GPT-4:一机八模型;秘密揭晓
GPT-4 Eight models in one machine; secret revealed
GPT4模型到目前为止一直是具有突破性的模型,可供公众免费使用或通过他们的商业门户(用于公共测试版使用)。它在激发许多企业家的新项目创意和用例方面取得了惊人的成果,但关于参数数量和模型的保密性正在杀死所有对第一个1万亿参数模型到100万亿参数声索抱有期望的爱好者!
猫已经脱离袋子
好吧,猫已经脱离袋子(某种程度上)。在6月20日,自动驾驶初创公司Comma.ai的创始人George Hotz泄露了GPT-4不是单个的块状密集模型(如GPT-3和GPT-3.5),而是由8个2200亿参数模型混合而成。
当天晚些时候,Meta的PyTorch联合创始人Soumith Chintala证实了这一泄露。
就在前一天,微软Bing AI主管Mikhail Parakhin也暗示了这一点。
GPT 4:不是单体
所有这些推文是什么意思?GPT-4不是单个的大型模型,而是共享专业知识的8个较小模型的联合/集成。据传每个模型的参数为2200亿。

该方法被称为专家混合模型范例(下面链接)。这是一种众所周知的方法,也称为模型的九头蛇。这让我想起了印度神话中的拉瓦纳。
请注意,这不是官方新闻,但AI社区中地位显赫的成员已经对此发表/暗示了意见。微软尚未确认其中任何一条。
什么是专家混合范例?
既然我们已经谈到了专家混合,让我们稍微深入了解一下。专家混合是一种专门为神经网络开发的集成学习技术。它与传统机器学习建模中的一般集成技术有所不同(那是一种广义形式)。因此,您可以将LLMs中的专家混合视为集成方法的特例。
简而言之,该方法将一个任务分解为子任务,并使用各个子任务的专家来解决模型。这是一种在创建决策树时采用分而治之的方法。一个可以考虑它是在每个单独的任务上的专家模型之上的元学习。
可以为每个子任务或问题类型训练一个更小且更好的模型。元模型学习使用哪个模型更适合预测特定任务。元学习器/模型充当交通警察。子任务可能重叠,也可能不重叠,这意味着可以将输出的组合合并在一起得出最终输出。
有关MOE到Pooling的概念描述,所有的荣誉归功于Jason Brownlee的精彩博客(https://machinelearningmastery.com/mixture-of-experts/)。如果您喜欢下面的内容,请务必订阅Jason的博客并购买一两本书以支持他的出色工作!
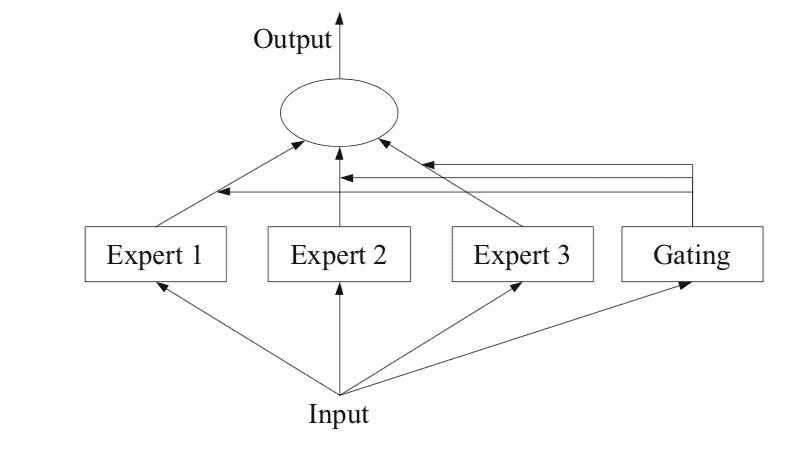
专家混合,简称MoE或ME,是一种实施在预测建模问题的子任务上训练专家的集成学习技术。
在神经网络界,已经有几位研究人员研究了分解方法。[…]混合专家(ME)方法将输入空间分解,以便每个专家检查空间的不同部分。[…]一个门控网络负责组合各个专家。
——《模式分类使用集成方法》,2010年第73页。
该方法有四个要素:
- 将任务分解为子任务。
- 为每个子任务开发一个专家。
- 使用门控模型来决定使用哪个专家。
- 汇总预测和门控模型输出以进行预测。
下面的图表摘自2012年的书籍《集成方法》第94页,对该方法的架构要素提供了有益的概述。
GPT4中的8个较小模型是如何工作的?
