如何企业可以构建自己的大型语言模型类似于OpenAI的ChatGPT
如何构建类似于OpenAI的ChatGPT的大型语言模型
想要构建自己的ChatGPT吗?以下是三种可以实现的方法
介绍
近年来,语言模型在自然语言处理、内容生成和虚拟助手等领域引起了广泛关注,产生了革命性的影响。其中最著名的例子是OpenAI的ChatGPT,这是一个可以生成类人文本并进行交互对话的大型语言模型。这激发了企业的好奇心,引导它们探索构建自己的大型语言模型(LLM)的想法。
然而,决定开始构建LLM需要仔细评估。它需要大量的计算资源和数据可用性。企业必须权衡成本和收益,评估所需的技术专长,并评估其是否与其长期目标相一致。
在本文中,我们将向您展示构建类似于OpenAI的ChatGPT的三种构建自己的LLM的方法。通过阅读本文,您将更清楚地了解构建自己的大型语言模型所涉及的挑战、要求和潜在收益。那么让我们开始吧!
企业应该构建自己的LLM吗?
为了了解企业是否应该构建自己的LLM,让我们探讨一下它们可以利用这些模型的三种主要方式。
- 超越Numpy和Pandas:发掘较少知名的Python库的潜力
- 无人驾驶汽车的阴暗面:隐私入侵
- 一项新的谷歌AI研究提出使用一种名为Pairwise Ranking Prompting (PRP)的新技术,显著减轻LLMs的负担

1. 封闭源LLMs: 企业可以利用像OpenAI的ChatGPT、Google的Bard或其他不同供应商提供的现成的LLM服务。这些服务提供了一个即用的解决方案,使企业能够利用LLMs的强大功能,而无需进行大量的基础设施投资或技术专长。
优点:
- 快速、轻松部署,节省时间和精力。
- 在通用文本生成任务上表现良好。
缺点:
- 对模型的行为和响应的控制有限
- 在特定领域或企业特定数据上的准确性较低
- 由于数据发送给托管服务的第三方,存在数据隐私问题
- 依赖第三方供应商和潜在的定价波动。
2. 使用特定领域的LLMs: 另一种方法是使用特定领域的语言模型,例如用于金融的BloombergGPT,用于生物医学应用的BioMedLM,用于市场营销的MarketingGPT,用于电子商务应用的CommerceGPT等。这些模型是基于特定领域的数据进行训练的,可以在各自领域中提供更准确和定制的响应。
优点:
- 由于基于相关数据进行训练,在特定领域中的准确性得到了提高。
- 提供针对特定行业的预训练模型。
缺点:
- 在超出指定领域之外调整模型的灵活性有限。
- 依赖供应商的更新和特定领域模型的可用性。
- 准确性略有提高,但仍受限于不适用于企业数据的特定性
- 由于数据发送给托管服务的第三方,存在数据隐私问题
3. 构建和托管自定义LLM: 最全面的选择是企业根据自己的数据构建和托管自己的LLM。这种方法为生成的内容提供了最高级别的定制和隐私控制。它允许组织对模型进行微调以满足其独特要求,确保领域特定的准确性和与其品牌声音的协调。
优点:
- 完全定制和控制:自定义模型使企业能够生成与其品牌声音、行业特定术语和独特要求完全一致的响应。
- 成本效益:如果正确设置(微调成本在数百美元的订单),具有成本效益
- 透明:企业了解整个数据和模型
- 最佳准确性:通过对企业特定数据和要求进行训练,它可以更好地理解和响应企业特定的查询,从而产生更准确和上下文相关的输出。
- 保护隐私:数据和模型留在您的环境中。拥有自定义模型可以使企业保留对其敏感数据的控制,最大程度地减少与数据隐私和安全漏洞相关的担忧。
- 竞争优势:在个性化和准确的语言处理在关键角色中的行业中,自定义的大型语言模型可以成为重要的差异化因素。
缺点:
- 需要丰富的机器学习和大规模语言模型专业知识才能构建定制的大型语言模型
需要注意的是,构建定制的大型语言模型的方法取决于各种因素,包括企业的预算、时间限制、所需准确度以及所需的控制水平。然而,正如您从上面所看到的,基于企业特定数据构建定制的大型语言模型提供了许多好处。
