大规模近似去重背后的BigCode
The essence of BigCode behind large-scale approximate deduplication.
目标受众
对大规模文档级别近似去重感兴趣,并对哈希、图形和文本处理有一定了解的人。
动机
在将数据输入模型之前,至少在我们的情况下,即使是大型语言模型,我们也需要注意我们的数据,正如古语所说,垃圾进,垃圾出。尽管随着抢眼的模型(或者我们应该说API)越来越难做到这一点,导致数据质量变得不那么重要。
在BigScience和BigCode中,我们面临的一个问题是数据质量的重复,包括可能的基准污染。已经显示当存在许多重复时,模型倾向于完全输出训练数据[1](尽管在其他领域中不太清楚[2]),这也使得模型容易受到隐私攻击[1]。此外,去重的一些典型优势还包括:
- 高效训练:您可以通过更少的训练步骤获得相同甚至更好的性能[3][4]。
- 防止可能的数据泄漏和基准污染:非零重复会使您的评估受到质疑,并有可能使所谓的改进成为虚假的声明。
- 可访问性:我们中的大多数人无法频繁下载或传输数千千字节的文本,更不用说用它来训练模型了。对于具有固定大小的数据集,去重使研究、传输和协作更加容易。
从BigScience到BigCode
首先,让我分享一个关于我如何加入这个近似去重任务的故事,进展如何,以及我在此过程中学到了什么。
- Hugging Face 和 IBM 在 watsonx.ai 上合作,这是下一代的 AI 构建工作室
- Hugging Face与微软合作,在Azure上推出Hugging Face模型目录
- 使用bitsandbytes、4位量化和QLoRA使LLMs更加易于访问
一切都始于LinkedIn上的一次对话,当时BigScience已经进行了几个月。Huu Nguyen在注意到我的GitHub上的个人项目后,向我提出是否有兴趣为BigScience工作的去重工作。当然,我的回答是肯定的,我完全不知道由于数据量庞大而需要付出多少努力。
这既有趣又具有挑战性。从某种意义上说,这是一种具有挑战性的工作,因为我对如此庞大的数据规模并不具备太多的研究经验,而每个人仍然欢迎并信任您使用数千美元的云计算预算。是的,我不得不在睡觉时醒来几次,以确保我已经关闭了那些机器。因此,我不得不通过所有的尝试和错误来学习工作,最终使我对事物有了新的视角,我认为如果不是因为BigScience,我可能永远都不会有这种视角。
一年后,我将所学的知识应用到BigCode中,处理更大的数据集。除了为英语训练的LLMs[3],我们还确认去重也可以改善代码模型[4],而且使用的数据集要小得多。现在,我将所学的知识与你们分享,亲爱的读者,希望你也能透过去重的视角对BigCode的幕后情况有所了解。
如果你感兴趣,这是我们在BigScience开始的去重比较的更新版本:
这也适用于我们为BigCode创建的代码数据集。当数据集名称不可用时,使用模型名称。
