将像素转化为描述性标签:使用TensorFlow掌握多类图像分类
使用TensorFlow实现多类图像分类:将像素转化为描述性标签
构建能够看到和理解视觉世界的智能系统

在当今以视觉为驱动的数字化时代,准确分类图像的能力比以往任何时候都更加重要。无论您从事医疗、电子商务、自动驾驶车辆或任何其他涉及视觉数据的领域,理解像素语言都是至关重要的,掌握图像分类的艺术可以让您具备竞争优势。
那么,您准备好踏上一个像素蓝图的冒险之旅,揭示图像的秘密了吗?不用再找了!在本博文中,我们将揭示多类别图像分类的复杂性,并通过涵盖数据准备、模型创建和评估的基本概念,赋予您创建感知周围世界的智能系统的能力。最后,您将对如何使用TensorFlow构建强大的图像分类模型有着坚实的理解。
训练自定义图像分类模型涉及几个步骤,我将把这个概念结构化为以下几个部分。
理解多类别图像分类数据准备构建卷积神经网络(CNN)模型使用图像分类模型进行预测
所以,让我们言之有物,毫不犹豫地投入这个迷人的旅程。
第一部分:图像分类到底是什么?
图像分类是计算机视觉中的一项基本任务,通过将图像分类为预定义的类别或标签,告诉我们图像的内容是什么。
图像分类的机器学习模型模仿了人脑的认知能力。
在图像分类方面,通常的过程是使用一个带有不同类别或标签的数据集来教授机器学习模型(想象一下著名的猫和狗)。通过一系列数学计算,模型可以从图像中提取重要特征,并将它们与相应的标签关联起来。最终的目标是利用这些训练过的模型,根据图像的视觉属性有效地识别并分配准确的标签给未见过的图像。
多类别图像分类是什么?
与二元分类不同,二元分类仅涉及区分两个类别(0或1),多类别分类涉及同时识别多个类别。例如,在一个多类别分类任务中,对动物进行分类,我们可能有“狗”、“猫”、“鸟”和“马”等类别。

提供的快照展示了CIFAR-10数据集,它包含101个食品类别,每个类别包含1000张图像,总共有101,000张图像。该数据集涵盖了各种菜系的各种食物,包括水果、蔬菜、甜点和菜肴。该数据集被广泛认可为评估多类别图像分类模型有效性的基准。现在,我们已经探索了数据集,让我们继续我们的旅程的下一节:数据准备。
第二部分:与数据亲密接触
在本节中,我们将专注于使用Food-101数据集进行数据准备,这是一个包含食物图像的综合性集合。虽然Food-101数据集包含101个食物类别和101,000张图像,但我们将通过选择五个食物类别来简化我们的方法,以便创建一个更易管理的模型并节省计算时间。
首先,我们将下载 Food-101 数据集并将其组织成结构化的文件夹层次结构。在根目录下创建一个名为 data 的文件夹,并在其中放置图像文件夹,如下所示👇
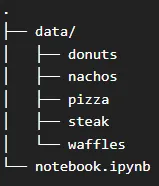
这种组织方式有助于高效处理数据,并在训练和评估阶段轻松访问数据。
