从原始到精细:数据预处理之旅——第3部分:重复数据
数据预处理之旅:重复数据
本文将解释如何在数据中识别重复记录,并介绍处理重复记录问题的不同方法。
为什么数据中存在重复记录是一个问题?
许多程序员经常忽视数据中重复值的存在。但是,处理数据中的重复记录非常重要。
存在重复记录可能导致错误的数据分析和决策。
例如,在具有重复记录的数据中用平均值替换缺失值(插补)会发生什么?
在这种情况下,可能会使用不正确的平均值进行插补。让我们举个例子。
考虑以下数据。数据包含两列,即姓名和体重。请注意,’John’的体重值重复。而且,’Steve’的体重值缺失。
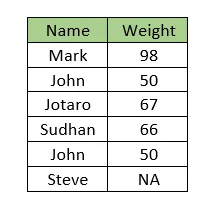
如果希望使用所有体重值的平均值来插补Steve的缺失体重值,则使用的插补值将是不正确的,即
(98 + 50 + 67 + 66 + 50)/5 = 66.2
但是,通过忽略重复值得出的实际平均值是
(98 + 50 + 67 + 66)/4 = 70.25
因此,如果我们不对重复记录进行处理,那么缺失值将被错误地插补。
此外,重复值甚至可能影响使用此类错误数据做出的业务决策。
总之,应该处理数据中的重复记录,以保持数据的完整性。
现在,让我们看看处理数据中重复记录的不同方法。
识别数据中的重复值
我们可以使用pandas的duplicated方法来识别数据中重复的行。
现在,让我们通过一个示例来了解重复值。
## 导入所需库import numpy as npimport pandas as pdimport warningswarnings.filterwarnings('ignore')## 创建一个数据框Name = ['Mark', 'John', 'Jotaro', 'Mark', 'John', 'Steve']Weight = [98, 50, 67, 66, 50, np.nan]Height = [170, 175, 172, 170, 175, 166]df = pd.DataFrame()df['Name'] = Namedf['Weight'] = Weightdf['Height'] = Heightdf
识别重复值:
## 识别重复值(默认行为)df.duplicated()
我们得到了True的值,表示存在重复记录的位置,而False表示唯一记录的位置。
请注意,默认情况下,duplicated()方法使用所有列来查找重复记录。但是,我们也可以使用列的子集来查找重复项。为此,duplicated()方法有一个名为subset的参数。subset参数接受我们要用于查找重复项的列名列表。
## duplicated()方法的subset参数df.duplicated(subset=['Name','Height'])
另外,duplicated() 方法还有一个更重要的参数,名为 keep。keep 参数的值决定我们在所有重复记录中将第一条记录还是最后一条记录视为唯一记录。我们还有一个选项,可以将所有重复记录视为非唯一。
keep = ‘first’:在所有重复记录中,将第一条记录视为唯一
keep = ‘last’:在所有重复记录中,将最后一条记录视为唯一
keep = False:将所有重复记录视为非唯一。
## duplicated() 方法的 keep 参数df.duplicated(keep='first')
请注意,第一个重复值(索引为1)被视为唯一,其他所有重复值(索引为4)被视为重复。
## duplicated() 方法的 keep 参数df.duplicated(keep='last')
请注意,最后一个重复值(索引为4)被视为唯一,其他所有重复值(索引为1)被视为重复。
## duplicated() 方法的 keep 参数df.duplicated(keep=False)
请注意,所有重复记录(索引为1和索引为4)都被显示。
如何处理数据中的重复记录
在识别出重复记录之后的下一步是处理它们。
处理数据中重复记录的方法有两种。
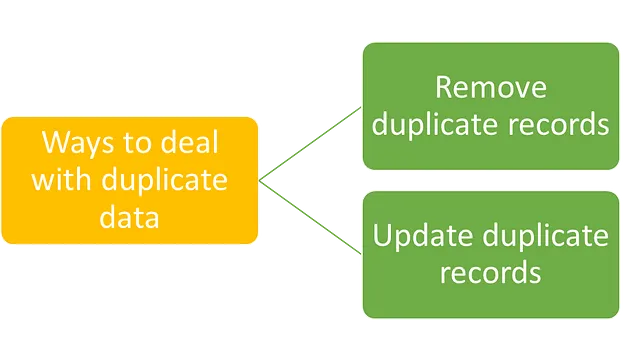
删除重复记录
让我们从删除重复记录的方法开始。
我们可以使用 pandas 的 drop_duplicates() 方法来实现这一点。
默认情况下,drop_duplicates() 方法保留所有重复记录集合中的第一条记录,然后从数据中删除其余的重复记录。此外,默认情况下,drop_duplicates() 方法使用所有列来识别重复记录。
但是,可以使用 drop_duplicates() 方法的两个参数更改此默认行为。它们分别是
- keep
- subset
它们的工作原理与 duplicated() 方法的 keep 和 subset 参数完全相同。
"""使用 pandas 的 drop_duplicates() 方法删除重复值(默认行为)"""df1 = df.drop_duplicates()df1
"""使用 pandas 的 drop_duplicates() 方法删除重复值,并使用 subset 和 keep 参数进行自定义行为"""df2 = df.drop_duplicates(subset=['Weight'], keep='last')df2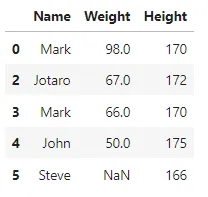
更新重复记录
有时,我们希望用某个值替换重复记录。假设我们发现了两个重复记录,然后得知获取数据的人在其中一条重复记录中错误地输入了错误的姓名。那么在这种情况下,我们希望将正确人员的姓名放入其中。这样就解决了重复值的问题。
df.duplicated(keep=False)
在这里,我们在索引1和4处有重复的记录。现在,如果我们更改索引1处的‘Name’列的值,那么我们将不再有重复的值。
## 更改第一个重复记录的‘Name’值df.iloc[1, 0] = 'Dio' df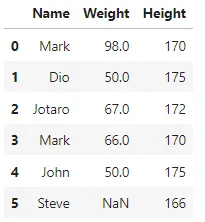
我们更改了第一个重复记录的‘Name’值。现在,让我们再次检查数据中是否存在重复的记录。
df.duplicated()
现在,我们没有任何重复的记录。
谢谢阅读!如果您对文章有任何想法,请告诉我。
您正在为选择下一篇文章而苦恼吗?别担心,我知道一篇我相信您会觉得有趣的文章。
从原始到精炼:数据预处理之旅——第2部分:缺失值
为什么要处理缺失值?
pub.towardsai.net
还有一个…
从原始到精炼:数据预处理之旅——第1部分:特征缩放
有时,我们为机器学习任务收到的数据不适合使用Scikit-Learn编码…
pub.towardsai.net
Shivam Shinde
- 与我联系 LinkedIn
- 同样,您可以在 VoAGI 上关注我
祝您有美好的一天!
参考资料:
处理Pandas数据框中的重复值
作为数据分析师,我们有责任确保数据完整性,以获得准确可靠的见解。数据…
stackabuse.com
根据所有或选定的列在数据框中查找重复行-GeeksforGeeks
GeeksforGeeks的计算机科学门户。其中包含精心编写、深思熟虑和简明扼要的计算机科学和…
www.geeksforgeeks.org
Pandas DataFrame duplicated()方法
W3Schools提供免费的在线教程、参考资料和练习,涵盖了网络上所有主要语言。涵盖…
www.w3schools.com