MinHash + LSH参数( P , T , K , B , R ):
- P P P 排列/哈希的数量
- T T T Jaccard相似性阈值
- K K K n-gram/shingle大小
- B B B 带数
- R R R 行数
要了解这些参数可能如何影响您的结果,这里有一个简单的演示,以数学方式说明计算过程:MinHash Math Demo。
MinHash步骤
在本节中,我们将介绍MinHash的每个步骤,它是BigCode中使用的方法,以及潜在的扩展问题和解决方案。我们将通过一个包含三个英文文档的示例演示工作流程:
MinHash的典型工作流程如下:
- 带状(标记化)和指纹化(MinHashing),其中我们将每个文档映射到一组哈希值。
- 局部敏感哈希(LSH)。该步骤是通过将具有相似带的文档分组来减少比较的数量。
- 去重。在这一步中,我们决定保留或删除哪些重复的文档。
Shingles
与大多数涉及文本的应用程序一样,我们需要从标记化开始。N-gram,即shingle,经常被使用。在我们的示例中,我们将使用词级的三元组,不包含任何标点符号。我们将在后面的部分讨论ngrams的大小对性能的影响。
这个操作的时间复杂度为O ( N M ),其中N是文档的数量,M是文档的长度。换句话说,它与数据集的大小成线性关系。这个步骤可以通过多进程或分布式计算轻松扩展。
指纹计算
在MinHash中,每个shingle通常会通过不同的哈希函数多次哈希,或者使用一个哈希函数多次排列。在这里,我们选择将每个哈希值排列5次。MinHash的更多变体可以在MinHash – Wikipedia中找到。
在每个文档内,取每列的最小值 —— “MinHash” 中的 “Min” 部分,我们就得到了这个文档的最终MinHash:
从技术上讲,我们不必使用每列的最小值,但最小值是最常见的选择。也可以使用其他顺序统计量,如最大值、第k小值或第k大值 [21]。
在实现中,您可以使用numpy轻松向量化这些步骤,并期望具有O ( N M K )的时间复杂度,其中K是您的排列数。代码基于Datasketch进行了修改。
def embed_func(
content: str,
idx: int,
*,
num_perm: int,
ngram_size: int,
hashranges: List[Tuple[int, int]],
permutations: np.ndarray,
) -> Dict[str, Any]:
a, b = permutations
masks: np.ndarray = np.full(shape=num_perm, dtype=np.uint64, fill_value=MAX_HASH)
tokens: Set[str] = {" ".join(t) for t in ngrams(NON_ALPHA.split(content), ngram_size)}
