“在线大规模推荐的双增强双塔模型”
独具魅力的双倍增强塔式模型:在线大规模推荐
深入探究美团的双塔检索模型
推荐系统是设计用来为用户提供个性化建议的算法。这些系统在各个领域都被应用于帮助用户发现相关的物品,例如产品(电商如亚马逊),其他用户(社交媒体如X、领英),内容(社交媒体如X、Instagram、Reddit),或者信息(新闻应用或社交媒体如X、Reddit,或像VoAGI和Quora这样的平台),这些都是基于用户的偏好、行为或上下文。推荐系统旨在通过提供个性化和有针对性的建议来增强用户体验,最终促进决策和参与。一般来说,推荐系统由检索实体(物品、用户、信息)和对检索实体进行排名两部分组成。

本文将讨论美团研究人员提出的“在线大规模推荐的双增强双塔模型”,这是一种增强版的流行的双塔模型,该模型在推荐系统中被广泛使用。
双塔模型
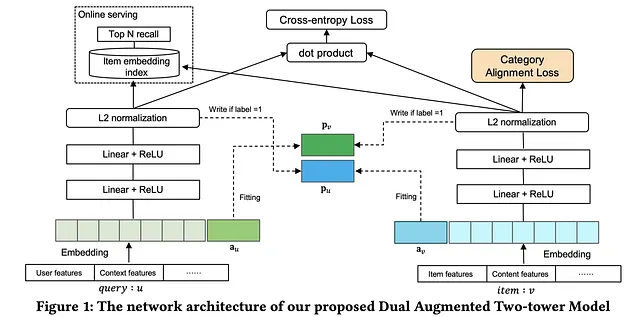
首先让我们讨论一下双塔模型。术语“双塔”源于架构中的两个分开的“塔”,每个实体一个。双塔模型旨在分别捕捉和学习两种不同实体的嵌入。这些实体可以是“用户”-“用户”、“用户”-“物品”或“搜索查询”-“物品”,具体取决于使用情况。该模型由两个塔和嵌入层组成,接着是一个交互层来捕捉它们的关系,然后是一个输出层用于生成推荐评分。
原始双塔模型的一个缺点是两个实体之间缺乏交互。除了最后的交互层之外,两个实体之间没有任何交互,这里使用它们各自的嵌入来计算类似余弦相似度的相似度度量。该论文通过引入一种新颖的自适应模仿机制解决了这个问题。该论文还提供了解决类别失衡问题的解决方案。在许多用例中,例如电商,某些类别可能有更多的物品和用户之间的交互,而某些类别可能有较少的物品和用户之间的交互。该论文引入了一种类别对齐损失来减轻类别失衡对生成的推荐结果的影响。下图展示了网络架构。
|  |
问题陈述
我们以“搜索查询”-“物品”用例为例。我们已经给定一组N个查询u_i (i = 1, 2, ..., N),一组M个物品v_j (j = 1, 2, ..., M),以及查询-物品反馈矩阵R。矩阵R是一个二进制矩阵,R_ij = 1表示对应的查询u_i和物品v_j之间存在正反馈,R_ij = 0表示否定反馈。我们的目标是根据用户提供的查询从大量物品的语料库中检索出一定数量的候选物品。
双增强双塔模型
双增强双塔(DAT)模型包含以下组件
- 嵌入层 — 类似于双塔模型,每个查询或物品特征被转换为其嵌入表示(通常是稀疏的)。这些特征可以是用户/物品特征、上下文/内容特征等。
- 双增强层 — 针对特定的查询和候选物品,创建它们的增强向量
a_u和a_v,并将其连接到各自的特征嵌入中。在训练和学习时,我们期望增强向量不仅包含当前查询和物品的信息,还包含它们历史上的正交互信息。下图显示了连接后的输入嵌入的示例。

