从原始到精细:数据预处理之旅-第一部分
数据预处理之旅-第一部分
有时候,我们用于机器学习任务的数据并不适合使用Scikit-Learn或其他机器学习库进行编码。因此,我们需要处理数据,将其转换为所需的格式。
原始数据可能存在各种问题。根据问题的性质,我们需要使用适当的方法来处理。
让我们看看这些方法以及如何在代码中实现它们。
均值移除和方差缩放(标准化)
Scikit-Learn估计器(估计器是指用于训练机器学习模型的Scikit-Learn类)被调整为在标准正态分布数据上工作最佳,即具有零均值和单位方差的高斯分布。
原始数据可能不总是符合高斯分布,因此在这些数据上训练的模型可能会给出次优结果。标准化操作可能是解决这个问题的方法。
标准化使用以下公式进行:

首先,计算一列的均值和标准差。然后,从该列中的每个数据点中减去均值。最后,将减法的结果除以标准差。
让我们看看如何在代码中实现这一点。
为了演示,让我们使用著名的“小费”数据集。该数据集用于根据不同因素(如总账单、顾客的性别、星期几、一天中的时间等)来预测侍者获得的小费。
## 导入所需的库import warningswarnings.filterwarnings('ignore')import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline
## 加载数据集df = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/tips.csv')## 查看部分数据df.head()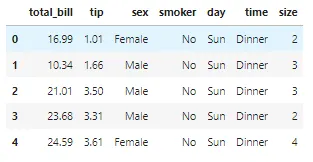
首先,我们需要将依赖特征(即‘total_bill’)与独立特征分开。然后,我们需要将数据分割为训练集和测试集。
## 导入所需的方法from sklearn.model_selection import train_test_split## 分离依赖和独立特征X, y = df.drop('total_bill', axis=1), df['total_bill']## 分离训练和测试数据X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)让我们对“tip”列执行标准缩放。
from sklearn.preprocessing import StandardScaler## 计算列的均值和标准差scaler = StandardScaler().fit(np.array(X_train['tip']).reshape(-1,1))## 使用计算得到的均值和标准差转换数据tips_transformed = scaler.transform(np.array(X_test['tip']).reshape(-1,1))tips_transformed[:10]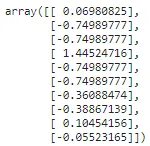
由于fit和transform方法需要一个二维数组作为输入,所以使用“reshape”方法将一维数组转换为二维数组。
将特征缩放到范围内(MinMaxScaler和MaxAbsScaler)
这是标准化的另一种方法,其中特征被缩放到最小值和最大值之间,通常在零和一之间,或者使得每个特征的最大绝对值缩放为单位大小。
如果我们想使用MinMaxScaler将数据缩放到“min”和“max”值之间,可以使用以下公式:

MinMaxScaler:
from sklearn.preprocessing import MinMaxScaler## 计算列的均值和标准差mm_scaler = MinMaxScaler().fit(np.array(X_train['tip']).reshape(-1,1))## 使用计算得到的均值和标准差转换数据tips_transformed = mm_scaler.transform(np.array(X_test['tip']).reshape(-1,1))tips_transformed[:10]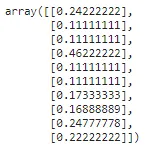
MaxAbsScaler的工作方式类似,但它将数据缩放到每个特征值在[-1,1]范围内。这是通过将每个值除以每个特征中的最大值来实现的。
将数据居中会破坏数据的稀疏性,并且通常不是一个合适的做法。但是在特征具有不同的尺度的情况下,对稀疏输入进行缩放是有意义的。MaxAbsScaler专门用于缩放稀疏数据,并且是一种推荐的方法。
MaxAbsScaler:
from sklearn.preprocessing import MaxAbsScaler## 计算列的均值和标准差ma_scaler = MaxAbsScaler().fit(np.array(X_train['tip']).reshape(-1,1))## 使用计算得到的均值和标准差转换数据tips_transformed = ma_scaler.transform(np.array(X_test['tip']).reshape(-1,1))tips_transformed[:10]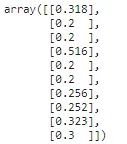
使用RobustScaler缩放具有异常值的数据
如果数据中有异常值,则均值和标准差的值可能会偏斜。在这种情况下,均值和标准差值将不能正确表示数据的中心或数据的分布。因此,在数据存在异常值时使用均值和标准差进行缩放效果不好。
为了解决这个问题,我们可以使用RobustScaler,它使用更健壮的估计值来计算数据的中心和范围。