hashvalues: np.ndarray = np.array([sha1_hash(token.encode("utf-8")) for token in tokens], dtype=np.uint64)
permuted_hashvalues = np.bitwise_and(
((hashvalues * np.tile(a, (len(hashvalues), 1)).T).T + b) % MERSENNE_PRIME, MAX_HASH
)
hashvalues = np.vstack([permuted_hashvalues, masks]).min(axis=0)
Hs = [bytes(hashvalues[start:end].byteswap().data) for start, end in hashranges]
return {"__signatures__": Hs, "__id__": idx}如果您熟悉Datasketch,您可能会问,为什么我们要剥离库提供的所有好用的高级函数?这不是因为我们想避免添加依赖,而是因为我们打算在并行化过程中尽可能多地利用CPU计算资源。将几个步骤合并为一个函数调用可以更好地利用计算资源。
由于一个文档的计算不依赖于其他任何东西,一个好的并行化选择是使用datasets库的map函数:
embedded = ds.map(
function=embed_func,
fn_kwargs={
"num_perm": args.num_perm,
"hashranges": HASH_RANGES,
"ngram_size": args.ngram,
"permutations": PERMUTATIONS,
},
input_columns=[args.column],
remove_columns=ds.column_names,
num_proc=os.cpu_count(),
with_indices=True,
desc="Fingerprinting...",
)指纹计算完成后,一个特定的文档被映射到一个整数值数组。为了找出哪些文档彼此相似,我们需要根据这些指纹对它们进行分组。进入阶段,局部敏感哈希(LSH)。
局部敏感哈希
LSH将指纹数组分成带有相同行数的带,如果有任何剩余的哈希值,将被忽略。让我们使用b = 2个带和r = 2个行来分组这些文档:
如果两个文档在特定位置(带索引)的一个带中具有相同的哈希值,它们将被聚类到同一个桶中,并被视为候选项。
对于doc_ids列中的每一行,我们可以通过将其两两配对来生成候选对。从上表中,我们可以生成一个候选对:(0, 1)。
超越重复对
这是许多论文或教程中的去重描述的终点。我们仍然面临着如何处理它们的问题。一般来说,我们可以采取两种选择:
