猎鹰已经登陆了Hugging Face生态系统
The Falcon has landed in the Hugging Face ecosystem.
介绍
Falcon是由阿布扎比技术创新研究所创建的一系列最先进的语言模型,采用Apache 2.0许可发布。值得注意的是,Falcon-40B是第一个具有与许多当前闭源模型相媲美能力的“真正开放”模型。这对于从业人员、爱好者和行业来说是个极好的消息,因为它为许多令人兴奋的用例打开了大门。
在本博客中,我们将深入探讨Falcon模型:首先讨论它们的独特之处,然后展示如何使用Hugging Face生态系统的工具轻松构建在其之上(推断、量化、微调等)。
目录
- Falcon模型
- 演示
- 推断
- 评估
- 使用PEFT进行微调
- 结论
Falcon模型
Falcon系列由两个基础模型组成:Falcon-40B和它的小弟Falcon-7B。40B参数模型目前在Open LLM排行榜上名列前茅,而7B模型则是其权重类别中最佳的。
Falcon-40B需要约90GB的GPU内存,这是很多的,但仍然比Falcon表现更好的LLaMA-65B要少。另一方面,Falcon-7B只需要约15GB的内存,即使在消费级硬件上也可以进行推断和微调。(在本博客的后面部分,我们将讨论如何利用量化技术,使Falcon-40B即使在更便宜的GPU上也能够使用!)
TII还提供了模型的指令版本,Falcon-7B-Instruct和Falcon-40B-Instruct。这些实验性变体在指令和对话数据上进行了微调,因此更适合流行的助手式任务。如果您只是想快速使用这些模型,它们是您最好的选择。还可以根据社区构建的众多数据集构建自己的自定义指令版本,接下来将为您提供逐步教程!
Falcon-7B和Falcon-40B分别经过了1.5万亿和1万亿个令牌的训练,符合优化推断的现代模型。Falcon模型质量的关键因素是它们的训练数据,其中主要基于RefinedWeb(>80%)——一种基于CommonCrawl的新型大规模网络数据集。TII专注于扩大规模和提高网络数据质量,利用大规模去重和严格过滤来匹配其他语料库的质量,而不是收集零散的策划源。Falcon模型仍然包含一些精心策划的数据源(如来自Reddit的对话数据),但与GPT-3或PaLM等最先进的LLM相比要少得多。最棒的部分是什么?TII已经公开发布了RefinedWeb的6000亿个令牌提取版本,供社区在自己的LLM中使用!
Falcon模型的另一个有趣特点是它们使用的多查询注意力。传统的多头注意力方案每个头有一个查询、键和值;而多查询则是在所有头之间共享一个键和值。
这个技巧对预训练没有显著影响,但它极大地提高了推断的可扩展性:实际上,在自回归解码期间保持的K、V缓存现在明显更小(根据体系结构的具体情况降低了10-100倍),降低了内存成本,并实现了状态性等新的优化。
*基准版本的得分不可用,我们报告微调版本的得分。
您可以在此空间或下方嵌入的游乐场中轻松尝试Big Falcon模型(400亿参数!):
在幕后,这个游乐场使用Hugging Face的文本生成推断,这是一个可扩展的Rust、Python和gRPC服务器,用于快速高效的文本生成。它是HuggingChat的动力来源。
我们还构建了一个7B指令模型的Core ML版本,以下是它在M1 MacBook Pro上的运行情况:
视频:Falcon 7B Instruct在M1 MacBook Pro上运行,使用Core ML。
视频展示了一个轻量级的应用程序,利用Swift库进行重要工作:模型加载、标记化、输入准备、生成和解码。我们正在忙于构建这个库,以使开发人员能够在各种应用程序中集成强大的LLM,而无需重新发明轮子。它仍然有些粗糙,但我们迫不及待地想与您分享。与此同时,您可以从存储库下载Core ML权重并自行探索!
