使用YOLOV8实现自动车牌识别
YOLOV8实现车牌识别
简介:
YOLO V8是由Ultralytics团队开发的最新模型。它是一种先进的YOLO模型,在准确性和效率方面超越了前任。
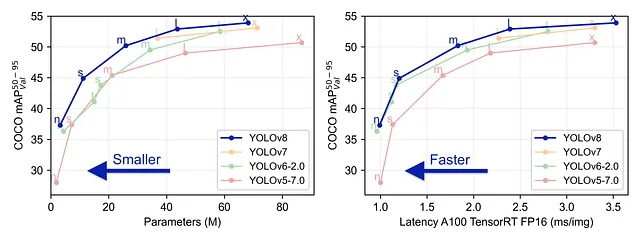
它易于使用,可以通过命令行或Python包进行访问。它提供了开箱即用的支持,用于目标检测、分类和分割任务。最近,它还添加了对目标跟踪的本地支持,因此我们不必再克隆跟踪算法的存储库。
在本文中,我将介绍如何利用YOLOV8构建一个自动车牌识别(ANPR)工具的步骤。让我们开始吧。
跟踪车辆:
正如我们之前提到的,YOLOV8具有本地跟踪功能,因此这一步骤非常简单。首先,安装ultralytics包
pip install ultralytics然后,我们需要使用open cv读取视频帧,并将模型的track方法应用于persist参数设置为True,以确保id在下一帧中保持不变。模型返回用于绘制边界框的坐标,以及id、标签和分数
import cv2from ultralytics import YOLOmodel = YOLO('yolov8n.pt')cap = cv2.VideoCapture("test_vids/vid1.mp4")ret = Truewhile ret: # 从摄像头读取一帧 ret, frame = cap.read() if ret and frame_nbr % 10 == 0 : results = model.track(frame,persist=True) for result in results[0].boxes.data.tolist(): x1, y1, x2, y2, id, score,label = result #检查是否满足阈值并且对象是一辆车 if score > 0.5 and label==2: cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 4) text_x = int(x1) text_y = int(y1) - 10 cv2.putText(frame, str(id), (text_x, text_y), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2) cropped_img = frame[int(y1):int(y2), int(x1):int(x2)]以下是一帧的结果:
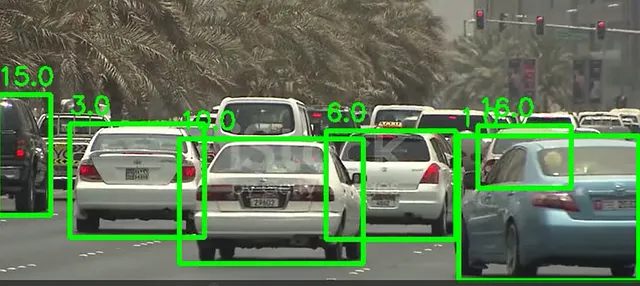
然后,使用边界框的坐标将帧中的每辆车裁剪成图像
车牌识别:
现在我们有了车辆,我们需要检测车牌,为此,我们需要训练Yolo模型。为此,我使用了以下Kaggle数据集。
车牌检测
433张车牌图片
www.kaggle.com
然而,该数据集中的标签是以PASCAL VOC XML格式提供的:
<annotation> <folder>images</folder> <filename>Cars105.png</filename> <size> <width>400</width> <height>240</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>licence</name> <pose>未指定</pose> <truncated>0</truncated> <occluded>0</occluded> <difficult>0</difficult> <bndbox> <xmin>152</xmin> <ymin>147</ymin> <xmax>206</xmax> <ymax>159</ymax> </bndbox> </object></annotation>YOLO需要使用以下格式的文件对每个图像进行注释:标签、中心x坐标、中心y坐标、宽度、高度
以下代码处理了我们数据的转换:
