到了各种各样的用于结构化提取的丰富模式。实体具有不同的数据类型(数字、字符串、日期等),在单个文档中可能是必需的、可选的或重复的,甚至可能是嵌套的。对于简单的扁平模式(标题、问题、答案)的提取任务并不能反映出实践中遇到的典型问题。
- 丰富的布局文档:文档应具有复杂的布局元素。实际环境中的挑战来自于文档可能包含表格、键值对、单列和双列布局之间的切换、不同部分的不同字体大小、带有标题和脚注的图片等。与大多数文档组织在句子、段落和章节与部分标题之间的数据集相比,这些数据集通常是经典自然语言处理文献关于长输入的重点。
- 多样的模板:基准应包含不同的结构布局或模板。对于高容量模型来说,通过记住结构,从特定模板中提取是微不足道的。然而,在实践中,需要能够推广到新的模板/布局,这是基准中的训练-测试分割应该衡量的能力。
- 高质量的OCR:文档应具有高质量的光学字符识别(OCR)结果。我们这个基准的目标是专注于VRDU任务本身,并排除由OCR引擎选择带来的变化。
- 标记的令牌级别:文档应包含可以映射回相应输入文本的地面真值注释,以便每个令牌都可以作为相应实体的一部分进行注释。这与仅提供要提取的值的文本不同。这是生成干净训练数据的关键,我们不必担心与给定值的偶然匹配。例如,在某些收据中,如果税额为零,则“税前总额”字段可能与“总额”字段具有相同的值。令牌级别的注释可以防止我们生成训练数据,其中两个匹配值的实例都被标记为“总额”字段的地面真值,从而产生噪声示例。
 |
VRDU数据集和任务
VRDU数据集是两个公开可用数据集(Registration Forms和Ad-Buy forms)的组合。这些数据集提供了代表实际用例的示例,并满足上述提到的五个基准要求。
Ad-Buy Forms数据集包含641个政治广告详细信息的文档。每个文档都是电视台和竞选团队签署的发票或收据。这些文档使用表格、多列和键值对来记录广告信息,如产品名称、播出日期、总价和发布日期和时间。
Registration Forms数据集包含1915个有关注册美国政府的外国代理人的文档。每个文档记录了有关从事需要公开披露活动的外国代理人的基本信息。内容包括注册人的姓名、相关机构的地址、活动目的和其他细节。
我们从公共的联邦通信委员会(FCC)和外国代理人登记法案(FARA)网站中随机选取了一些文档,并使用Google Cloud的OCR将图像转换为文本。我们丢弃了一些长度超过两分钟无法处理完毕的文档。这样做还可以避免发送非常长的文档进行手动标注,因为对于单个文档来说,这项任务可能需要一个多小时的时间。然后,我们为一组有经验的文档标注者定义了架构和相应的标注指导。
我们还向标注者提供了一些我们自己标注的示例文档。任务要求标注者检查每个文档,为架构中的每个实体绘制一个边界框,并将该边界框与目标实体关联起来。在首次标注后,我们指派了一组专家来审查结果。修正后的结果包含在发布的VRDU数据集中。有关标注协议和每个数据集的架构的更多详细信息,请参阅论文。