接下来,利用 TensorFlow 的 tf.data 模块,我们将构建一个数据管道,无缝地从数据集中流式传输食物图像。我们将使用 Keras 的 image_dataset_from_directory API,它可以根据包含图像文件的目录结构创建一个 TensorFlow tf.data.Dataset。它会根据子目录的名称自动生成带有标签的数据集,从而不需要显式地分配标签。每个子目录中的图像文件与其对应的标签相关联。它还提供了批量大小、图像大小、洗牌和数据增强等参数的配置选项。让我们编写代码。
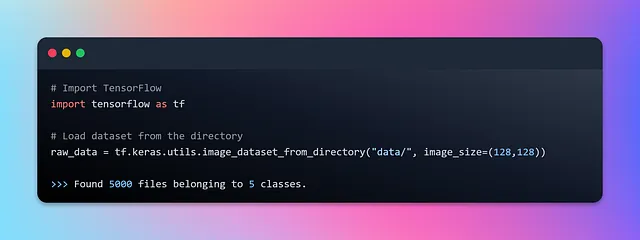
现在,是时候深入了解原始数据集,了解此 API 如何转换图像和标签,以及如何构建批次。默认情况下,该 API 每次处理 32 组图像。此外,图像将被调整为大小为 (256, 256)。然而,建议将安全尺寸作为最小尺寸,以确保所有图像均满足或超过该尺寸。
让我们来看看原始数据集。

这里的 raw_data 是一个批次数据集,其中的元素是包含两个组件的元组。批次数据集中的每个元素的第一个组件是一个张量,具有可变的批次大小(用 None 表示),高度和宽度为 128 像素,以及 3 个色彩通道(RGB)。批次数据集中每个元素的第二个组件是一个张量,其批次大小(用 None 表示)可变,表示标签。标签根据图像文件路径的字母数字顺序进行排序。让我们查看一个批次及其第一个元素,以深入了解。
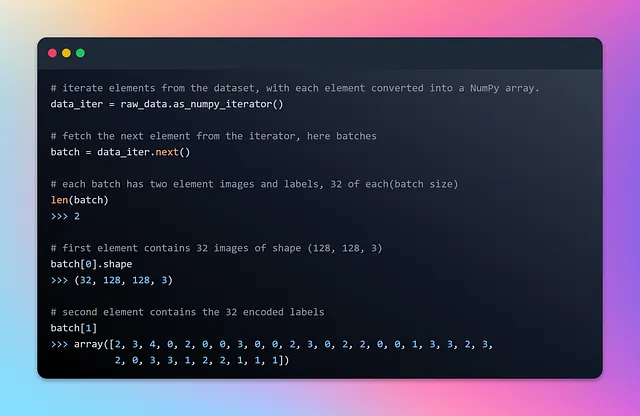
现在,我们已经对批次数据集在迭代过程中如何流式传输有了一些了解,是时候进行数据归一化并将数据集分割为训练集和测试集了。这种分割确保模型从一部分数据中学习,同时在未见过的食物图像上进行测试。这个评估过程可以评估模型对新食物项目的泛化能力,并准确评估其性能。
此预处理步骤将确保数据以适合馈入神经网络的格式呈现。
通过将每个图像数组除以 255,像素值被归一化到 0 到 1 的范围内。这种归一化通常用于确保像素值在类似的尺度上,从而使神经网络更容易从数据中学习。
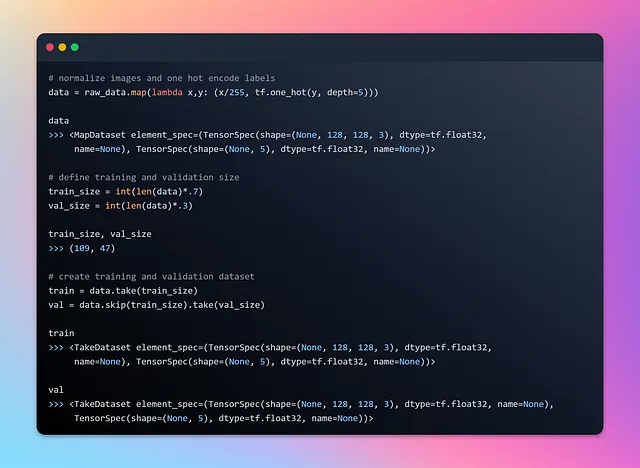
tf.one_hot() 函数用于创建独热编码,其中每个标签由长度等于 depth 参数(在本例中为 5)的二进制向量表示。独热编码通常用于多类分类问题,以便将分类标签以适合神经网络的格式表示。
数据创建过程完成后,我们现在已经准备好将训练集和验证集输入神经网络。所以,不再浪费时间,让我们直接进入下一节,从头开始构建我们的网络。
第三节:构建有效的卷积神经网络用于图像分类
准备好迎接一个激动人心的冒险吧,我们将探索使用卷积神经网络(CNN)构建分类网络的领域。无论您是一位经验丰富的专业人士,还是希望恢复对CNN的记忆的人,都不用担心!我会为您提供支持。在进入本节之前,我强烈推荐您查看我的关于CNN的入门博客,以便复习基础知识并了解CNN的强大之处。
理解卷积神经网络 🧠:初学者的架构之旅 🚀
什么是卷积神经网络(CNN)?
VoAGI.com
所以,让我们带着知识和信心,踏上这个令人兴奋的旅程,使用CNN创建出一个令人难以置信的分类网络!