from sklearn.preprocessing import RobustScaler## 计算列的均值和标准差r_scaler = RobustScaler().fit(np.array(X_train['tip']).reshape(-1,1))## 使用计算得到的均值和标准差转换数据tips_transformed = r_scaler.transform(np.array(X_test['tip']).reshape(-1,1))tips_transformed[:10]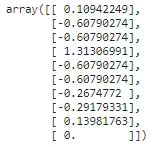
将数据映射到均匀分布(QuantileTransformer)
可以使用QuantileTransformer将数据映射到介于0和1之间的均匀分布的值。
from sklearn.preprocessing import QuantileTransformerq_transformer = QuantileTransformer().fit(np.array(X_train['tip']).reshape(-1,1))xtrain_transformed = q_transformer.transform(np.array(X_train['tip']).reshape(-1,1))现在,让我们可视化转换前后的“tip”列。
dataframe = pd.DataFrame()dataframe['tips_given'] = X_train['tip']dataframe['tips_uniformDist'] = xtrain_transformedsns.set_style('darkgrid')plt.figure(figsize=(10,5))for index, feature in enumerate(dataframe.columns): plt.subplot(1,2,index+1) sns.distplot(dataframe[feature],kde=True, color='b') plt.xlabel(feature) plt.ylabel('distribution') plt.title(f"{feature} distribution")plt.tight_layout()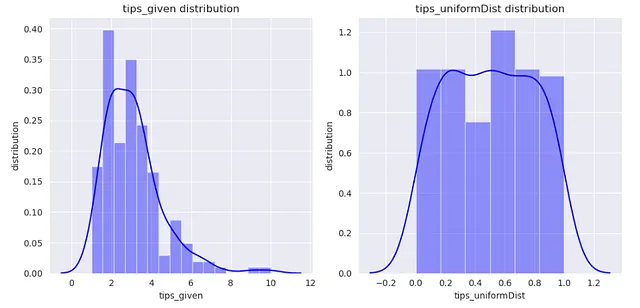
将数据映射到高斯分布(PowerTransformer)
我们可以使用PowerTransformer将数据映射到接近高斯分布的分布。
我们可以从以下两种方法中选择用于进行此转换的方法:
- Box-cox变换
- Yeo-Johnson变换
请注意,Box-Cox变换只能应用于正数数据。
Box-Cox变换:
from sklearn.preprocessing import PowerTransformerp_transformer = PowerTransformer(method='box-cox').fit(np.array(X_train['tip']).reshape(-1,1))xtrain_transformed = p_transformer.transform(np.array(X_train['tip']).reshape(-1,1))
dataframe = pd.DataFrame()dataframe['tips_given'] = X_train['tip']dataframe['tips_NormalDist'] = xtrain_transformedsns.set_style('darkgrid')plt.figure(figsize=(10,5))for index, feature in enumerate(dataframe.columns): plt.subplot(1,2,index+1) sns.distplot(dataframe[feature],kde=True, color='y') plt.xlabel(feature) plt.ylabel('distribution') plt.title(f"{feature} distribution")plt.tight_layout()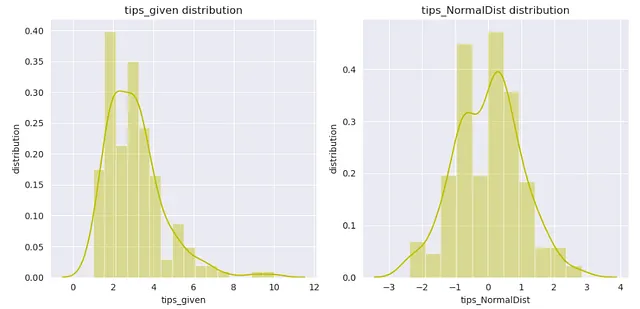
Yeo-Johnson变换:
from sklearn.preprocessing import PowerTransformerp_transformer = PowerTransformer(method='yeo-johnson').fit(np.array(X_train['tip']).reshape(-1,1))xtrain_transformed = p_transformer.transform(np.array(X_train['tip']).reshape(-1,1))
dataframe = pd.DataFrame()dataframe['tips_given'] = X_train['tip']dataframe['tips_NormalDist'] = xtrain_transformedsns.set_style('darkgrid')plt.figure(figsize=(10,5))for index, feature in enumerate(dataframe.columns): plt.subplot(1,2,index+1) sns.distplot(dataframe[feature],kde=True, color='g') plt.xlabel(feature) plt.ylabel('distribution') plt.title(f"{feature} distribution")plt.tight_layout()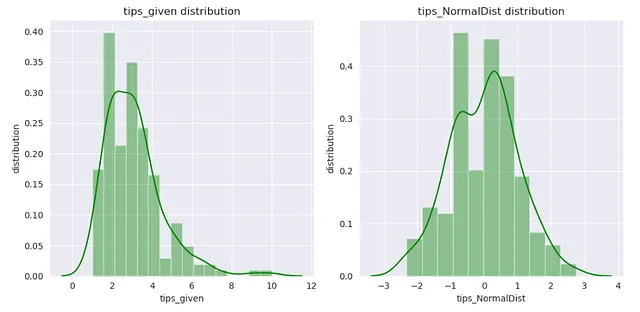
希望你喜欢这篇文章。如果对文章有任何想法,请告诉我。此外,请继续关注本预处理系列中即将发布的文章。
与我联系:
领英
个人网站
给我发邮件至[email protected]
祝你有美好的一天!