- 通过计算它们的shingle重叠来检查它们的实际Jaccard相似度,由于MinHash的估计性质。两个集合的Jaccard相似度被定义为交集的大小除以并集的大小。现在,这比计算所有对之间的相似度更容易,因为我们只需关注聚类内的文档。这也是我们最初在BigCode中所做的,效果还不错。
- 将它们视为真正的正例。你可能已经注意到这里的问题:Jaccard相似度不是传递的,这意味着A A A与B B B相似,B B B与C C C相似,但A A A与C C C不一定共享相似性。然而,我们从The Stack的实验结果表明,将它们全部视为重复项可以最大程度地提高下游模型的性能。现在,我们逐渐转向这种方法,并且它还节省时间。但是,要将其应用于您的数据集,我们仍然建议您查看您的重复项,并做出基于数据的决策。
从这样的对中,无论它们是否经过验证,我们现在可以构建一个以这些对为边的图,重复项将被聚类到社区或连通分量中。在实现方面,不幸的是,datasets在这方面帮不上太多忙,因为现在我们需要像groupby这样的东西,可以根据它们的带偏移和带值对文档进行聚类。以下是我们尝试过的一些选项:
选项1:以传统的方式迭代数据集并收集边缘。然后使用图库进行社区检测或连通分量检测。
在我们的测试中,这种方法的扩展性不好,原因有很多。首先,迭代整个数据集在大规模情况下速度较慢且占用内存。其次,像graphtool或networkx这样的流行图库在图的创建方面有很多开销。
选项2:使用流行的Python框架,如dask,以允许更高效的groupby操作。
但是,您仍然会遇到迭代和图的创建速度缓慢的问题。
选项3:迭代数据集,但使用并查集数据结构来聚类文档。
这对迭代过程几乎没有额外开销,并且对VoAGI数据集效果相对较好。
for table in tqdm(HASH_TABLES, dynamic_ncols=True, desc="Clustering..."):
for cluster in table.values():
if len(cluster) <= 1:
continue
idx = min(cluster)
for x in cluster:
uf.union(x, idx)选项4:对于大型数据集,使用Spark。
我们已经知道LSH部分可以并行化,这在Spark中也是可行的。除此之外,Spark支持分布式的groupBy,并且实现像[18]这样的连通分量检测算法也很简单。如果您想知道为什么我们没有使用Spark的MinHash实现,答案是我们迄今为止的所有实验都源于Datasketch,它使用与Spark完全不同的实现,我们希望确保我们从中获得的经验教训和见解不会陷入另一个消融实验的坑中。
edges = (
records.flatMap(
lambda x: generate_hash_values(
content=x[1],
idx=x[0],
num_perm=args.num_perm,