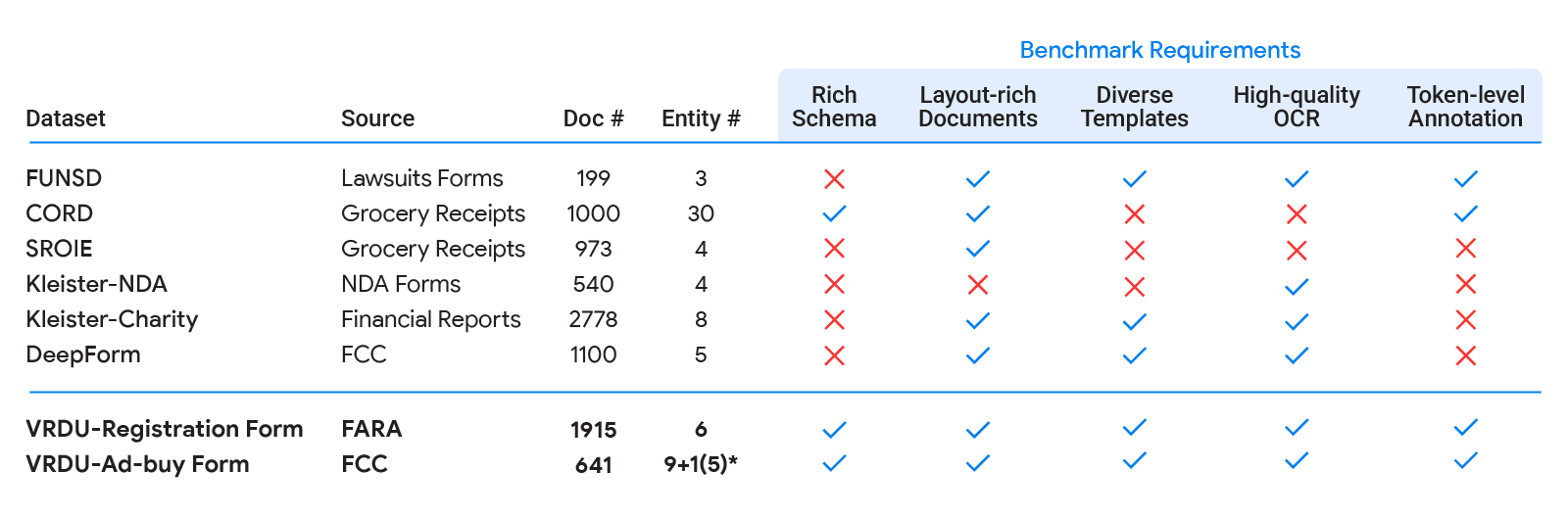 |
| 现有的学术基准(FUNSD、CORD、SROIE、Kleister-NDA、Kleister-Charity、DeepForm)在我们为良好的文档理解基准识别的五个要求中某些方面表现不佳。VRDU满足所有这些要求。请参阅我们的论文,了解有关这些数据集的背景以及它们不满足一个或多个要求的讨论。 |
我们使用10、50、100和200个样本分别构建了四个不同的模型训练集。然后,我们使用三个任务(如下所述)评估了VRDU数据集:(1)单一模板学习,(2)混合模板学习,(3)未知模板学习。对于每个任务,我们在测试集中包含了300个文档。我们使用测试集上的F1分数来评估模型。
- 单一模板学习(STL):这是最简单的情况,训练、测试和验证集仅包含一个模板。这个简单的任务旨在评估模型处理固定模板的能力。自然地,我们预期这个任务的F1分数非常高(0.90+)。
- 混合模板学习(MTL):这个任务类似于大多数相关论文使用的任务:训练、测试和验证集都包含属于同一组模板的文档。我们从数据集中随机抽取文档,并构建分割,以确保每个模板的分布在抽样过程中没有改变。
- 未知模板学习(UTL):这是最具挑战性的设置,我们评估模型是否能够推广到未知模板。例如,在Registration Forms数据集中,我们使用其中三个模板对模型进行训练,然后使用剩下的一个模板对模型进行测试。训练、测试和验证集中的文档来自不同的模板集合。据我们所知,以前的基准和数据集没有明确提供这样的任务,旨在评估模型对训练过程中未见过的模板的推广能力。
目标是能够在数据效率上评估模型。在我们的论文中,我们使用STL、MTL和UTL任务比较了两个最近的模型,并得出了三个观察结果。首先,与其他基准测试不同,VRDU具有挑战性,并显示出模型有很大的改进空间。其次,我们显示即使是最先进的模型的少样本性能也出奇的低,即使是最好的模型也只能得到小于0.60的F1分数。第三,我们显示模型在处理结构化重复字段方面存在困难,并且在这些字段上的表现特别差。
结论
我们发布了新的“视觉丰富的文档理解(VRDU)”数据集,以帮助研究人员更好地追踪文档理解任务的进展。我们描述了为什么VRDU更好地反映了这个领域的实际挑战。我们还展示了VRDU任务具有挑战性,并且与文献中通常使用的数据集相比,最近的模型有很大的改进空间,典型的F1分数为0.90+。我们希望发布VRDU数据集和评估代码能够帮助研究团队推动文档理解技术的最新进展。
致谢
非常感谢与Sandeep Tata共同撰写论文的Zilong Wang、Yichao Zhou、Wei Wei和Chen-Yu Lee。感谢Marc Najork、Riham Mansour以及Google Research和Cloud AI团队的众多合作伙伴提供宝贵的见解。感谢John Guilyard在本文中创建动画。