- 前馈层 – 连接的嵌入
z_u和z_v通过前馈层传递;每个塔的输出是查询p_u和商品p_v的低维度表示。进行 L2 归一化,然后进行内积运算。模型的输出是s(u, v) = <p_u, p_v>。所得到的输出被认为是给定查询-商品对的分数。 - 自适应模仿机制(AMM) – 使用模仿损失训练增强向量
a_u和a_v。模仿损失的目的是使用增强向量来适应对应查询或商品的另一个塔中的所有正向交互。如果标签y = 1,a_v接近p_u,a_u接近p_v。在这种情况下,损失函数的目标是减小a_v和p_u、a_u和p_v之间的距离。如果标签y = 0,损失项等于 0。增强向量在一个塔中使用,而查询/商品嵌入是从另一个塔生成的。也就是说,增强向量总结了关于查询或商品从另一个塔中可能匹配的高层信息。由于模仿损失是用来更新a_u和a_v,我们应该保持p_u和p_v的值不变。

- 类别对齐 – 据作者称,双塔模型在不同类别上的表现不同。在商品数量相对较少的类别中,它的表现要差得多。为了解决这个问题,引入了类别对齐损失(CAL),将在具有大量数据的类别中学到的知识转移到其他类别中。对于每个批次,CAL 被定义为该批次中大多数类别商品的协方差矩阵
C(S^major)与该批次中其他类别商品的协方差矩阵C(S^i)之间的弗罗贝尼乌斯范数之和。该损失确保协方差(即二阶统计量)在所有类别之间保持一致。注意商品嵌入p_v用于计算协方差矩阵。

模型训练
将问题模型化为二元分类任务 – 检索到的商品是否相关。在训练期间,将元组 {u_i, v_j, R_ij=y} 输入模型。使用随机负采样框架创建训练批次。在训练期间,一个批次的输入包括一个正向查询-商品对 (标签 y = 1) 和 S 个随机采样的负向查询-商品对 (标签 y = 0)。这里使用交叉熵损失。

最终的损失函数如下所示 —

实施细节
使用三个完全连接的前馈层,将嵌入缩小为32维。这三个前馈层的维度分别为256、128和32。增强向量的维度也设定为32。作者在自己的美团数据集和公开可用的亚马逊图书数据集上进行了实验。

结果和评估
用于评估的指标包括HitRate@K和均值倒数秩 (MRR)。这里K被设定为50和100。由于测试实例的规模较大,作者通过一个因子为10的缩放对MRR进行了调整。
- HitRate@K — 一种衡量真正的正面推荐在前K个推荐中能够找到的比例的指标。
- 均值倒数秩 (MRR) — 通过计算第一个正确推荐的倒数秩的平均值得到的指标。
下表总结了DAT模型与矩阵分解模型、双塔模型和YouTubeDNN等其他模型的结果进行了比较。DAT表现最佳,展示了AMM和CAL的有效性。

作者对增强向量的维度进行了调整,并观察了性能的变化。您可以在下面的图表中观察到结果。

以上两个结果基于离线研究。作者观察了该模型在处理实际流量时的以下指标,流量涉及6000万用户,持续一周。
- 点击率 (CTR) — 衡量点击了物品的用户的百分比,表明吸引人内容的有效性。
- 总商品价值 (GMV) — 表示通过平台销售的商品或服务的总价值。
这里原始的双塔模型被视为基准。两个模型都检索了100个候选项。使用近似最近邻搜索来执行候选项的检索。检索到的项被输入到相同的排序算法中进行公平比较。DAT模型优于基准模型,CTR和GMV的平均改善率分别达到4.17%和3.46%。

综上所述,双增强双塔模型旨在促进塔间深度交互,并生成更好的不平衡类别数据展示和排序表示,从而改善HitRate@K和MRR等检索指标,以及CTR和GMV等排序指标。
希望你觉得这篇文章有启发。这是原始论文的链接 – 《一个用于在线大规模推荐的双增强双塔模型(dlp-kdd.github.io)》。
谢谢你的阅读!