ngram_size=args.ngram_size,
hashranges=HASH_RANGES,
permutations=PERMUTATIONS,
)
)
.groupBy(lambda x: (x[0], x[1]))
.flatMap(lambda x: generate_edges([i[2] for i in x[1]]))
.distinct()
.cache()
)基于[18]实现的Spark简单连通性组件算法。
a = edges
while True:
b = a.flatMap(large_star_map).groupByKey().flatMap(large_star_reduce).distinct().cache()
a = b.map(small_star_map).groupByKey().flatMap(small_star_reduce).distinct().cache()
changes = a.subtract(b).union(b.subtract(a)).collect()
if len(changes) == 0:
break
results = a.collect()此外,多亏了云服务提供商,我们可以像使用GCP DataProc这样的服务一样轻松设置Spark集群。最终,我们可以在预算为每小时15美元的情况下,在不到4小时的时间内舒适地运行程序来去重1.4 TB的数据。
质量至关重要
爬梯子并不能将我们送上月球。这就是为什么我们需要确保这是正确的方向,而且我们要正确使用它。
早期,我们的参数主要来自于CodeParrot实验,并且我们的消融实验表明这些设置确实改善了模型的下游性能[16]。然后我们继续探索这条路,并确认了以下内容[4]:
- 近去重可以改善模型在较小数据集(6 TB VS. 3 TB)上的下游性能
- 我们还没有找到限制,但更激进的去重(6 TB VS. 2.4 TB)可以进一步提高性能:
- 降低相似度阈值
- 增加碎片大小(unigram → 5-gram)
- 放弃误报检查,因为我们可以承担失去小部分误报的风险
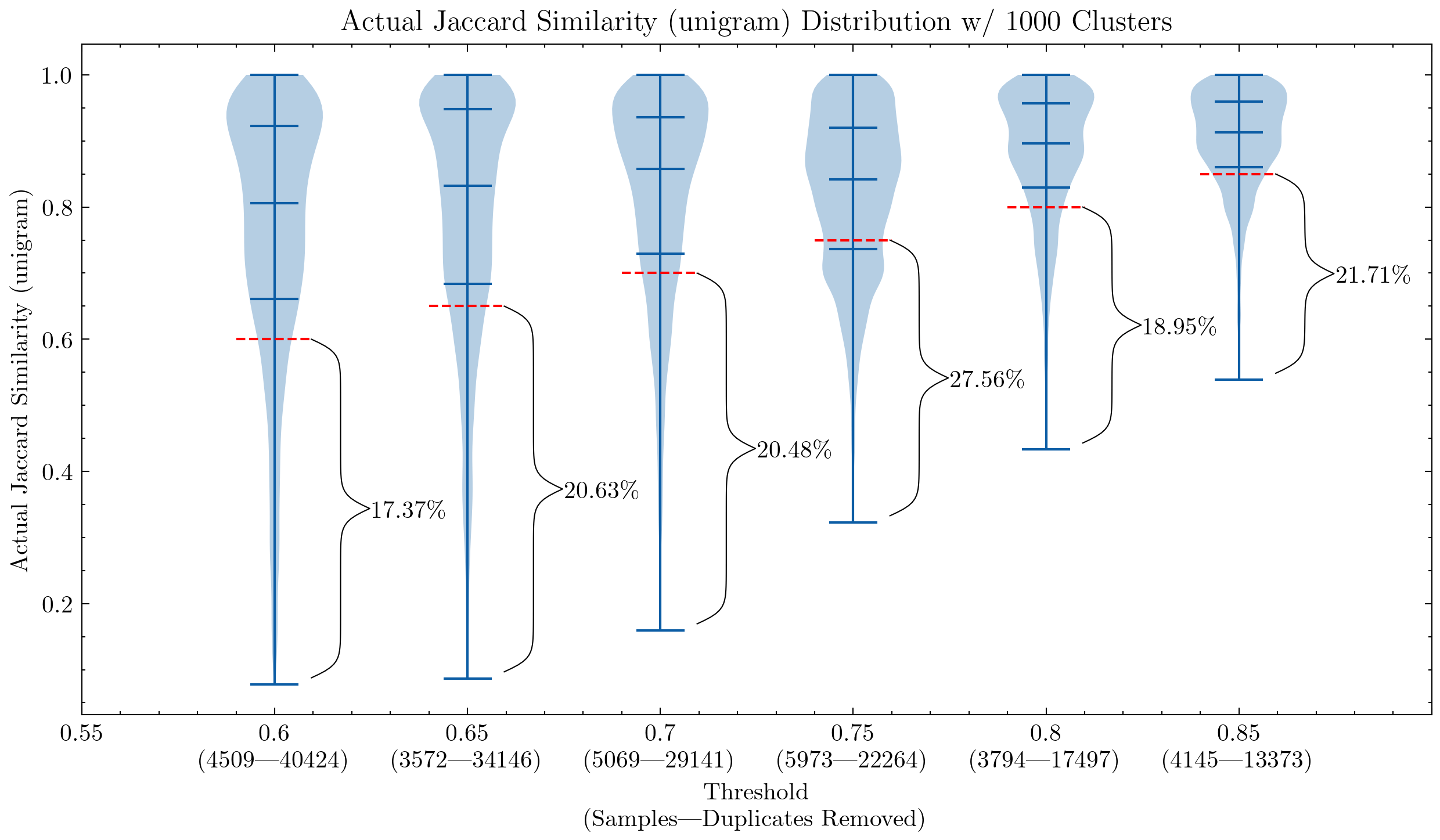
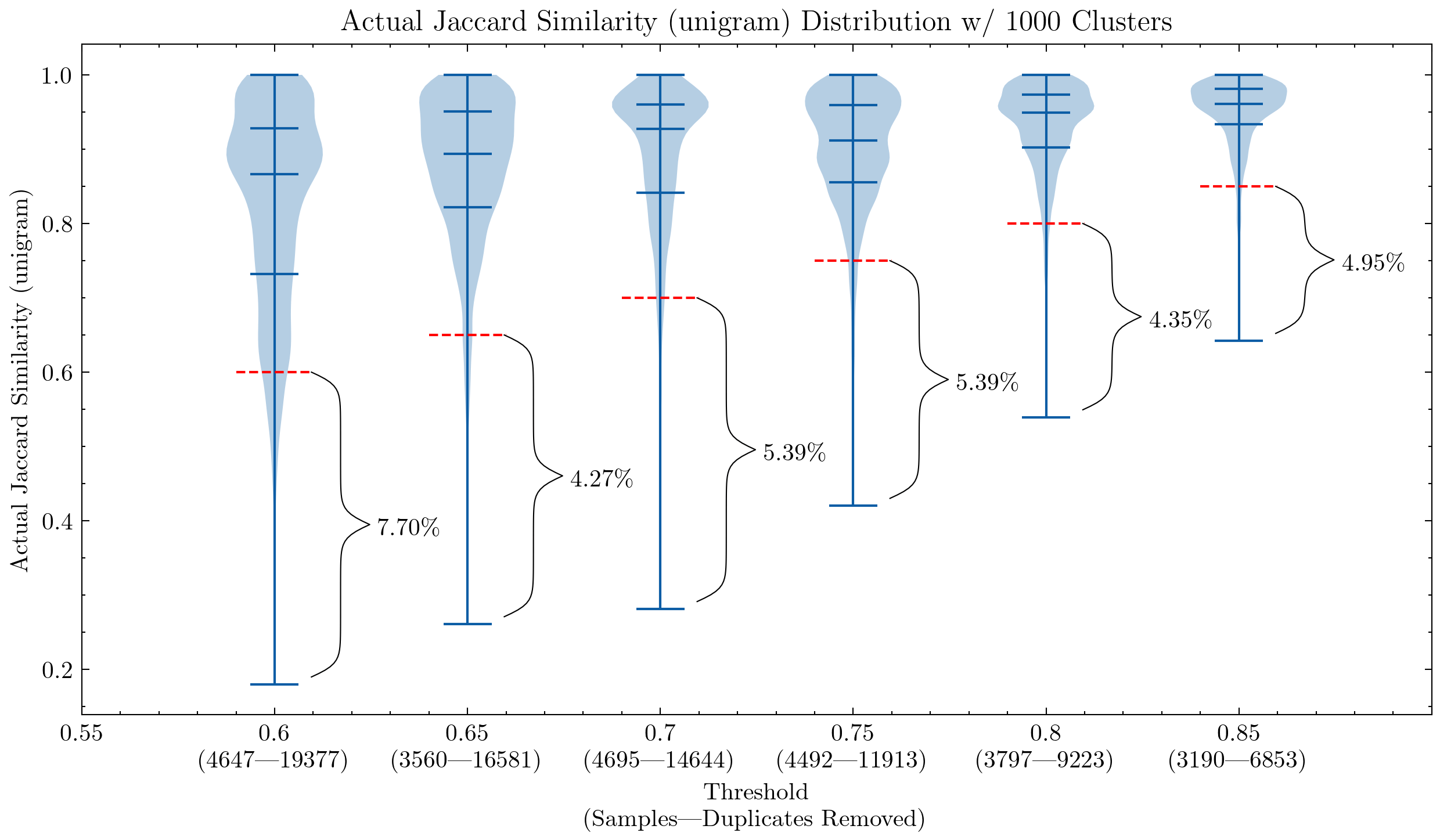
图像:两个图表显示相似度阈值和碎片大小的影响,第一个使用unigram,第二个使用5-gram。红色虚线表示相似性截断点:任何低于该阈值的文档都被视为误报 —— 它们与簇内其他文档的相似度低于阈值。
这些图表可以帮助我们理解为什么有必要对CodeParrot和Stack的误报进行二次检查:使用unigram会产生许多误报;它们还表明,通过将碎片大小增加到5-gram,误报的百分比显著减少。如果我们希望保持去重的激进程度,可以使用较小的阈值。
额外的实验还显示,降低阈值可以去除更多具有高相似度对的文档,这意味着在我们真正希望去除最多的部分中增加了召回率。