秘密的“专家模型”已经揭晓,让我们了解为什么GPT4如此出色!
ithinkbot.com
子任务
第一步是将预测建模问题划分为子任务。这通常涉及使用领域知识。例如,可以将图像划分为背景、前景、对象、颜色、线条等独立元素。
… ME以分而治之的策略工作,将复杂任务分解为若干较简单和较小的子任务,并为不同的子任务训练各自的学习器(称为专家)。
— 《集成方法》,2012年,第94页。
对于那些无法明显将任务划分为子任务的问题,可以采用更简单和通用的方法。例如,可以想象一种方法,通过列组或基于距离度量、内点、外点等将输入特征空间划分,根据标准分布分隔特征空间中的示例等。
… 在ME中,一个关键问题是如何找到任务的自然划分,然后从子解决方案中推导出整体解决方案。
— 《集成方法》,2012年,第94页。
专家模型
接下来,为每个子任务设计一个专家模型。
专家混合方法最初在人工神经网络领域中开发和探索,因此传统上,专家本身是用于预测数值(回归问题)或类别标签(分类问题)的神经网络模型。
应该清楚的是,我们可以“插入”任何模型作为专家。例如,我们可以使用神经网络来表示门控函数和专家。结果被称为混合密度网络。
— 《机器学习:概率角度》,2012年,第344页。
每个专家接收相同的输入模式(行)并进行预测。
门控模型
一个模型用于解释每个专家所做的预测,并帮助决定对于给定的输入应该信任哪个专家。这被称为门控模型或门控网络,因为传统上它是一个神经网络模型。
门控网络以提供给专家模型的输入模式为输入,并输出每个专家在对输入进行预测时应该具有的贡献。
… 由门控网络确定的权重是根据给定的输入动态分配的,因为ME有效地学习了由每个集成成员学习的特征空间的哪一部分。
— 《集成机器学习》,2012年,第16页。
门控网络是该方法的关键,实际上,模型学习选择给定输入的子任务类型,并进而信任哪个专家进行强有力的预测。
混合专家模型也可以被看作是一个分类器选择算法,其中个别分类器被训练成成为特征空间的某些部分的专家。
— 《集成机器学习》,2012年,第16页。
当使用神经网络模型时,门控网络和专家一起进行训练,以便门控网络学习何时信任每个专家进行预测。这个训练过程通常使用期望最大化(EM)来实现。门控网络可能具有softmax输出,为每个专家提供像概率一样的置信度评分。
总的来说,训练过程试图实现两个目标:对于给定的专家,找到最佳的门控函数;对于给定的门控函数,根据门控函数指定的分布对专家进行训练。
— 第95页,《集成方法》,2012年。
汇聚方法
最后,专家模型的混合必须进行预测,可以通过汇聚或聚合机制实现。这可能就是简单地选择输出最大或由门控网络提供的置信度最高的专家。
或者,可以进行加权和预测,明确地结合每个专家的预测和门控网络估计的置信度。您可能会想象其他有效利用预测和门控网络输出的方法。
然后,汇聚/组合系统可以选择具有最高权重的单个分类器,或者对每个类别的分类器输出进行加权求和,并选择接收到最高加权和的类别。
