“释放文本的潜力:对预嵌入文本清理方法的深入研究”
Exploring Pre-embedded Text Cleaning Methods to Unleash the Potential of Text
本文将讨论不同的清洗技术,这些技术对于从文本数据中获得最佳性能至关重要。
为了演示文本清洗方法,我们将使用来自Kaggle的名为“metamorphosis”的文本数据集。
让我们从导入清洗过程所需的Python库开始。
import nltk, re, stringfrom nltk.corpus import stopwordsfrom nltk.stem.porter import PorterStemmer现在让我们加载数据集。
file_directory = '链接到数据集本地目录'file = open(file_directory, 'rt', encoding='utf-8')text = file.read()file.close()请注意,为了使上面的代码单元格正常工作,您需要放置数据文件的本地目录路径。
将文本数据按空格拆分为单词
words = text.split()print(words[:120])
在这里,我们看到标点符号被保留(例如armour-like和wasn’t),这很好。我们还可以看到句子结束的标点符号与最后一个单词保持在一起(例如,thought.),这不太好。
因此,这次让我们尝试使用非单词字符来拆分数据。
words = re.split(r'\W+', text)print(words[:120])
在这里,我们可以看到像‘thought.’这样的单词已被转换为‘thought’。但问题在于像‘wasn’t’这样的单词被转换为‘wasn’和‘t’两个单词。我们需要修复它。
在Python中,我们可以使用string.punctuation一次获取一堆标点符号。我们将使用它来从文本中删除标点符号。
print(string.punctuation)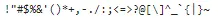
所以现在我们将通过空格拆分单词,然后删除在数据中记录的所有标点符号
words = text.split()re_punc = re.compile('[%s]' % re.escape(string.punctuation))stripped = [re_punc.sub('', word) for word in words]print(stripped[:120])
在这里,我们可以看到没有像‘thought.’这样的单词,但我们也有像‘wasn’t’这样的单词,这是正确的。
有时文本还包含不可打印的字符。我们也需要过滤掉这些字符。为此,我们可以使用Python的‘string.printable’,它给出了一堆可以打印的字符。因此,我们将删除不在此列表中的字符。
re_print = re.compile('[^%s]' % re.escape(string.printable))result = [re_print.sub('', word) for word in stripped]print(result[:120])
现在让我们将所有单词变为小写。这将减少我们的词汇量。但这也有一些缺点。在这样做之后,像作为公司的‘Apple’和作为水果的‘apple’将被视为相同的实体。
result = [word.lower() for word in result]print(result[:120])
此外,只有一个字符的单词对大多数NLP任务没有贡献。因此,我们也会将它们删除。
result = [word for word in result if len(word) > 1]print(result[:120])
在NLP中,像’is’、’as’、’the’这样的频繁单词对模型训练的贡献不大。因此,这些单词被称为停用词,并建议在文本清理过程中将其删除。
import nltkfrom nltk.corpus import stopwordsstop_words = stopwords.words('english')print(stop_words)
result = [word for word in result if word not in set(stop_words)]print(words[:110])
现在,在此时点上,我们将具有相同意图的单词缩减为一个单词。例如,我们将’running’、’run’和’runs’这三个单词缩减为只有一个单词’run’,因为这三个单词在模型训练期间给出相同的意义。可以使用nltk库中的PorterStemmer类来执行此操作。
from nltk.stem.porter import PorterStemmerps = PorterStemmer()result = [ps.stem(word) for word in result]print(words[:110])
词干化的单词可能有意义,也可能没有意义。如果您希望单词有意义,那么可以使用词形还原技术,它保证转换后的单词具有意义。
现在让我们删除不只由字母组成的单词
result = [word for word in result if word.isalpha()]print(result[:110])
在这个阶段,文本数据看起来足够好,可以用于词嵌入技术。但请注意,对于某些特殊类型的数据(例如HTML代码),可能还有一些额外的步骤。
希望您喜欢这篇文章。如果对文章有任何想法,请告诉我。非常感谢任何建设性的反馈。
与我联系LinkedIn。
给我发邮件 [email protected]
祝您有美好的一天!