扩展
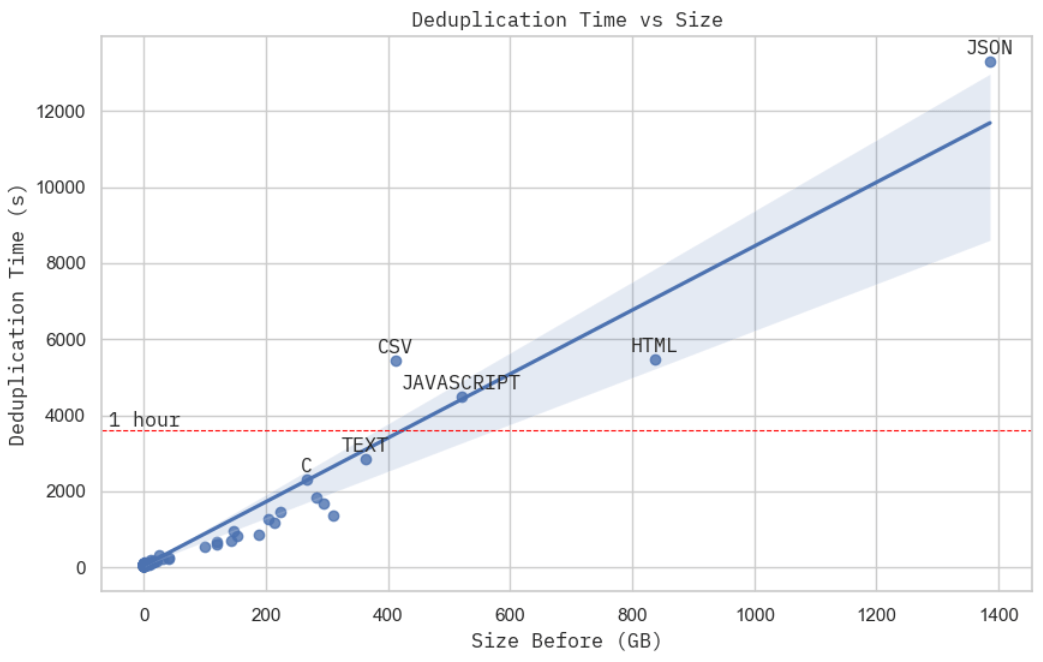
图像:去重时间与原始数据集大小的关系。这是在GCP上使用15个worker c2d-standard-16机器实现的,每个机器每小时的成本约为0.7美元。

图像:处理JSON数据集期间集群的CPU使用情况截图。
这并不是您可以找到的最严格的扩展证明,但是在给定固定计算预算的情况下,去重时间与数据集的物理大小几乎呈线性关系。当您仔细观察在处理JSON数据集(Stack中最大的子集)时,集群资源的使用情况时,您会发现MinHash + LSH(阶段2)占据了总实际计算时间(阶段2 + 3),而根据我们之前的分析,这是O(NM)的 —— 与数据集的物理容量成线性关系。
谨慎进行
去重并不能免除对数据进行彻底探索和分析的必要性。此外,这些去重发现只适用于Stack,但并不意味着它可以直接应用于其他数据集或语言。这是构建更好数据集的第一步,并且仍然需要进一步调查,例如数据质量过滤(例如漏洞、有害性、偏见、生成的模板、PII)。
我们仍然鼓励您在训练之前对数据集进行类似的分析。例如,如果您的时间和计算预算有限,去重可能并不是很有帮助:@geiping_2022提到子串去重并没有提高他们模型的下游性能。在使用现有数据集之前,可能还需要进行深入的检查,例如,@gao_2020表示他们只确保了Pile本身及其拆分进行了去重,对于任何下游基准测试,他们不会主动进行去重,而是把该决定留给读者。
在数据泄漏和基准污染方面,还有很多需要探索的问题。我们不得不重新训练我们的代码模型,因为HumanEval是在一个GitHub存储库中以Python形式发布的。早期的近似去重结果还表明,MBPP [19],作为最受欢迎的编码基准之一,与许多Leetcode问题非常相似(例如,MBPP的任务601基本上是Leetcode 646,任务604≃Leetcode 151)。我们都知道GitHub上有很多这些编码挑战和解决方案。如果有人带着不良意图以Python脚本或其他不太明显的方式上传所有基准,并污染您的训练数据,那将会更加困难。
未来方向
- 子串去重。尽管它对英文显示出了一些好处[3],但目前还不清楚是否应将其应用于代码数据;
- 重复:在一个文档中多次重复的段落。@rae_2021分享了一些有趣的启发式方法来检测和删除它们。
- 使用模型嵌入进行语义去重。这是一个完整的研究问题,涉及到扩展、成本、消融实验以及与近似去重的权衡。这方面有一些有趣的观点[20],但我们仍需要更多具体的证据来得出结论(例如,@abbas_2023的唯一文本去重参考是@lee_2022a,其主要观点是去重有助于而不是尽力成为SOTA)。
- 优化。优化的空间总是存在的:更好的质量评估、扩展、下游性能影响分析等。
- 还有另一个方向需要考虑的问题:近似去重在何种程度上开始影响性能?在多大程度上,相似性需要作为多样性而不是冗余来考虑?