我们开始吧 ⚡
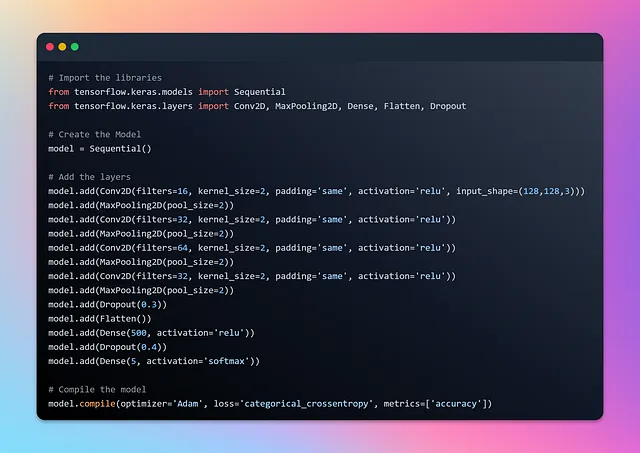
让我们查看模型概要并使用visualkeras进行可视化。
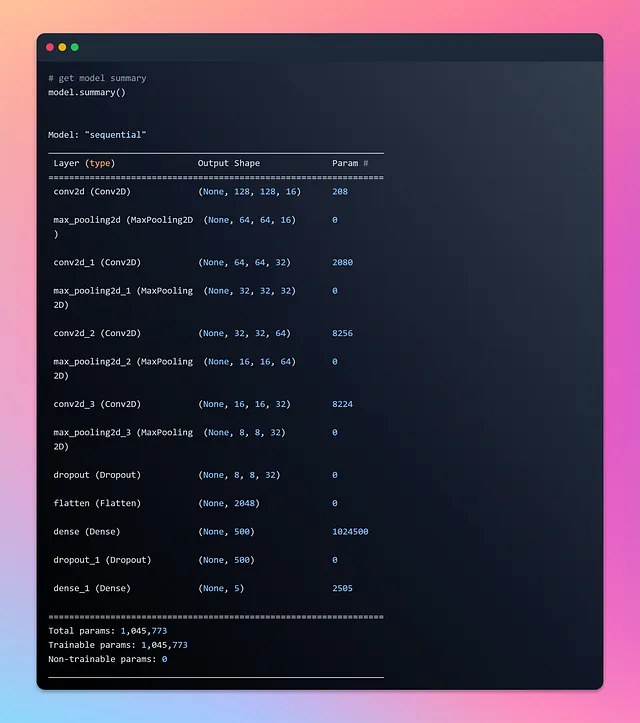
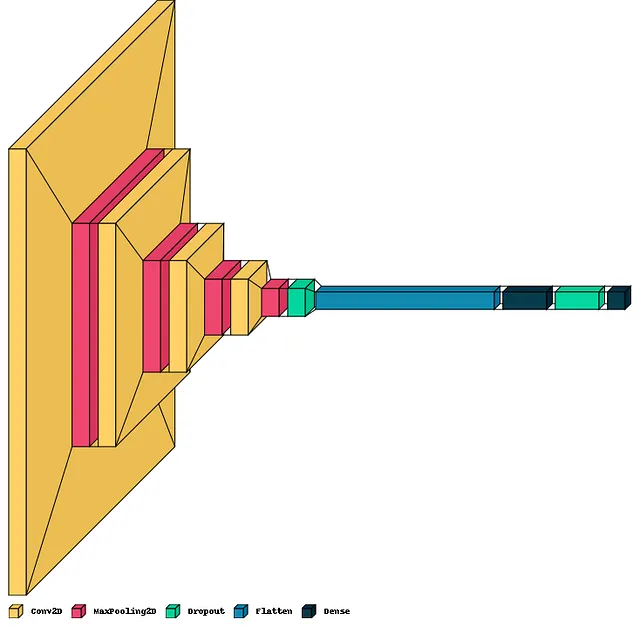
成功创建了我们的模型,现在是时候将之前一节精心准备的数据输入模型并开始训练了。为了跟踪训练进度,我们将把训练历史保存在一个名为“history”的变量中。使用TensorFlow数据集的美妙之处在于我们在训练过程中不需要显式地定义批次大小。数据集会在我们将数据输入模型进行训练时自动生成批次。
让我们为训练旅程做好准备,设定100个周期的训练目标。让我们拥抱自动批次生成的便利和效率,推动我们的模型训练。训练开始 🚀
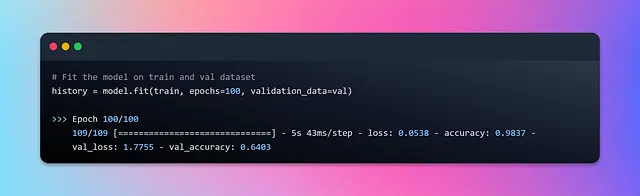
至此,我们的模型训练过程结束了。现在让我们使用训练历史绘制准确率和损失图表来可视化训练进展。
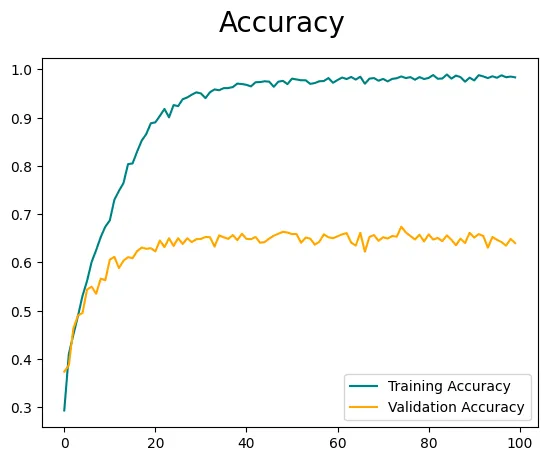
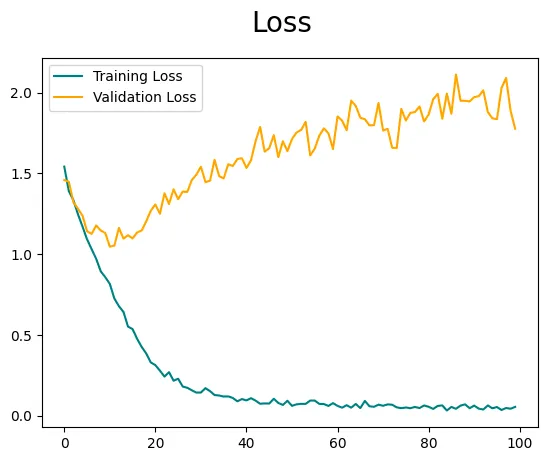
需要注意的是,准确度和损失可能不是最优的,因为我们直接将图像输入模型而没有使用特征工程或图像增强技术。为了进一步提高模型的性能,建议进行超参数调整,但这是另一个博客的话题。然而,如果你对探索和了解图像增强感兴趣,我已经在之前的博客中详细介绍了这个技术👇
