这篇AI研究论文对于视觉定位和地图绘制的深度学习进行了全面调查
This AI research paper comprehensively investigates deep learning for visual localization and map generation.


如果我问你:“你现在在哪里?”或者“你周围的环境是什么样的?”由于人类具有多感知能力,你可以立即回答,这使你能够感知自己的运动和周围环境,确保你具有完整的空间意识。但是,如果同样的问题被提问给一个机器人,它会如何应对这个挑战呢?
问题在于,如果这个机器人没有地图,它就不知道自己在哪里,如果它不知道周围的环境是什么样的,它也无法创建地图。基本上,这是一个“先有鸡还是先有蛋”的问题,在机器学习领域中,也被称为定位和建图问题。
“定位”是获取与机器人的运动相关的内部系统信息的能力,包括其位置、方向和速度。另一方面,“建图”涉及感知外部环境条件的能力,包括周围环境的形状、视觉特征和语义属性。这些功能可以独立运行,一个专注于内部状态,另一个专注于外部条件,或者它们可以作为一个称为同时定位和建图(SLAM)的单一系统共同工作。
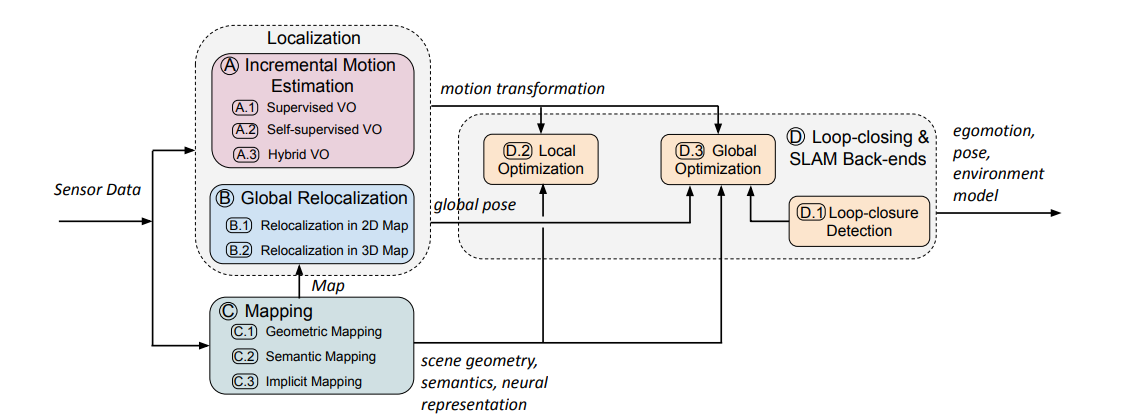
目前,像基于图像的重定位、视觉里程计和SLAM等算法存在的挑战包括不完美的传感器测量、动态场景、恶劣的光照条件和现实世界的约束,这些挑战在一定程度上阻碍了它们的实际应用。上图演示了如何将各个模块集成到基于深度学习的SLAM系统中。这项研究全面调查了基于深度学习和传统方法的应用,并同时回答了两个重要问题:
- 深度学习在视觉定位和建图方面是否有前景?
研究人员认为,以下三个属性可能使深度学习成为未来通用SLAM系统的独特方向。
- 首先,深度学习提供了强大的感知工具,可以集成到视觉SLAM前端中,以提取在里程计估计或重定位方面具有挑战性的区域的特征,并为建图提供密集的深度信息。
- 其次,深度学习赋予机器人先进的理解和交互能力。神经网络擅长将抽象概念与人类可理解的术语连接起来,比如在建图或SLAM系统中标记场景语义,这通常是使用形式化数学方法难以描述的。
- 最后,学习方法允许SLAM系统或个别定位/建图算法从经验中学习,并主动利用新信息进行自我学习。
- 如何将深度学习应用于解决视觉定位和建图问题?
- 深度学习是对建模各个方面的SLAM和个别定位/建图算法的一种多功能工具。例如,它可以用于创建端到端的神经网络模型,直接从图像中估计姿态。在处理无特征区域、动态光照和运动模糊等具有挑战性的条件时,深度学习方法可能比传统建模方法更有优势。
- 深度学习被用于解决SLAM中的关联问题。通过将图像与地图连接起来,对像素进行语义标记,并从先前访问中识别相关场景,它有助于重定位、语义建图和闭环检测。
- 深度学习被用于自动发现与任务相关的特征。通过利用先前的知识,例如几何约束,可以为SLAM设置自学习框架,根据输入图像自动更新参数。
需要指出的是,深度学习技术依赖于大规模、准确标记的数据集来提取有意义的模式,但可能难以推广到陌生的环境。这些模型缺乏可解释性,通常作为黑盒子运行。此外,定位和建图系统可能计算密集,但高度可并行化,除非应用模型压缩技术。