致谢
横幅图像中包含了来自Noto Emoji(Apache 2.0)的表情符号(拥抱、圣诞老人、文件、巫师和魔杖)。这篇博文是在没有使用任何生成性API的情况下自豪地撰写的。
特别感谢Huu Nguyen @Huu和Hugo Laurençon @HugoLaurencon在BigScience的合作,以及BigCode的所有人在这个过程中的帮助!如果您发现任何错误,请随时与我联系:mouchenghao at gmail dot com。
支持资源
- Datasketch(MIT)
- simhash-py和simhash-cpp(MIT)
- 数据去重使语言模型更好(Apache 2.0)
- Gaoya(MIT)
- BigScience(Apache 2.0)
- BigCode(Apache 2.0)
参考文献
- [1]:Nikhil Kandpal,Eric Wallace,Colin Raffel,Deduplicating Training Data Mitigates Privacy Risks in Language Models,2022
- [2]:Gowthami Somepalli等人,Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models,2022
- [3]:Katherine Lee,Daphne Ippolito等人,Deduplicating Training Data Makes Language Models Better,2022
- [4]:Loubna Ben Allal,Raymond Li等人,SantaCoder: Don’t reach for the stars!,2023
- [5]:Leo Gao,Stella Biderman等人,The Pile: An 800GB Dataset of Diverse Text for Language Modeling,2020
- [6]:Asier Gutiérrez-Fandiño,Jordi Armengol-Estapé等人,MarIA: Spanish Language Models,2022
- [7]:Jack W. Rae,Sebastian Borgeaud等人,Scaling Language Models: Methods, Analysis & Insights from Training Gopher,2021
- [8]:Xi Victoria Lin,Todor Mihaylov等人,Few-shot Learning with Multilingual Language Models,2021
- [9]:Hugo Laurençon,Lucile Saulnier等人,The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset,2022
- [10]:Daniel Fried,Armen Aghajanyan等人,InCoder: A Generative Model for Code Infilling and Synthesis,2022
- [11]:Erik Nijkamp,Bo Pang等人,CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis,2023
- [12]:Yujia Li,David Choi等人,Competition-Level Code Generation with AlphaCode,2022
- [13]:Frank F. Xu,Uri Alon等人,A Systematic Evaluation of Large Language Models of Code,2022
- [14]:Aakanksha Chowdhery,Sharan Narang等人,PaLM: Scaling Language Modeling with Pathways,2022
- [15]:Lewis Tunstall,Leandro von Werra,Thomas Wolf,Natural Language Processing with Transformers, Revised Edition,2022
- [16]:Denis Kocetkov,Raymond Li等人,The Stack: 3 TB of permissively licensed source code,2022
- [17]:Rocky | Project Hail Mary Wiki | Fandom
- [18]:Raimondas Kiveris,Silvio Lattanzi等人,Connected Components in MapReduce and Beyond,2014
- [19]:Jacob Austin,Augustus Odena等人,Program Synthesis with Large Language Models,2021
- [20]:Amro Abbas,Kushal Tirumala等人,SemDeDup: Data-efficient learning at web-scale through semantic deduplication,2023
- [21]:Edith Cohen,MinHash Sketches : A Brief Survey,2016