您可以使用熟悉的transformers API在自己的硬件上运行模型,但需要注意以下几点:
- 模型是使用bfloat16数据类型训练的,因此建议您使用相同的数据类型。这需要一个最新版本的CUDA,并且在现代显卡上效果最好。您也可以尝试使用float16进行推理,但请记住模型是使用bfloat16进行评估的。
- 您需要允许远程代码执行。这是因为模型使用了一种尚未包含在transformers中的新架构 – 相反,模型作者在存储库中提供了必要的代码。具体而言,如果您允许远程执行(以为例),将使用以下文件的代码:configuration_RW.py,modelling_RW.py。
在考虑了这些因素后,您可以使用transformers的pipeline API加载7B指令模型,如下所示:
from transformers import AutoTokenizer
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)然后,您可以使用以下代码运行文本生成:
sequences = pipeline(
"Write a poem about Valencia.",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")您可能会得到类似以下的结果:
瓦伦西亚,阳光之城
闪耀如星的城市
千种色彩的城市
夜晚被星星照亮
瓦伦西亚,我心中的城市
过去被保留在一个金色的盒子中Falcon 40B推理
由于其体积庞大,运行40B模型具有挑战性:它不适合具有80GB RAM的单个A100。以8位模式加载,可以在大约45GB RAM中运行,适用于A6000(48GB),但不适用于A100的40GB版本。以下是您应该这样做:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-40b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
load_in_8bit=True,
device_map="auto",
)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)然而,请注意,混合8位推理将使用torch.float16而不是torch.bfloat16,因此请确保充分测试结果。
如果您有多张显卡并安装了accelerate,您可以利用device_map="auto"自动分配模型层到各个显卡上。它甚至可以将一些层附加到CPU上,但这会影响推理速度。
还有可能使用最新版本的bitsandbytes,transformers和accelerate来使用4位加载。在这种情况下,40B模型需要约27GB RAM才能运行。不幸的是,这略微超过了3090或4090等显卡可用的内存,但足以在30或40GB显卡上运行。
文本生成推理
文本生成推理是Hugging Face开发的生产就绪推理容器,可实现大型语言模型的轻松部署。
其主要特点包括:
- 连续批处理
- 使用服务器发送事件(SSE)进行令牌流式处理
- 多GPU的张量并行处理加快推理速度
- 使用自定义CUDA内核进行优化的transformers代码
- 通过Prometheus和Open Telemetry进行生产就绪的日志记录、监控和跟踪
自v0.8.2版本开始,文本生成推理原生支持Falcon 7b和40b模型,无需依赖Transformers的“信任远程代码”功能,从而实现了严密的部署和安全审计。此外,Falcon实现还包括自定义的CUDA内核,可大幅降低端到端延迟。
文本生成推理现在已集成在Hugging Face的推理端点中。要部署Falcon模型,请转到模型页面,然后单击部署->推理端点小部件。
对于7B模型,我们建议您选择“GPU [VoAGI] – 1x Nvidia A10G”。
对于40B模型,您需要在“GPU [xlarge] – 1x Nvidia A100”上部署,并激活量化:高级配置->服务容器->Int-8量化。注意:您可能需要通过电子邮件向[email protected]申请配额升级。
评估
那么Falcon模型的表现如何呢?Falcon的作者将很快发布一份深入的评估报告,因此我们目前通过我们的开放LLM基准测试运行了基础模型和指导模型。此基准测试旨在衡量LLM的推理能力以及其在以下领域提供真实答案的能力:
- AI2推理挑战(ARC):小学科学多项选择题。