— 第16页,《集成机器学习》,2012年。
切换路由
我们还应简要讨论切换路由方法与MoE论文的区别。我提出这个问题是因为微软似乎使用了切换路由而不是专家模型来节省一些计算复杂性,但我很乐意被证明是错误的。当存在多个专家模型时,它们可能对路由函数(何时使用哪个模型)具有非平凡的梯度。这个决策边界由切换层控制。
切换层的好处有三个。
- 如果令牌只被路由到单个专家模型,则可以减少路由计算
- 批次大小(专家容量)可以减半,因为单个令牌只被发送到单个模型
- 路由的实现简化且通信减少。
同一个令牌重叠到多个专家模型被称为容量因子。下面是不同专家容量因子的路由工作的概念描述
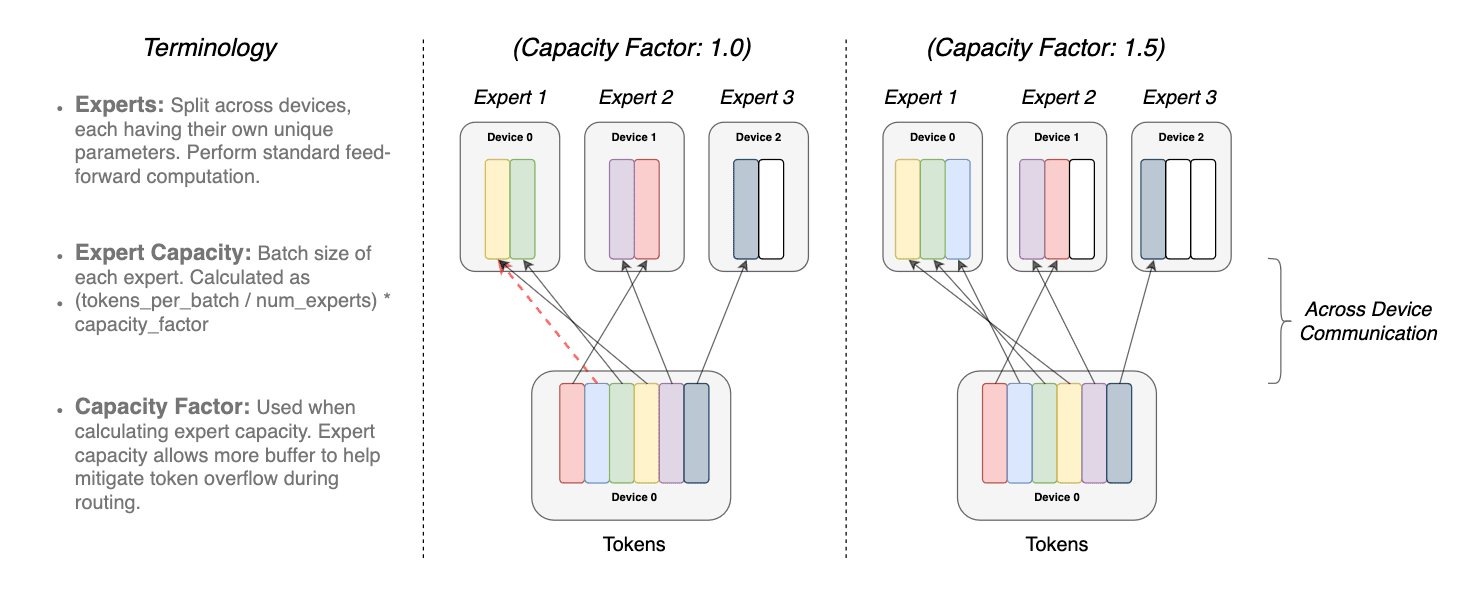
令牌通过容量因子调制。每个令牌被路由到具有最高路由器概率的专家,但每个专家的固定批次大小为
(总令牌数/专家数) × 容量因子。如果令牌被不均匀地分配,那么某些专家将溢出(由虚线红线表示),导致
这些令牌不被此层处理。较大的容量因子可以减轻这种溢出问题,但也会增加计算和通信成本
(由空白位置表示)。 (来源 https://arxiv.org/pdf/2101.03961.pdf)
与MoE相比,来自MoE和Switch论文的研究结果表明:
- 切换变形器在速度和质量的基础上优于精心调整的密集模型和MoE变形器。
- 切换变形器的计算资源占用更少。
- 切换变形器在较低的容量因子(1-1.25)下表现更好。

总结思考
有两个注意事项,首先,这些都是来自传闻,其次,我对这些概念的理解相当薄弱,所以我建议读者以谨慎的态度看待。
但是,微软通过保持这种架构的隐藏实现了什么?嗯,他们引起了轰动和悬念。这可能有助于他们更好地塑造他们的叙述。他们保留了创新,避免了其他人更早赶上他们。整个想法很可能是微软惯常的游戏计划,即在投资10亿美元的同时挫败竞争对手。
GPT-4的性能很棒,但它不是一种创新或突破性的设计。它是工程师和研究人员开发方法的巧妙实现,再加上企业/资本主义的部署。OpenAI既没有否认也没有同意这些说法(https://thealgorithmicbridge.substack.com/p/gpt-4s-secret-has-been-revealed),这让我认为GPT-4的这种架构很可能是现实(这很棒!)。只是不够酷!我们都想知道和学习。
非常感谢Alberto Romero将这一消息公之于众,并通过与OpenAI的联系进一步调查(根据最新更新,OpenAI未作回应)。我在LinkedIn上看到了他的文章,但该文章也在VoAGI上发布。
Dr. Mandar Karhade, MD. PhD. 高级分析和数据战略总监 @Avalere Health。Mandar是一位经验丰富的医学科学家,致力于将人工智能应用于生命科学和医疗保健行业的前沿实施工作已有10多年。Mandar还是AFDO/RAPS的一员,帮助监管医疗保健领域的人工智能应用。
原文,已获得许可重新发布。