定制的大型语言模型为特定领域、用例和企业需求提供了无与伦比的定制化、控制和准确性。因此,企业应该考虑构建自己的企业特定定制的大型语言模型,以解锁为其需求、行业和客户群体量身定制的无限可能。
构建自己的定制化大型语言模型的三种方法
您可以通过以下三种方式构建您的定制化大型语言模型,从低复杂度到高复杂度。
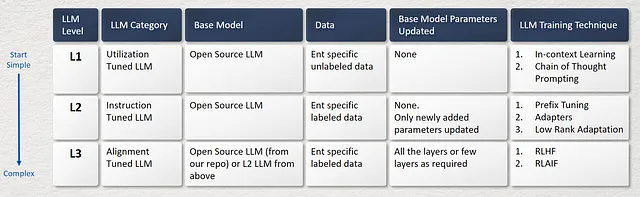
L1. 利用调优的大型语言模型
利用预训练的大型语言模型的一种普遍方法是设计有效的提示技术来解决各种任务。常见的提示方法之一是上下文学习(In-Context Learning,ICL),它涉及用自然语言文本表达任务描述和/或演示。此外,利用思维链(Chain-of-Thought,CoT)可以通过在提示中加入一系列中间推理步骤来增强上下文学习。构建L1大型语言模型的步骤如下:
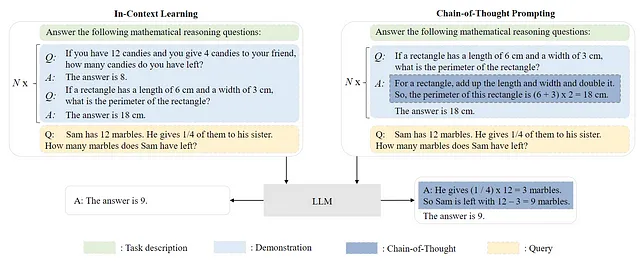
构建L1大型语言模型的步骤如下:
- 首先选择适合的预训练大型语言模型(可以在Hugging Face模型库或其他在线资源中找到),通过查看许可证确保其与商业用途兼容。
- 接下来,确定与您特定领域或用例相关的数据来源,组装一个涵盖各种主题和语言变体的多样且全面的数据集。对于L1大型语言模型,不需要带标签的数据。
- 在定制化过程中,所选择的预训练大型语言模型的模型参数保持不变。而是采用提示工程技术来将大型语言模型的响应调整为数据集的要求。
- 如上所述,上下文学习和思维链提示是两种常用的提示工程方法。这些技术统称为资源高效调优(Resource Efficient Tuning,RET),可以在不需要大量基础设施资源的情况下获得响应。
L2. 指令调优的大型语言模型
指令调优是在以自然语言形式的格式化实例集合上对预训练大型语言模型进行微调的方法,与监督式微调和多任务提示训练密切相关。通过指令调优,大型语言模型可以根据新任务的任务指令进行操作,而无需使用明确的示例(类似于零-shot能力),从而提高了泛化能力。构建这种指令调优的L2大型语言模型的步骤如下:
- 首先选择适合的预训练大型语言模型(可以在Hugging Face模型库或其他在线资源中找到),通过查看许可证确保其与商业用途兼容。
- 接下来,确定与目标领域或用例相关的数据来源。需要一个包含各种适用于您领域或用例的指令的带标签数据集。例如,您可以参考Databricks提供的dolly-15k数据集,该数据集提供了不同格式的指令,如封闭问答、开放问答、分类、信息检索等。该数据集可以作为构建您自己的指令数据集的模板。
- 在监督式微调过程中,我们向步骤1中选择的原始基础大型语言模型引入新的模型参数。通过添加这些参数,我们可以训练模型进行特定的时期,以针对给定的指令进行微调。这种方法的优点是避免了更新基础大型语言模型中数十亿个参数的需要,而是专注于较少数量的附加参数(数千或数百万个),同时仍然能够在所需任务中获得准确的结果。这种方法还有助于降低成本。
- 下一步是进行微调。关于这些的各种微调技术,如前缀微调、适配器、低秩注意机制等,将在未来的文章中详细阐述。上述点3中讨论的添加新模型参数的过程也依赖于这些技术。有关更详细的信息,请参阅参考文献部分。这些技术属于参数高效微调(Parameter Efficient Fine Tuning,PEFT)的范畴,因为它们可以在不更新所有基础大型语言模型的参数的情况下进行定制。
L3. 对齐调谐的LLM
由于LLM被训练来捕捉预训练语料库的数据特征(包括高质量和低质量的数据),它们很可能会为人类生成有毒、有偏见甚至有害的内容。因此,将LLM与人类价值观对齐可能是必要的,例如,有益、诚实和无害。为了实现这种对齐目的,我们使用强化学习与人类反馈(RLHF)的技术,这是一种有效的调谐方法,使LLM能够遵循预期的指令。它通过精心设计的标注策略将人类纳入训练循环中。为了构建这种对齐调谐的L3 LLM,
- 首先选择一个开源的预训练LLM(可以在Hugging Face模型库或其他在线资源中找到)或者将您的L2 LLM作为基本模型。