- HellaSwag:常识推理和日常事件。
- MMLU:57个学科(专业和学术)的多项选择题。
- TruthfulQA:测试模型将事实与对手选择的一组不正确的陈述分开的能力。
结果显示,40B的基础模型和指导模型非常强大,目前在LLM排行榜上排名第一和第二 🏆!
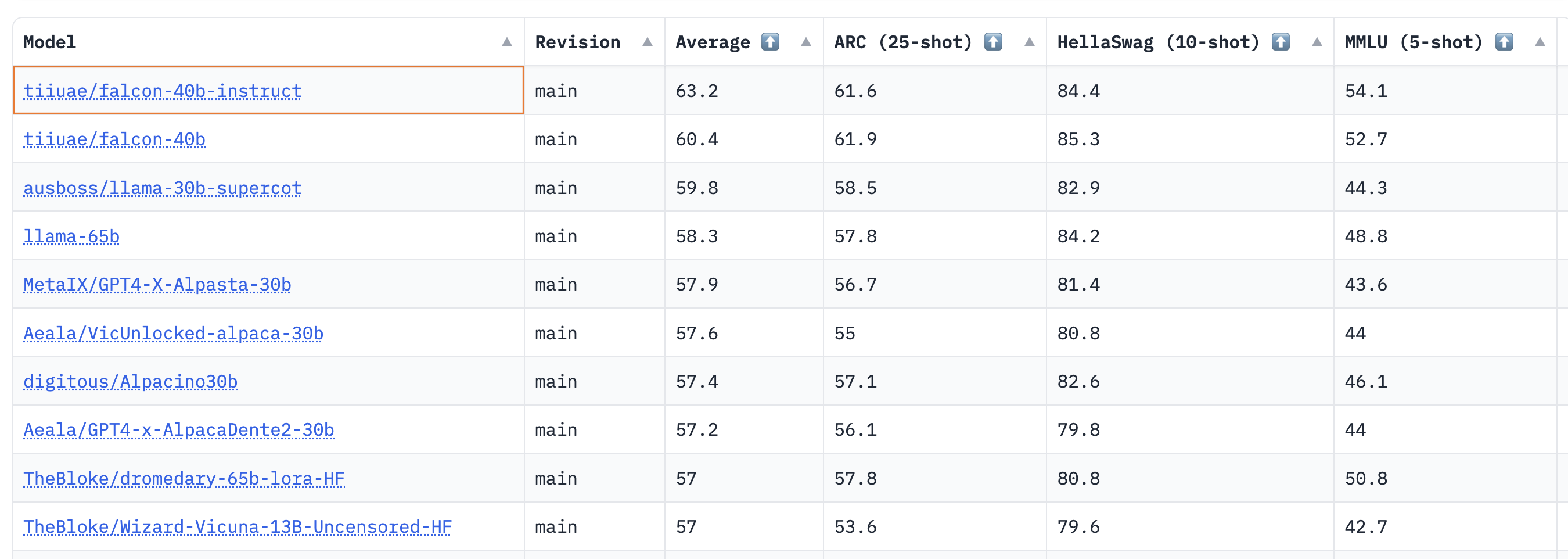
正如Thomas Wolf所指出的那样,一个令人惊讶的见解是,40B模型的预训练所需计算量约为LLaMa 65B的一半(2800 vs 6300 petaflop天),这表明我们还没有完全达到LLM预训练的“最优”限制。
对于7B模型,我们可以看到基础模型优于llama-7b,并超过MosaicML的mpt-7b,成为当前规模下最佳的预训练LLM。下面是排行榜上一些热门模型的简短列表,供比较参考:
尽管开放式LLM排行榜不测量聊天能力(人类评估是黄金标准),但Falcon模型的这些初步结果非常令人鼓舞!
现在让我们来看看如何对您自己的Falcon模型进行微调-也许您的模型将成为排行榜的榜首🤗。
使用PEFT进行微调
训练10B+规模的模型在技术和计算上都具有挑战性。在本部分中,我们将介绍Hugging Face生态系统中可用的工具,以便在简单的硬件上高效训练非常大的模型,并展示如何在单个NVIDIA T4(16GB- Google Colab)上对Falcon-7b进行微调。
让我们看看如何在Guanaco数据集上训练Falcon,这是Open Assistant数据集的高质量子集,包含约10,000个对话。借助PEFT库,我们可以使用最近的QLoRA方法对冻结的4位模型进行微调适配器。您可以在此博文中了解有关将4位量化模型集成到系统中的更多信息。
由于使用低秩适配器(LoRA)时,模型的可训练部分只是整个模型的一小部分,因此学习参数的数量和训练产物的大小都大大减小。如下图所示,保存的模型仅占用了7B参数模型的65MB(float16为15GB)。
更具体地说,在选择要适配的目标模块(通常是注意力模块的查询/键层)之后,将小的可训练线性层附加到这些模块附近,如下图所示。适配器生成的隐藏状态然后添加到原始状态以获取最终的隐藏状态。
训练完成后,无需保存整个模型,因为基础模型被保持冻结。此外,可以将模型保留在任意的dtype(int8、fp4、fp16等),只要这些模块的输出隐藏状态与适配器的输出隐藏状态进行类型转换-这对于返回与原始未量化模块相同dtype的隐藏状态的bitsandbytes模块(Linear8bitLt和Linear4bit)是成立的。
我们在Guanaco数据集上对Falcon模型的两个变体(7B和40B)进行了微调。我们在单个NVIDIA-T4 16GB上对7B模型进行了微调,并在单个NVIDIA A100 80GB上对40B模型进行了微调。我们使用了4位量化的基础模型和QLoRA方法,以及TRL库中最新的SFTTrainer。
要使用PEFT重现我们的实验的完整脚本在此处可用,但只需几行代码即可快速运行SFTTrainer(为简单起见,不使用PEFT):
from datasets import load_dataset
from trl import SFTTrainer
from transformers import AutoTokenizer, AutoModelForCausalLM
dataset = load_dataset("imdb", split="train")
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True)
trainer = SFTTrainer(
model,
tokenizer=tokenizer
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
trainer.train()有关评估训练模型的详细信息,请查看原始qlora存储库。
微调资源
- Colab笔记本,在Guanaco数据集上使用4位和PEFT微调Falcon-7B
- 训练代码
- 40B模型适配器(日志)
- 7B模型适配器(日志)
结论
Falcon是一个令人兴奋的新大型语言模型,可以用于商业应用。在这篇博文中,我们展示了它的能力,如何在自己的环境中运行它,并且在Hugging Face生态系统中如何轻松地对自定义数据进行微调。我们很期待看到社区将用它构建什么!