def xml_to_yolo(bbox, w, h): # xmin, ymin, xmax, ymax x_center = ((bbox[2] + bbox[0]) / 2) / w y_center = ((bbox[3] + bbox[1]) / 2) / h width = (bbox[2] - bbox[0]) / w height = (bbox[3] - bbox[1]) / h return [x_center, y_center, width, height]def convert_dataset(): for filename in os.listdir("annotations"): tree = ET.parse(f"annotations/{filename}") root = tree.getroot() name = root.find("filename").text.replace(".png", "") width = int(root.find("size").find("width").text) height = int(root.find("size").find("height").text) for obj in root.findall('object'): box = [] for x in obj.find("bndbox"): box.append(int(x.text)) yolo_box = xml_to_yolo(box, width, height) line = f"0 {yolo_box[0]} {yolo_box[1]} {yolo_box[2]} {yolo_box[3]}" with open(f"train/labels/{name}.txt", "a") as file: # 写入文件中的一行 file.write(f"{line}\n")现在,我们只需要设置配置yaml文件中的训练和验证数据文件夹的路径,然后训练模型(注意:训练和验证文件夹中的文件夹名称应为labels和images)。然后,将其作为参数传递给我们的模型实例并开始训练
path: C:/Users/msi/PycharmProjects/ANPR_Yolov8train: trainval: val# Classesnames: 0: license plate
model = YOLO('yolov8n.yaml')result = model.train(data="config.yaml",device="0",epochs=100,verbose=True,plots=True,save=True)
现在,我们已经拥有了车牌模型,我们只需要加载它并将其应用于视频中剪裁的汽车图像上,我们对车牌剪裁应用灰度处理,并使用easy_ocr读取其内容
cropped_img = frame[int(y1):int(y2), int(x1):int(x2)]plates = lp_detector(cropped_img)for plate in plates[0].boxes.data.tolist(): if score > 0.6: x1, y1, x2, y2, score, _ = plate cv2.rectangle(cropped_img, (int(x1), int(y1)), (int(x2), int(y2)), (255, 0, 0), 2) lp_crop = cropped_img[int(y1):int(y2), int(x1):int(x2)] lp_crop_gray = cv2.cvtColor(lp_crop, cv2.COLOR_BGR2GRAY) ocr_res = reader.readtext(lp_crop_gray) if not ocr_res: print("未检测到车牌") else: entry = {'id': id, 'number': ocr_res[0][1], 'score': ocr_res[0][2]} update_csv(entry) out.write(frame) cv2.imshow('frame', frame) frame_nbr += 1update_csv函数将车辆ID和车牌号码写入CSV文件中。这就是使用yolov8构建的ANPR流程
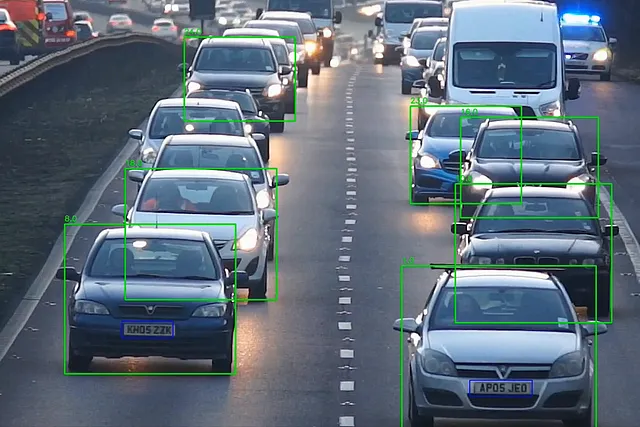
结论:
正如我们所看到的,YOLOV8简化了构建ANPR流程的过程,因为它提供了本地跟踪和目标检测功能。
此存储库包含我使用streamlit构建的完整ANPR应用程序的项目:
GitHub – skandermenzli/ANPR_Yolov8
通过在GitHub上创建一个帐户来为skandermenzli/ANPR_Yolov8项目做出贡献。
github.com