- 构建对齐调谐的LLM的主要技术是RLHF,它结合了监督学习和强化学习。它从特定领域或指令语料库(来自步骤1)上获取经过微调的LLM,并使用它生成回复。然后,使用人类对这些回复进行注释,训练一个监督奖励模型(通常使用另一个预训练LLM作为基本模型)。最后,再次通过使用奖励模型进行强化学习(PPO)对LLM(来自步骤1)进行微调,生成最终的回复。
- 因此,训练了两个LLM:一个用于奖励模型,另一个用于微调生成最终回复的LLM。在两种情况下,基本模型的参数可以选择性地更新,具体取决于回复的期望准确性。例如,在某些RLHF方法中,只更新与强化学习有关的特定层或组件中的参数,以避免过拟合并保留预训练LLM捕捉到的通用知识。
这个过程中的一个有趣的现象是,迄今为止成功的RLHF系统使用的奖励语言模型的大小与文本生成的大小相对应(例如OpenAI的175B LM,6B奖励模型,Anthropic使用从10B到52B的LM和奖励模型,DeepMind使用70B的Chinchilla模型作为LM和奖励)。直觉上,这些偏好模型需要具有与它们所给定的文本相同的理解能力,就像一个模型需要生成所述文本一样。
还有一种名为RLAIF(带有AI反馈的强化学习)的方法,可以用来替代RLHF。这里的主要区别是,不是使用人类反馈,而是使用AI模型作为评估器或评论家,在强化学习过程中为AI agent提供反馈。
结论
企业可以利用定制LLM的非凡潜力,以实现与其特定领域、用例和组织需求相一致的出色定制化、控制和准确性。构建企业特定的定制LLM赋予企业解锁多样化的定制机会,完全适应其独特的需求、行业动态和客户群体。
构建自己的定制LLM的过程有三个级别,从模型复杂性、准确性和成本低到模型复杂性、准确性和成本高。企业必须在这个权衡中找到平衡,以最好地满足自己的需求,并从LLM计划中获得投资回报。

参考资料
- 什么是提示工程?
- 上下文学习(ICL)- Q. Dong, L. Li, D. Dai, C. Zheng, Z. Wu, B. Chang, X. Sun, J. Xu, L. Li, and Z. Sui, “A survey for in-context learning,” CoRR, vol. abs/2301.00234, 2023.
- 上下文学习是如何工作的?用于理解其与传统监督学习的差异的框架 | SAIL博客(stanford.edu)
- 思路链引导 – J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. H. Chi, Q. Le, and D. Zhou, “Chain of thought prompting elicits reasoning in large language models,” CoRR, vol. abs/2201.11903, 2022.
- 语言模型通过思路链进行推理- Google AI博客(googleblog.com)
- 指令调谐- J. Wei, M. Bosma, V. Y. Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, and Q. V. Le, “Fine-tuned language models are zero-shot learners,” in The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25–29, 2022. OpenReview.net, 2022.
- 大型语言模型调研- Wayne Xin Zhao, Kun Zhou*, Junyi Li*, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie and Ji-Rong Wen, arXiv:2303.18223v4 [cs.CL], April 12, 2023