升级🚀你的计算机视觉👀游戏:利用图像增强的潜力
通过变换提升性能和鲁棒性
ai.plainenglish.io
实施这些技术无疑会提升你的视觉模型的性能。
现在,是时候进入我们的最后一节,利用我们训练好的模型进行预测,揭示像素中隐藏的真实标签。
第4节:使用模型进行预测
在我们开始预测之旅之前,重要的是记住,我们输入模型的图像必须与神经网络的输入层大小相同。为了确保兼容性,我们将相应地调整图像的大小,然后进行预测。模型将生成一个概率数组,其中每个元素表示对应的独热编码标签的可能性。通过使用NumPy的argmax函数,我们可以提取对应于预测标签的索引。我将加载一张随机选择的美味披萨图片,并对我们训练好的模型进行测试。

准备好目睹调整大小、预测和揭示隐藏在像素中的标签的迷人过程吧!
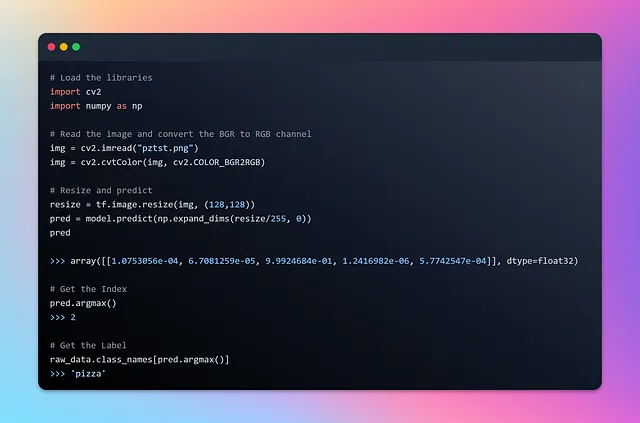
哇!我们的模型挥舞着魔杖,以百分之百的准确率揭示了图片的真实身份💯
我们做到了!我们成功地从头开始创建了一个用于多类别图像分类的自定义模型🎉
这是完整代码的链接📜
我们在这篇博客中的旅程现在圆满结束,但不要担心,在我们下一次的冒险中,我们将揭示其他引人入胜的计算机视觉问题的奥秘。在那之前,请继续探索和训练你自己的图像分类模型。再见👋,直到我们再次相遇!
希望你喜欢这篇文章!你可以关注我Afaque Umer,获取更多类似的文章。
我将尽力提出更多的机器学习/数据科学概念,并将试图将那些听起来高级的术语和概念解释为更简单的内容。